a[title]"),">"指定的筛选条件的标签
#html_text()只抓取<标签>内容中的内容部分
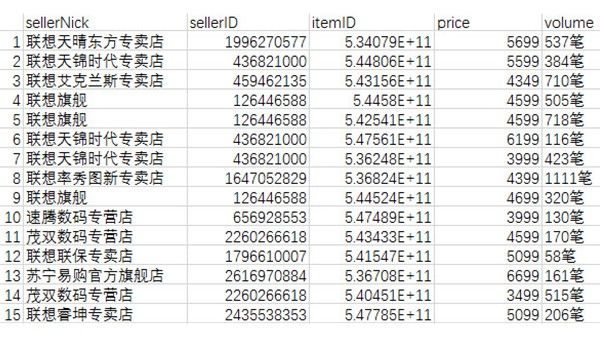
#抓取卖家店铺名称和ID
> SCdata <-gurl %>%
+ read_html(encoding="GBK")%>%#读取gurl的链接,并指定编码为gbk.
+ html_nodes("div.product-iWrap")#筛选出所有包含在...
块的内容
> #抓取卖家昵称和ID
> sellerNick<- SCdata %>% html_nodes("p.productStatus>span[class]") %>%
+ html_attr("data-nick")
> sellerID<- SCdata %>% html_nodes("p.productStatus>span[data-atp]") %>%
+ html_attr("data-atp") %>%
+ gsub(pattern="^.*,",replacement="")
> #抓取宝贝名称等数据
> itemTitle<- SCdata %>% html_nodes("productTitle>a[title]") %>%
+ html_attr("title")#暂时未能输出结果,先放下,后面再请教作者并尝试。
> itemID<- SCdata %>%html_nodes("p.productStatus>span[class]") %>%
+ html_attr("data-item")
> price<- SCdata %>% html_nodes("em[title]") %>%
+ html_attr("title") %>%
+ as.numeric
> volume<- SCdata %>% html_nodes("span>em") %>%
+ html_text
> #最后保存成数据框对象并存盘备用,以及写入csv文件
> options(stringsAsFactors = FALSE) #设置字符串不自动识别为因子
>
> itemData<-data.frame(sellerNick=sellerNick,
+ sellerID=sellerID,
+ itemID=itemID,
+ price=price,
+ volume=volume)
> save(itemData,file = "E:/R语言笔记/R语言第七章/itemData.rData")
> write.csv(itemData,file = "E:/R语言笔记/R语言第七章/itemData.csv")
总体代码汇总如下:
> install.packages("rvest")
> # 加载包
> library(rvest)
载入需要的程辑包:xml2
> #保存搜索链接对象到gurl
> gurl<-"https://list.tmall.com/search_product.htm?spm=a220m.1000858.1000720.2.JVFBWt&cat=50024399&brand=11119&q=%B1%CA%BC%C7%B1%BE%B5%E7%C4%D4&sort=s&style=g&from=sn_1_brand-qp&active=1#J_crumbs"
> #抓取数据对象保存到SCdata中
> #%>%是管道操作符
> #意思是把左边的操作结果作为参数传递给右边的命令
> #div.product-iWrap是CSS选择器的语法,即div class="div.product-iWrap"
> SCdata<-gurl %>%
+ read_html(encoding="GBK")%>%#读取gurl的链接,并指定编码为gbk.
+ html_nodes("div.product-iWrap")#筛选出所有包含在...
块的内容
>
> #从对象SCdata继续筛选,获取卖家名称等数据
> #html_attr("data-nick")是从html_nodes()筛选出的标签中,查找data-nick属性的值。
> #gsub()是字符串查找替换的函数,pattern是指定用来查找的正则表达式。
> #html_nodes("p.productTitle>a[title]"),">"指定的筛选条件的标签
> #html_text()只抓取<标签>内容中的内容部分
>
> #抓取卖家昵称和ID
> sellerNick<- SCdata %>% html_nodes("p.productStatus>span[class]") %>%
+ html_attr("data-nick")
> sellerID<- SCdata %>% html_nodes("p.productStatus>span[data-atp]") %>%
+ html_attr("data-atp") %>%
+ gsub(pattern="^.*,",replacement="")
>
> #抓取宝贝名称等数据
> itemTitle<- SCdata %>% html_nodes("productTitle>a[title]") %>%
+ html_attr("title")#暂时未能输出结果,先放下,后面再请教作者并尝试。
> itemID<- SCdata %>%html_nodes("p.productStatus>span[class]") %>%
+ html_attr("data-item")
> price<- SCdata %>% html_nodes("em[title]") %>%
+ html_attr("title") %>%
+ as.numeric
> volume<- SCdata %>% html_nodes("span>em") %>%
+ html_text
>
>
> #最后保存成数据框对象并存盘备用,以及写入csv文件
> options(stringsAsFactors = FALSE) #设置字符串不自动识别为因子
>
> itemData<-data.frame(sellerNick=sellerNick,
+ sellerID=sellerID,
+ itemID=itemID,
+ price=price,
+ volume=volume)
> save(itemData,file = "E:/R语言笔记/R语言第七章/itemData.rData")
> write.csv(itemData,file = "E:/R语言笔记/R语言第七章/itemData.csv")
三、进行数据分析
生成了itemData数据为.csv文件,在预览是提示需要保存为.excel文件。在本例中可以直接进行分析。本例只抓取了天猫上一个页面的综合数据(笔记本电脑-联想品牌,未使用其它筛选条件,保持天猫首页给出数据的原始性),数据量较小,不具有充分的代表性和实际意义,仅为实践操作。
01.直接进行预处理
参照实践课程的处理方式,删除所有含有缺失数据的行。虽然数据样本可能是完整的,但是在分析数据是严谨细致是必须的。使用na.omit()函数可以删除所有含有缺失数据的行,可以使用newData<-na.omit(itemData)。本例在抓取数据生成数据框的时候,已经进行了验证。
> itemData<-itemData[!is.na(itemData$price),] #保留未缺失价格的数据
> itemData
也可采取同样的方法对销售的数量volume进行操作,目的是保证后期重要数据的有效性。
02.进行列名重命名工作
使用fix()函数调出编辑器即可。或者使用names()函数来重命名。
03.处理销售数量列
本例不涉及日期。本例子中较为有用的信息主要是price、volume、sellerNick。本例需要处理的是volume,从中分离出销售数量,即从384笔中提取出384。具体使用字符串中的str_extract()函数:
> library(stringr)#载入字符串
> Newvolume<-str_extract(itemData$volume, "\\d+")#注意d后面的+号,否则只会输出每个销售数量中第一个数字,
#+号的意思是输出识别到所有数字。
> Newvolume
[1] "363" "493" "123" "491" "365" "929" "670" "439" "143" "98"
[11] "153" "1465" "1270" "110" "522" "128" "473" "277" "345" "161"
[21] "215" "87" "64" "190" "116" "107" "38" "567" "126" "85"
[31] "201" "359" "106" "13" "92" "147" "2" "167" "79" "66"
[41] "51" "56" "61" "106" "11" "19" "38" "69" "27" "60"
[51] "14" "17" "12" "25" "33" "11" "44" "2" "36" "14"
> NewData<-cbind(itemData,Newvolume)#把筛选出来的销售数量添加到原数据集中。
> save(NewData,file = "E:/R语言笔记/R语言第七章/NewData.rData")
> write.csv(NewData,file = "E:/R语言笔记/R语言第七章/NewData.csv")
打开输出的文件Newdata查看了一下,数据转换正常。
04.对Newvolume和price进行类型转换。
> class(NewData$newvolume)#先查看类别
[1] "character"
> class(NewData$price) #先查看类别
[1] "numeric"
> NewData$newvolume<-as.numeric(NewData$newvolume)#进行转换
> NewData$price<-as.numeric(NewData$price) #进行转换
> class(NewData$newvolume)#进行再次查看
[1] "numeric"
> class(NewData$price) #进行再次查看
[1] "numeric"
05.排序
可以使用order()函数对一个数据框进行排序,按照Newvolume对数据进行升序排序。
NewData<-NewData[order(NewData$newvolume),]#排序后备用
四、对数据的分析运用
目的一:计算样本中联想电脑的均价,销售数量的均值,并以此计算出总样本平均的销售价格。
目的二:销售总金额
目的三:绘制价格-销售数量图(折线图和点图)
01.计算联想电脑均价
> shopkpi1<-nrow(NewData)#
> shopkpi1#计算抓取总的店铺数量(包括重复的店铺,因为存在价格不同、销售数量不同的情况)
[1] 60
> totalPrice<-sum(NewData$price,na.rm = TRUE)#求和
> averagePrice<-totalPrice/shopkpi1
> averagePrice#求出均价
[1] 4383.617
这里计算了一下联系电脑价格四分位数:
可以看到样本中求取得平均价格4383.617比60%的临界点小,比40%的临界点大,但更靠近60%的临界点,也就是说均价处于中等偏上位置。
> y<-quantile(NewData$price,c(.8,.6,.4,.2))
> y#求取分位数
80% 60% 40% 20%
5179 4539 3979 3479
> z<-median(NewData$price)
> z#价格中位数
[1] 4324
> min(NewData$price)#求取最小值
[1] 2488
> max(NewData$price)#求取最大值
[1] 8399
> #绘制箱线图
> boxplot(NewData$price,main="联想电脑价格箱线图",ylab="Price")
02.计算销售数量的均值
> shopkpi1<-nrow(NewData)#获取行数
> shopkpi1
[1] 60
> totalVolume<-sum(NewData$newvolume,na.rm = TRUE)#求取销售数量总和,即共有多少笔交易
> averageVolume<-totalVolume/shopkpi1
> totalVolume
[1] 12495
> averageVolume#店铺的平均销量为208.25笔交易(表示为已经收到货,
#且确认付款的交易,不包括未确认收获的交易情况,同时这也不是一个完整月的交易量,数据截止到2017.04.23)
[1] 208.25
03.计算截止目前四月份销售总金额
> totalmoney<-sum(NewData$price*NewData$newvolume,na.rm = TRUE)
> totalmoney#抓取得页面中联系电脑总销售金额将近五千万
[1] 48700684
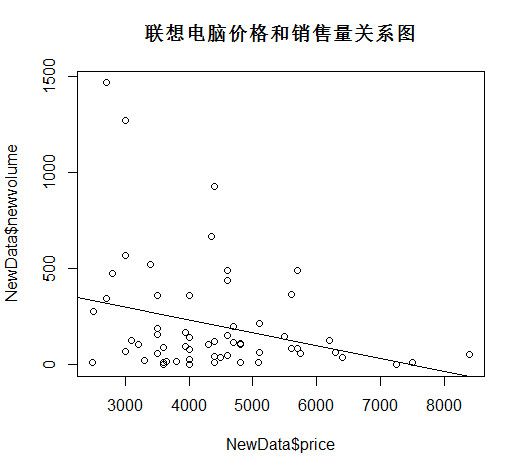
04绘制价格-销量图
a.绘制最优拟合图
> #绘制最优拟合曲线图
> attach(NewData)
> plot(NewData$price,NewData$newvolume)
> abline(lm(NewData$price~NewData$newvolume))
> title("联想电脑价格和销售量关系图")
> detach(NewData)
看来市场经济的规律是对的,需求第一定律说:无论何时何地,价格提高,商品的需求量就减少,价格降低到一定程度,需求量就一定会增加。
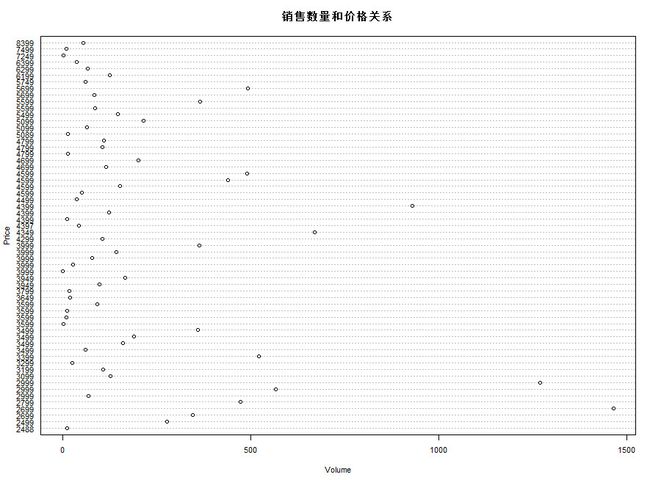
b.绘数点图
dotchart(NewData$newvolume,labels = NewData$price,cex = .7,
main = "销售数量和价格关系",
xlab="销售数量")
关于点数图中,想进行分类别处理,目前还在探索中,后续会更新。