本课程目标
本课程有以下几个目标:
- 第一:对hadoop没有了解的学员来说,可以帮助其了解在一般工作中hadoop的基本用法,以及对如何用hadoop有一定的了解。
- 第二:对hadoop有了解的学员来说,其一可以帮助学员加深对hadoop的了解,其二可以让学员对hadoop的实际应用场景有一个比较深入的了解。
Hadoop的主要应用场景
这里说的hadoop指的是以hadoop为中心的hadoop生态圈。
场景1:数据分析平台
场景2:推荐系统
场景3:业务系统的底层存储系统
场景4:业务监控系统
...............................
什么是数据分析平台
数据分析的主要目标是为公司提供一系列的网站指标,期望能够帮助到运维、技术等各个不同部门了解公司网站的情况。比如:当一个网站的注册方式修改后,我们发现访客转会员的比例降低了,那么我们可能就可以得出一个结论:“可能是用户觉得这种注册方式太麻烦而导致,不想注册了。”,这个时候我们可能就需要重新设计注册页面了。
数据分析这种平台比较适合电商类的网站,其他类型的相比较而言对这种类型的平台需求就低一点。主要原因是影响电商的主要因素有以下几个:第一,访客转会员率;第二,会员留存率;第三,会员购买率(复购率)。
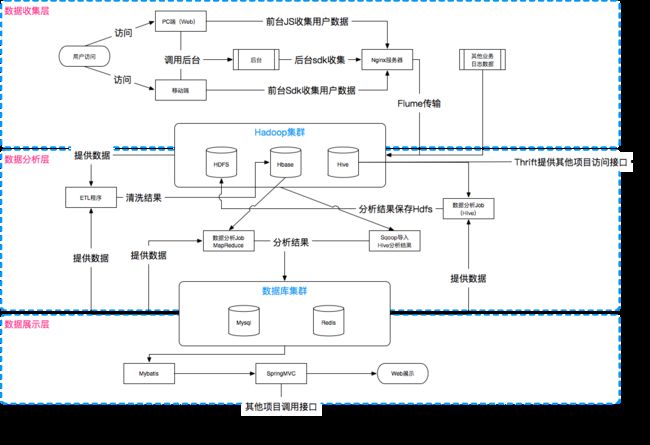
数据分析平台主体架构
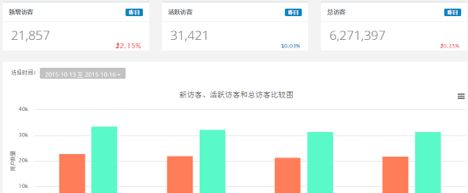
数据平台的最终产出
Hadoop简单介绍
Hadoop是apache基金会组织的一个顶级项目,
其核心为HDFS和MapReduce,HDFS为海量的数据提供存储,而MapReduce为海量的数据提供计算,
官网:http://hadoop.apache.org。
在Apache Hadoop的基础上,Cloudera公司将其进行商业化改进和更新,它的发行版本就是CDH(Cloudera Distribution Hadoop),
CDH官网:http://www.cloudera.com。
hadoop2.5.0-cdh5.3.6
CDH4.x: http://archive.cloudera.com/cdh4/cdh/4/
CDH5.x: http://archive.cloudera.com/cdh5/cdh/5/
CDH5.3.6文档:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.5.0-cdh5.3.6/
Apache Hadoop :http://archive.apache.org/dist/hadoop/common
Apache Hadoop文档:http://hadoop.apache.org/docs
JDK下载地址 :http://www.oracle.com/technetwork/java/javase/archive-139210.html
Hadoop伪分布式环境搭建
安装步骤:
1. 创建用户,使用hadoop用户
2. 修改主机名以及ssh免密码登录
3. jdk安装
4. hadoop安装
Hadoop环境搭建-创建用户
步骤:(root用户密码为123456)
1. 使用useradd hadoop添加用户
2. 使用passwd hadoop设置用户密码,密码为abc123_
3. 给用户赋予使用sudo命令的权限。
4. chmod u+w /etc/sudoers
6. vim /etc/sudoers
7. 在root ALL=(ALL) ALL下面加上一行hadoop ALL=(ALL) ALL。(分隔的是制表符)
8. chmod u-w /etc/sudoers



Hadoop环境搭建-修改主机名以及ssh免密码登录
步骤:(使用hadoop用户登录)
1. 使用sudo hostname hh修改主机名,当前生效,重启后失效。
2. 使用vim /etc/sysconfig/network修改主机名,重启生效。
3. 在/etc/hosts文件中添加主机名对于的ip地址。
4. 使用ssh-keygen -t rsa生成ssh秘钥。dsa
5. 进入.ssh文件夹,创建authorized_keys文件,并将id_rsa.pub的内容添加到文件中去,修改文件权限为600(必须)。
6. ssh hh验证
SSH免密登录教程https://www.jianshu.com/p/8515c5602811


Hadoop环境搭建-JDK安装
步骤:
1. 复制jdk压缩包到softs文件夹中
2. 解压tar -zxvf softs/jdk-7u79-linux-x64.tar.gz
3. 创建软连接sudo ln -s /home/hadoop/bigdater/jdk1.7.0_79 /usr/local/jdk
4. 配置相关环境变量vim ~/.bash_profile: JAVA_HOME, CLASSPATH, PATH。全局生效配置文件/etc/profile。
5. 使环境变量生效 source ~/.bash_profile
7. 验证java version/ javac version


Hadoop环境搭建-hadoop安装
步骤:
1. 下载hadoop安装包并复制到到softs文件夹中。
2. 解压tar -zxvf softs/hadoop-2.5.0-cdh5.3.6.tar.gz,并创建数据保存文件hdfs(~/bigdater/hadoop-2.5.0-cdh5.3.6/hdfs/)。
3. 配置hadoop-env.sh mapred-env.sh yarn-env.sh文件
4. 配置基本环境变量core-site.xml文件
5. 配置hdfs相关变量hdfs-site.xml文件
7. 配置mapre相关环境变量mapred-site.xml文件
8. 配置yarn相关环境变量yarn-site.xml文件
9. 配置datanode相关变量slaves文件
10. 配置hadoop相关环境变量

Hadoop环境搭建-hadoop启动
步骤:
1. 第一次启动hadoop之前需要格式化namenode节点,命令为hadoop namenode -format。
2. 两种方式启动start-all.sh或者start-hdfs.sh start-yarn.sh。
3. 查看是否启动成功。
格式化提示信息

Hadoop环境搭建-验证hadoop是否启动成功
步骤:
1. 验证hadoop是否启动成功有两种方式,第一种:通过jps命令查看hadoop的进行是否启动,第二种:查看web界面是否启动显示正常内容。
2. 验证hadoop对应的yarn(MapReduce)框架是否启动成功:直接运行hadoop自带的example程序。
创建一个test.txt
echo "welcome to join us bjsxt 尚学堂 优效学院 优效聚名师 学习更有效" >> test.txt
hadoop dfs -put test.txt /
使用hadoop自带的mapreduce程序验证:/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar
将文件内容添加上去后执行:hadoop jar hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /test.txt output/wordcount
执行完成以后运行 hadoop dfs -text output/wordcount/part-*
中途遇到了一个问题
hadoop Unhealthy Nodes问题解决
http://www.jianshu.com/p/a01c0bf5dd6a
是磁盘空间不足导致的,清空回收站之后就好了,晕死
AlbertMP:mapreduce Albert$ hadoop dfs -text output/wordcount/part-*
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
17/08/27 23:49:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
bjsxt 1
join 1
to 1
us 1
welcome 1
优效学院 1
优效聚名师 1
学习更有效 1
尚学堂 1
问题:
1.如果virtualbox无法选择64位操作系统安装,问题就是机器没有开始cpu虚拟化。bios需要设置一些信息。参考网站:http://jingyan.baidu.com/article/8ebacdf0df465b49f65cd5d5.html
配置信息参考
第一步:配置hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
export HADOOP_PID_DIR=/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/hdfs/tmp
第二步:配置mapred-env.sh
export HADOOP_MAPRED_PID_DIR=/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/hdfs/tmp
第三步:配置yarn-env.sh
export YARN_PID_DIR=/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/hdfs/tmp
第四步:配置core-site.xml文件
fs.defaultFS
hdfs://hh:8020
hadoop.tmp.dir
/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/hdfs/tmp
第五步:配置hdfs-site.xml文件
dfs.replication
1
dfs.namenode.name.dir
/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/hdfs/name
dfs.namenode.data.dir
/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/hdfs/data
dfs.permissions.enabled
false
第六步:创建mapred-site.xml文件,直接执行命令cp mapred-site.xml.templete mapred-site.xml
第七步:配置mapred-site.xml文件
mapreduce.framework.name
yarn
第八步:配置yarn-site.xml文件
yarn.nodemanager.aux-services
mapreduce_shuffle
第九步:配置slaves指定datanode节点,将localhost改成主机名
第十步:修改环境变量文件".base_profile",并使其生效
###### hadoop 2.5.0
export HADOOP_HOME=/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_PREFIX
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_PREFIX
export HADOOP_MAPRED_HOME=$HADOOP_PREFIX
export HADOOP_YARN_HOME=$HADOOP_PREFIX
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin