一、初步认识
- 如何入门 Python 爬虫?大家可以看看知乎这篇文章(简单易懂)
-
什么是爬虫?大家可以先看一下下面几张图。
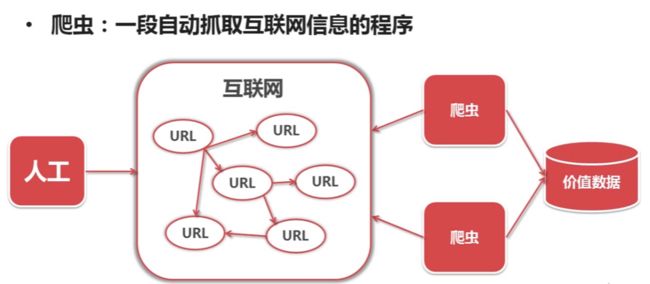
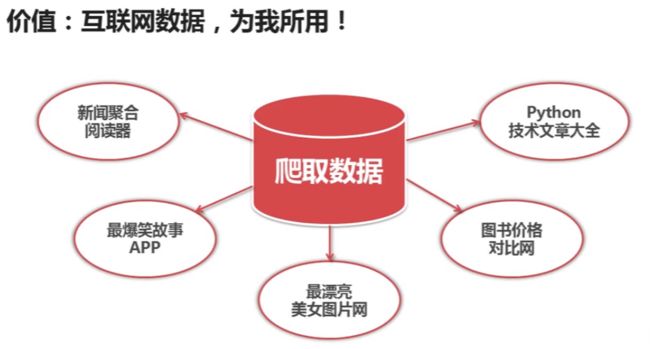
二、我的学习步骤:
1、Python开发环境搭建
下图为基于Intellij IDEA的python环境搭建成功的界面,大家自行百度搭建过程。
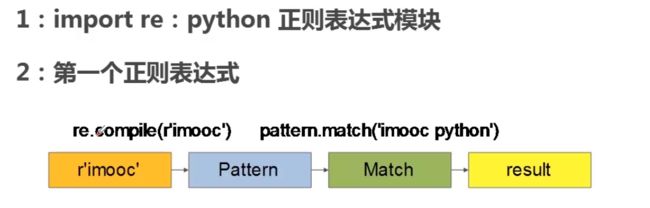
2、Python正则表达式(建议观看慕课网这个视频)
问:为什么要使用正则?
答:虽然字符串匹配可以实现,但是每一次匹配都要单独完成,重复代码多,我们能否把它做成一个规则?因此正则出现了。
正则表达式概念
- 使用单个字符串来描述匹配一系列符合某个句法规则的字符串
- 是对字符串操作的一种逻辑公式
- 应用场景:处理文本和数据
- 正则表达式过程:依次拿出表达式好文本中的字符比较,如果没一个字符都能匹配,则匹配成功;否则匹配失败。
正则表达式匹配流程
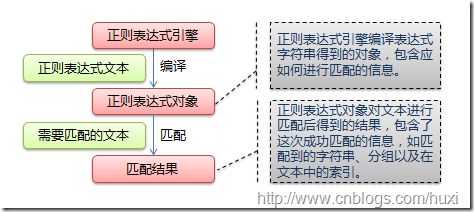
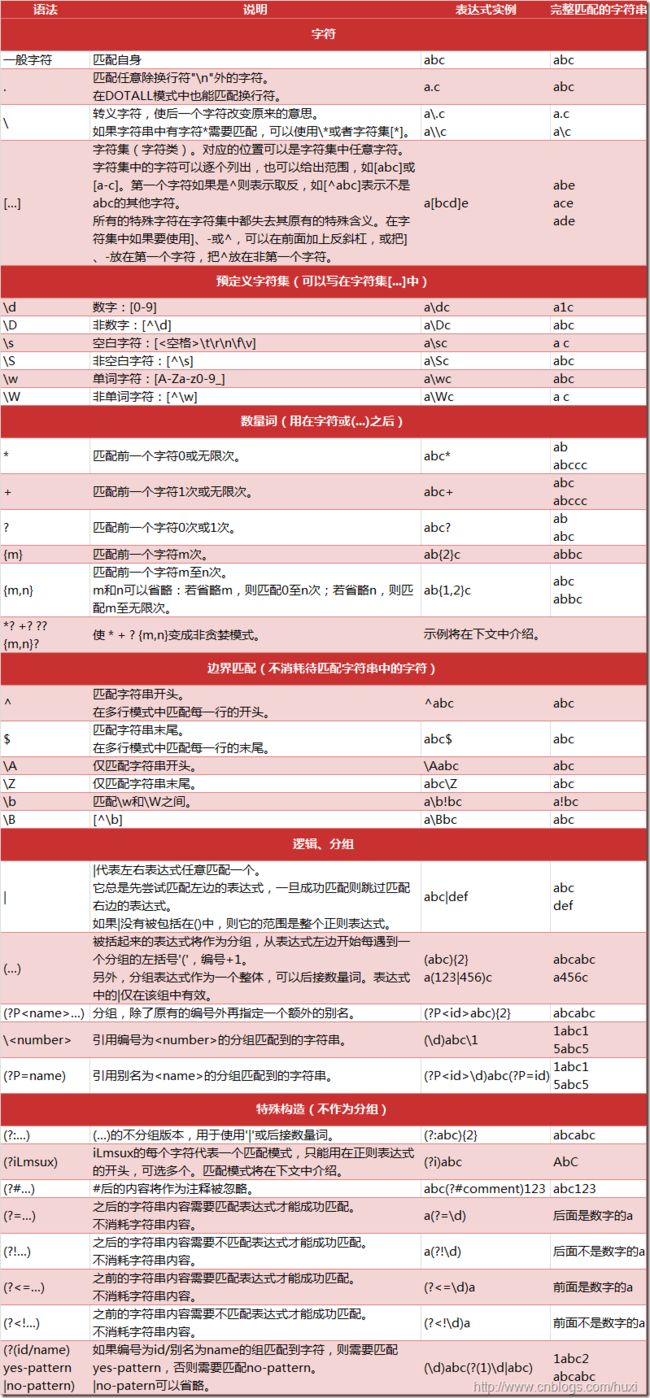
正则表达式元字符和语法
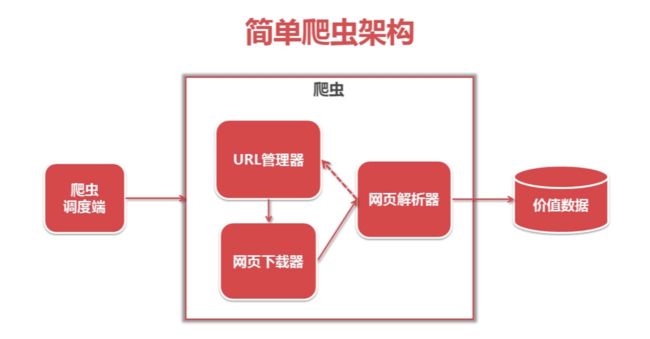
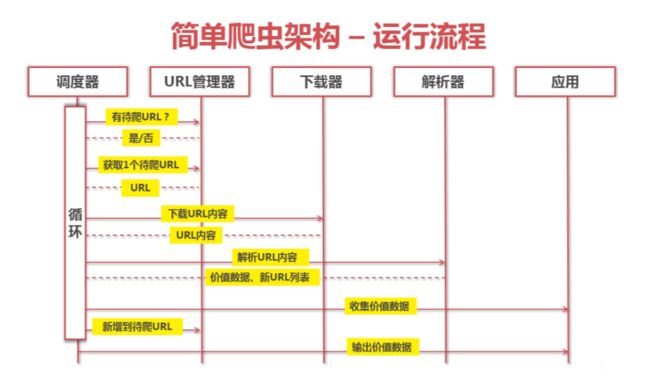
3、python开发简单爬虫(轻量级爬虫、不需要登录的静态加载网页抓取)
-
URL管理器:管理待爬取URL集合和已抓取URL集合(防止重复抓取、防止循环抓取)
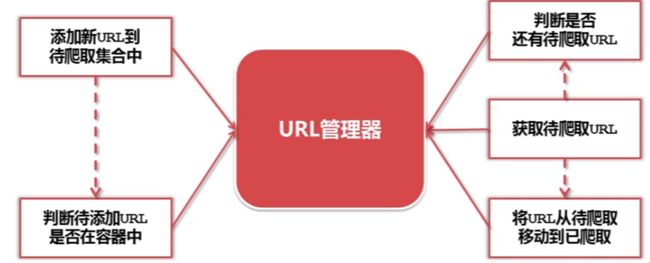
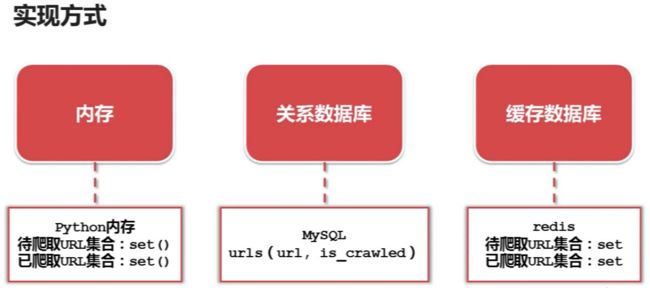
- 网页下载器:将互联网上URL对应的网页下载到本地的工具,有urllib2(python官方基础模块)和requests(第三方包更强大)
以下为urllib2网页下载方法的三种方法示例:
# coding:utf-8
import urllib2, cookielib
url='http://www.baidu.com'
print"1)urllib2下载网页方法1"
# 直接请求
response1 = urllib2.urlopen(url)
# 获取状态码,如果是200表示获取成功
print response1.getcode()
# 读取网页内容的长度
print len(response1.read())
print"2)urllib2下载网页方法1"
# 创建Request对象
request = urllib2.Request(url)
# 添加数据
# request.add_data('a', '1')
# 添加http的header
request.add_header('User-Agent', 'Mozilla/5.0')
# 发送请求获取结果
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
print"3)添加特殊情景的处理器"
# 创建cookie容器
cj = cookielib.CookieJar()
# 创建1个opener
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
# 给urllib2安装opener
urllib2.install_opener(opener)
# 使用带有cookie的urllib2访问网页
response3 = urllib2.urlopen(url)
print response3.getcode()
print cj
print response3.read()
-
网页解析器
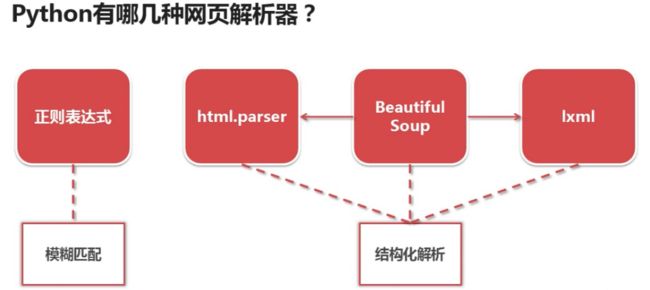
下面介绍一下beautifulsoup4(Python第三方库,用于从HTML或XML中提取数据)
首先,安装beautifulsoup4


下面我们来看看Beautifulsoup的实例分析
# coding:utf-8
from bs4 import BeautifulSoup
import re
#举例:解析网页文档字符串
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
# 创建Beautifulsoup对象
soup = BeautifulSoup(html_doc, #HTML文档字符
'html.parser', #HTML解析器
from_encoding='utf-8') #HTML文档的编码
#方法find_all(name,attrs,string) 节点名称、节点属性、节点内容
print '获取所有的链接'
links=soup.find_all('a')
for link in links:
print link.name,link['href'],link.get_text()
print '获取Lacie的链接'
link_code = soup.find('a',href='http://example.com/lacie')
print link_code.name,link_code['href'],link_code.get_text()
# bs4之强大:支持正则匹配
print'正则匹配'
link_node = soup.find('a',href=re.compile(r"ill"))
print link_node.name,link_node['href'],link_node.get_text()
print '获取P段落文字'
p_node = soup.find('p',class_="title") #class要加下划线
print p_node.name,p_node.get_text()
4、实战演练:爬取百度百科1000个页面的数据
- 确定目标:确定要抓取哪个网站的哪些网页的哪些数据
- 分析目标:制定抓取这些网站数据的策略(URL格式、数据格式、页面编码)[ 实际操作:打开网站,锁定位置,右键审查元素]
以下是我在慕课网学习简单爬虫来爬取百度百科的总结:
-
思路:一个url管理器,来获取和管理所有需要爬取的链接a,比如在这里我们先获取https://baike.baidu.com/item/Python这个页面的所有a标签,将其存入一个容器(new_urls)中,然后依次爬取这个容器中的所有url,每爬一次,把爬取过的url从这个容器中删去,加入到old_urls容器中, 并且加入到new_urls时要判断这个url是否在new_urls和old_urls已经存在,若存在,不加入,防止重复爬取。然后通过页面下载器利用urllib2下载我们需要的页面代码,页面解析器html_parse利用beautifulsoup获取我们需要的数据。
 目录展示
目录展示 具体代码
1.主函数 spider_main.py
# coding:utf-8
from baike_spider import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print 'craw %d : %s' % (count, new_url)
html_cont = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 1000:
break
count = count + 1
except:
print 'craw failed'
self.outputer.output_html()
if __name__ == "__main__":
# 爬虫入口页面
root_url = "https://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
# 启动爬虫
obj_spider.craw(root_url)
2.url管理器 url_manager.py
# coding:utf-8
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
#向管理器中添加新的url
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
#向管理器中添加批量的url
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
#判断管理器中是否有新的url
def has_new_url(self):
return len(self.new_urls) != 0
#获取新的带爬取的url
def get_new_url(self):
new_url = self.new_urls.pop() # 获取并移除
self.old_urls.add(new_url)
return new_url
3.页面下载器 html_downloader.py
# coding:utf-8
import urllib2
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
response=urllib2.urlopen(url) #因为百度百科比较简单,所以只使用了urllib2这个模块最简单的方法
if response.getcode() != 200:
return None
return response.read()
4.页面解析器 html_parser.py
# coding:utf-8
from bs4 import BeautifulSoup
import re
import urlparse
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
new_urls = set()
# /view/123.htm
# links = soup.find_all('a', href=re.compile(r"/item/\d+\.html"))
links = soup.find_all('a', href=re.compile(r"/item/(.*)"))
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url, new_url) # 拼接url
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {} # 字典
# url
res_data['url'] = page_url
# Python
title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data['title'] = title_node.get_text()
#
summary_node = soup.find('div', class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
4.页面输出器 html_outputer.py
# coding:utf-8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = open('output.html', "w")
fout.write("")
fout.write("")
fout.write("")
# ascii
for data in self.datas:
fout.write("")
fout.write("%s " % data['url'])
fout.write("%s " % data['title'].encode('utf-8'))
fout.write("%s " % data['summary'].encode('utf-8'))
fout.write(" ")
fout.write("")
fout.write("")
fout.write("
")
fout.close()
运行后,会在目录下产生output.html,这个文件即是爬取结果的展示。
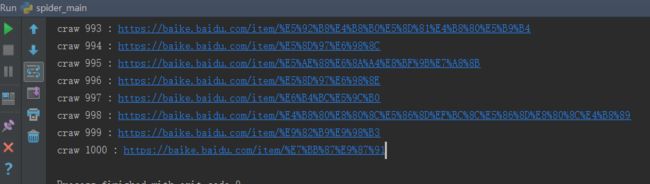
成功爬取完1000个页面的数据!
5、可以再深入理解一下爬虫的意义了
大家可以观看这篇大话爬虫这篇文章!
然后就是知乎这篇文章如何入门python爬虫
下面稍微做一下总结:
1、Python基础准备(可以去看廖雪峰老师的教程,2.7的。至少这些功能和语法你要有基本的掌握 )
- list,dict:用来序列化你爬的东西
- 切片:用来对爬取的内容进行分割,生成
- 条件判断(if等):用来解决爬虫过程中哪些要哪些不要的问题
- 循环和迭代(for while ):用来循环,重复爬虫动作
- 文件读写操作:用来读取参数、保存爬下来的内容等
2、网页基本知识
- 基本的HTML语言知识(知道href等大学计算机一级内容即可)
- 理解网站的发包和收包的概念(POST GET)
- 稍微一点点的js知识,用于理解动态网页(当然如果本身就懂当然更好啦)
3、分析语言
- NO.1 正则表达式:扛把子技术,总得会最基础的
- NO.2 XPATH:高效的分析语言,表达清晰简单,掌握了以后基本可以不用正则
参考:XPath 教程
- NO.3 Beautifulsoup:
美丽汤模块解析网页神器,一款神器,如果不用一些爬虫框架(如后文讲到的scrapy),配合request,urllib等模块(后面会详细讲),可以编写各种小巧精干的爬虫脚本
官网文档:Beautiful Soup 4.2.0 文档
4、高效工具辅助
- NO.1 F12 开发者工具:
看源代码:快速定位元素
分析xpath:1、此处建议谷歌系浏览器,可以在源码界面直接右键看
- NO.2 抓包工具:
推荐httpfox,火狐浏览器下的插件,比谷歌火狐系自带的F12工具都要好,可以方便查看网站收包发包的信息
- NO.3 XPATH CHECKER (火狐插件):
非常不错的xpath测试工具,但是有几个坑,都是个人踩过的,在此告诫大家:
1、xpath checker生成的是绝对路径,遇到一些动态生成的图标(常见的有列表翻页按钮等),飘忽不定的绝对路径很有可能造成错误,所以这里建议在真正分析的时候,只是作为参考
2、记得把如下图xpath框里的“x:”去掉,貌似这个是早期版本xpath的语法,目前已经和一些模块不兼容(比如scrapy),还是删去避免报错
- NO.4 正则表达测试工具:
在线正则表达式测试 ,拿来多练练手,也辅助分析!里面有很多现成的正则表达式可以用,也可以进行参考!
5、更多
- 模块:python的火,很大原因就是各种好用的模块,这些模块是居家旅行爬网站常备的。
urllib
urllib2
requests
- 框架:不想重复造轮子,有没有现成的框架?
华丽丽的scrapy
- 遇到动态页面怎么办?
selenium(会了这个配合scrapy无往不利,是居家旅行爬网站又一神器,下一版更新的时候会着重安利,因为这块貌似目前网上的教程还很少)
phantomJS(不显示网页的selenium)
- 遇到反爬虫策略验证码之类咋整?
PIL
opencv
pybrain
打码平台
- 数据库:这里我认为开始并不需要非常深入,在需要的时候再学习即可。
mysql
mongodb
sqllite
- 爬来的东西怎么用?
numpy 数据分析,类似matlab的模块
pandas(基于numpy的数据分析模块,相信我,如果你不是专门搞TB级数据的,这个就够了)
- 进阶技术:
多线程
分布式
三、后期思考与改进
1)效率
如果你直接加工一下上面的代码直接运行的话,你需要一整年才能爬下整个豆瓣的内容。更别说Google这样的搜索引擎需要爬下全网的内容了。
问题出在哪呢?需要爬的网页实在太多太多了,而上面的代码太慢太慢了。设想全网有N个网站,那么分析一下判重的复杂度就是N*log(N),因为所有网页要遍历一次,而每次判重用set的话需要log(N)的复杂度。OK,OK,我知道python的set实现是hash——不过这样还是太慢了,至少内存使用效率不高。
通常的判重做法是怎样呢?Bloom Filter. 简单讲它仍然是一种hash的方法,但是它的特点是,它可以使用固定的内存(不随url的数量而增长)以O(1)的效率判定url是否已经在set中。可惜天下没有白吃的午餐,它的唯一问题在于,如果这个url不在set中,BF可以100%确定这个url没有看过。但是如果这个url在set中,它会告诉你:这个url应该已经出现过,不过我有2%的不确定性。注意这里的不确定性在你分配的内存足够大的时候,可以变得很小很少。一个简单的教程:Bloom Filters by Example
注意到这个特点,url如果被看过,那么可能以小概率重复看一看(没关系,多看看不会累死)。但是如果没被看过,一定会被看一下(这个很重要,不然我们就要漏掉一些网页了!)。 [IMPORTANT: 此段有问题,请暂时略过]
好,现在已经接近处理判重最快的方法了。另外一个瓶颈——你只有一台机器。不管你的带宽有多大,只要你的机器下载网页的速度是瓶颈的话,那么你只有加快这个速度。用一台机子不够的话——用很多台吧!当然,我们假设每台机子都已经进了最大的效率——使用多线程(python的话,多进程吧)。
2)集群化抓取
爬取豆瓣的时候,我(这不是我hh)总共用了100多台机器昼夜不停地运行了一个月。想象如果只用一台机子你就得运行100个月了...
那么,假设你现在有100台机器可以用,怎么用python实现一个分布式的爬取算法呢?
我们把这100台中的99台运算能力较小的机器叫作slave,另外一台较大的机器叫作master,那么回顾上面代码中的url_queue,如果我们能把这个queue放到这台master机器上,所有的slave都可以通过网络跟master联通,每当一个slave完成下载一个网页,就向master请求一个新的网页来抓取。而每次slave新抓到一个网页,就把这个网页上所有的链接送到master的queue里去。同样,bloom filter也放到master上,但是现在master只发送确定没有被访问过的url给slave。Bloom Filter放到master的内存里,而被访问过的url放到运行在master上的Redis里,这样保证所有操作都是O(1)。(至少平摊是O(1),Redis的访问效率见:LINSERT – Redis)
3)后续处理
- 有效地存储(数据库应该怎样安排)
- 有效地判重(这里指网页判重,咱可不想把人民日报和抄袭它的大民日报都爬一遍)
- 有效地信息抽取(比如怎么样抽取出网页上所有的地址抽取出来,“朝阳区奋进路-
中华道”),搜索引擎通常不需要存储所有的信息,比如图片我存来干嘛...
- 及时更新(预测这个网页多久会更新一次)