一. 背景
1. 意义
ConceptLearning作为一个比较早期出现的机器学习方法, 已经"显得"没有特别大的实用价值. 但是, Concept Learning却有比较大的理论价值, 在迈入神经网络等复杂方法之前, 它能够帮助初学者很好地去理解机器学习的一些基本思想和理念(e.g.样本空间, 假设空间).
2. 要点
Learning from example
General to specific ordering over hypo(归纳学习)
Version spaces and candidate elimination algo!! (核心)
picking new examples
The need for inductive bias
note: assume no noise, illustrate key concepts
一般最后是给出1, 0 二分结果.
二. Problem and Task
1. Problem
Automatically inferring the general definition of some concept, given examples labeled as members or nonmembers of the concept.
2. Concept Learning
Inferring a boolean–valued function from training examples of its input and output.
其实非常类似LogisticsRegression, 就是输入数据, 能够回答1, 0.
3. Task: EnjoySport Case
输入数据形式:
sky temp humid wind water forecst enjoysport(Y)
sunny warm normal strong warm same Y
rainny cold high strong warm change N

可以看到, EnjoySpt这个列, 其实代表了y值列.
我们希望经过一定的trainning, 能够实现给定一组属性, 机器就能给出Y或者N的回答, 即是否enjoySport.
三. Representing hypo 形式化表示
1. 占位符:?
我们约定: 每个值要么是给定值, 要么是?. 其中?代表这个值在这个位置缺失, 因此可以是任意允许的值, 比如Temp只允许两个值{Warm, Cold}, 那么此处占位的?就代表either Warm or Cold. 原先PPT中有∅这个标识, 但是我认为非常容易引发误解(它不代表值缺失, 而代表本行y值经过布尔运算恒等于0/No), 最好干脆不使用它.
2. Notation(very important)
1)X: set of instance
样本集合, 里面存放着一行一行的数据, 每行数据都有1~p个属性
2)c: target concept
c一般就是一个函数, 输入X集合中的某个记录x[i], 就能返回一个y[i]值 --> y[i] = c(x[i])
3)traning example
an instance x from X, along with its target concept value c(x).
其实就是从X集合中取出一个x记录, 以及对应的y=c(x)值, 这样的(x, y) - LabeledVector(scala)形式就是训练例子. 其中也可以有正向和负向例子(Positive/Negative Example), 就是y=1或者y=0的情况.
4)D: the set of available training examples
训练例子集合 trainning set, 每个例子都是有属性有y值的(x, y)形式
5)H: the set of all possible hypotheses
所有可能的假设, 表现为所有可能的模型函数function的集合.
6)h: 假设的布尔函数/模型
每个模型h in H都表示一个生成之为0, 1函数, 即h: X ->{0, 1}
each hypothesis h in H represents a boolean-valued function defined over X; that is, h: X {0, 1}.
因此, Goal of the learner: to find a hypo h such that h(x) = c(x) for all x, 换句话说找一个尽量完美拟合所有训练数据的模型函数
3. Learning task representation
1) instance X
We have multiple records, each representing a day. All these make a set of instances that called X.
attributes: Sky, Air, ...
2) target concept c
we try to get an concept, an model of EnjoySport based on our data.
target concept c: EnjoySport: X {0, 1}
3) training example
4) D
就是我们打算用来作训练集的数据, 这里我们可以选取70%的数据作为训练集, 当然了, 必须带上他们的y值. 用剩下的作为验证.
D = {
5) H, h
Hypo H : Conjunction of literals 取值的集合
比如: 其中一个hypo h可能是 -> Y
Note: 在机器学习中hypo h基本上是一个具体模型/函数公式的同义词
四. Concept learning as search
首先, 再次复习下这个方法的思想
Idea: any hypothesis found to approximate the target function well over a sufficiently large set of training examples will also approximate the target function well over other unobserved examples.
1. Instance space X
我们先看一下每个属性, 都有几个可能的取值
Sky: 3 possible values
AirTemp: 2 possible values
Humid: 2
Wind: 2
Water: 2
Forecast: 2
The instance space X contains 96 distinct instance: 3*2*2*2*2*2=96
因此, X有 instance space 322*2.... = 96种独特的instance
2. Hypotheses space H
如果我们填充了? 和∅, 那么最后问题空间为5*4*4*4*4*4=5120, 这叫做Syntactically distinct hypotheses. 但是, 我们之前讨论过了, ∅在机器学习中是一个非常容易令人误解的概念, 我们可以尽量不去理它.
真正重要的是这个:
如果我们去掉∅, 只保留?代表任意值. 因此, 我们可以认为真正有意义的H space应该是1+4*3*3*3*3*3=973, 前面的1代表我们丢掉的所有∅情况. 在计算有意义的Hspace的时候加不加上这个1都无所谓, 这个973的大小这叫做Semantically distinct hypotheses, i.e. H space
可以看到 X space < H space, 这是因为H space允许一些字段用代表任意值的?来代替. 这增强了模型的泛化能力/适用面(Generality).
3. Generality 泛化能力/适用面大小
h1=< Sunny, ?, ?, Strong, ?, ? >
h2=< Sunny, ?, ?, ?, ?, ? >
h2 is more general than h1.

可以看到, 在图上, 越底层的h泛化能力越好.
五. 基础: 只看positive example的Find-S算法
1. Initialize h to the most specific hypothesis in H
2. For each positive training instance x:
For each attribute constraint a[i] in h:
If the constraint a[i] in h is satisfied by x:
then do nothing
Else:
replace ai in h by the next more general constraint that is satised by x
3. Out put hypothesis h
其实就是把函数放松, 放松的过程.

可以看到, 算法Else语句说replace a[i] by the most general constraint 其实就是把Normal -> ?, 把 Warm, Same -> ?, ?的过程.
Find-S作为基础算法, 实际上存在很多问题.
只看positive example, 忽略了很多的negative, 可能会严重影响泛化的正确性.
六. Version Spaces和改进的Candidate-Elimination algo
1. Consistent & VersionSpace
Consistent(全体正确性): a hypo h is consistent only if h(x) = c(x) for each training example
Version Space: VS
或者另外一个简单的定义, 就是a list of all hypotheses h.
注意, VersionSpace作为一个list, 是动态变化的, 在算法中里面的h会不断被验证并抛弃错误的那些.
2. the List-Then-Eliminate Algo
In a nutshell: generate a list, then try and eliminate list item, finally get a leftover list.
1. Version Space a list containing every hypothesis in H
2. For each training example :
remove from Version Space any hypothesis h for which h(x) != c(x)
3. Output the list of hypotheses in Version Space
3. 算法分析
这个算法能够保证正确性, 因为所有的正负例都将被用于检验. 任何模型h, 只要犯错一次就会被抛弃.
但是, 可以看到, 这个算法要对所有的h∈H(这个案例中是有快1000个)都进行检验, 非常非常耗时间. 实际应用中数据量一大起来, H space往往是上亿的, 跑起来非常慢.
七. Compact-Elimination algo
1. G and S boundary
G: the general bound G, 是最general的member set
S: the specific bound S, 是最specific的member set
所以, 我们认为在VSpace中, 所有的h都应该有S<= all h <= G.
2. algo
define: G maximally general hypotheses in H
define: S maximally specific hypotheses in H
For each training example d:
If d is a positive example:
Remove from G any hypothesis inconsistent with d
For each hypothesis s in S that is not consistent with d:
Remove s from S //此处其实没有错误, 这个写法相当于先删掉, 再按照all ds的共性添加新的s. 另外一个更有效率的方法, 应该是修改与新引入d矛盾的字段, 将其放松.
Add to S all minimal generalizations h of s such that //保持S的最具体性
1. h is consistent with d and previous ds, and
2. some member of G is more general than h
Remove from S any hypothesis that is more general than another hypothesis in S //去除同质性, 如果s2包含了s1, 那么应该去掉s2.
If d is a negative example:
Remove from S any hypothesis inconsistent with d
For each hypothesis g in G that is not consistent with d //保持G的最泛化性
Remove g from G
Add to G all minimal specializations h of g such that
1. h is consistent with d, and
2. some member of S is more specific than h //保证G和S能一致
Remove from G any hypothesis that is less general than another hypothesis in G //去除同质性, 如果g2包含了g1, 那么应该去掉g1
3. process illustration
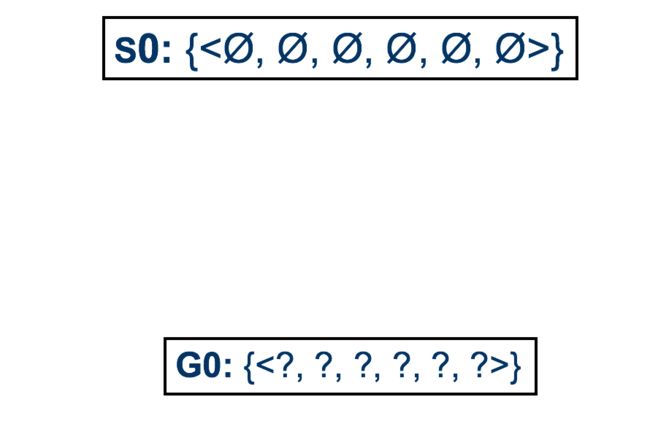


可以看到, S2是当前允许条件下least-general的h

这里的算法过程很有意思, 首先生成能够满足这个NegativeExample的G3集合, 然后删除掉那些和S2不能保持一致的.

注意到这里我们先删除了所有不匹配的g∈G, 所以第三个g被删除.
然后我们检查s∈S, 显然这里Temp和Forecst需要被放松, 因此我们把原先的attr=warm, same放松成了?, ?.

剩余的VersionSpace构成了最后的H, 其中S代表了具体界, G代表泛化界.
