本篇梳理 HTTP 的相关知识,也分享个人学习经验。有认识不对的地方,欢迎指正!
前端开发的很多工作,似乎都是 “所见即所得” 的,这种对知识强大的 “既视感”,是前端容易入门的一个关键因素。但越往后走,一些底层而重要的知识,就没那么容易触及了,比如 HTTP 协议。
一开始,可能就只知道 Ajax 是浏览器端 HTTP 强相关的一套 API;另外,无论是浏览器端,还是服务器端,都有一套对 HTTP 的解析、处理的机制。HTTP可以说是前、后端通信的载体。在我们工作中、或者我们面试时,经常涉及的性能优化问题、跨域问题、安全问题等等,都和它紧密相关。
就是因为它更底层,逻辑对外不可见,知识的 “既视感” 也比较难实现(如果有哪个团队做一款这样的产品,那肯定会在前端圈里圈粉无数)。但无论如何,HTTP 是前端进阶应该攻破的一道坎。
尽管它不像页面 DOM 元素、或者一个 react 组件那样触手可及,但我们仍然应该有办法学习它。我们可以暂且不理会内幕细节,把它当做一个 “黑盒子”,而通过一些其他的途径,旁敲侧击。比如使用一些抓包工具(本文用的是 Fiddler ),也能很好的窥视 HTTP 的形貌。
1、认识 HTTP 报文
以访问“”站点首页http://www.jianshu.com/ 为例,通过 Fiddler 工具抓取到以下报文信息。
请求报文
GET http://www.jianshu.com/ HTTP/1.1
Host: www.jianshu.com
Connection: keep-alive
Cache-Control: max-age=0
User-Agent: Mozilla/5.0 Chrome/58.0.3029.110 Safari/537.36
Accept: text/html;q=0.9,image/webp,*/*;q=0.8
Referer: http://www.jianshu.com
Accept-Encoding: gzip, deflate, sdch
Accept-Language: zh-CN,zh;q=0.8
//本行及以下均为报文主体
无论请求报文,还是响应报文,都是有着严格的格式规范的,它们绝不是一堆毫无规范组织的字符串。正式这一套标准规范,让报文的解析、分割、组包可以用一定的算法实现,具体内幕本文不涉及。
响应报文
HTTP/1.1 200 OK
Date: Mon, 14 Aug 2017 12:36:22 GMT
Server: Tengine
Content-Type: text/html; charset=utf-8
X-Frame-Options: DENY
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
ETag: W/"fffd6ab16cec9ff5e97d58a4d293073c"
Cache-Control: max-age=0, private, must-revalidate
Set-Cookie: _session_id=--4007a37778519a153aad82b63--; path=/; HttpOnly
X-Request-Id: 9c7aa92b-99b8-4e14-a87a-012d88e40608
X-Runtime: 0.230320
X-Via: 1.1 edianxin19:8 (Cdn Cache Server V2.0)
Connection: keep-alive
Content-Length: 56884
//余下报文主体...
HTTP 报文,基本还是符合 “所见即多得” 的,因为它包含的内容的的确确就是这样的。
值得强调的是 HTTP 报文的 “结构化”,是一个非常重要的特征,尤其是报文头部项,不仅是下文重点关注的对象,也是今后学习的一大重点。下图,以请求报文为例,再次感受这种 “结构化”。
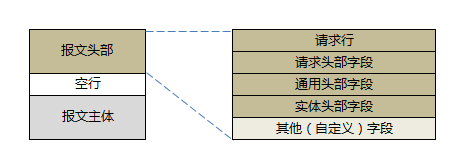
2、HTTP 的相关概念
两台计算机之间的通信是通过 TCP/IP 协议在因特网上进行的。可以借用一个 20 多年前的例子来理解,比如两个好友用信件联络,他们能建立通信的条件,一个是互相明确彼此的邮箱地址(IP),然后还需要一个邮差去分类和送达(TCP)。
IP: Internet Protocol 网际协议。每台计算机都有一个·IP,用来在 internet 上标识这台计算机。IP 协议负责将计算机之间传输的每个数据包路由至它的目的地。
TCP:Transmission Control Protocol 传输控制协议。顾名思义,是传输控制。TCP 负责在数据传送之前将它们分割为数据包,然后在它们到达的时候将它们重组,确保数据包以正确的次序到达。
HTTP 协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部(header)和请求体(body)数据。
服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部(header)和响应体(body)数据。
HTTP 是应用层协议,是基于 TCP/IP 协议之上的一种应用。作为应用层的 HTTP 协议,通信过程依次会穿越传输层、网络层、链路层。详见下图:
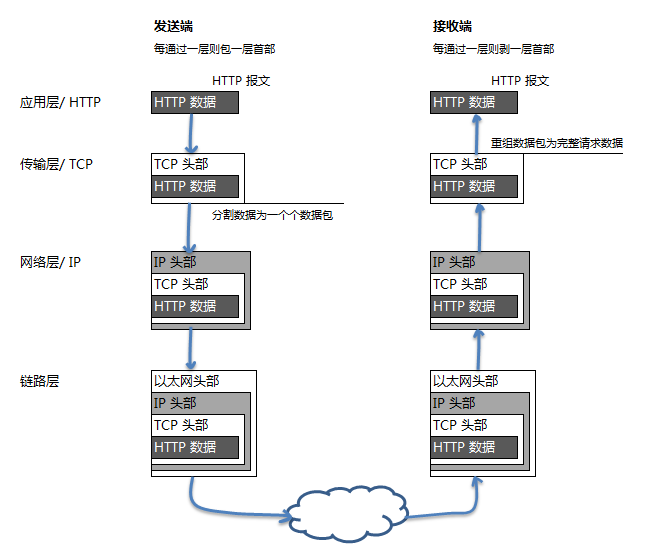
3、缩小关注范围
毫不讳言,学习 HTTP比较麻烦,除了它不像前端的其他领域知识那样 “既视感”强之外,还有就是面对一个理论性很强的知识,往往很难找到 “下口” 的地方,更别说轻易消化。而在一个信息泛滥的时代,阅后即焚、收集癖这些 “浅阅读” 形式更是我们深入掌握一些知识的头号敌人。
通常,对于获取知识,个人经验来看有这些层次:
- 最浅层次莫过于浏览、收藏
- 次浅层次是复制、截图、粘贴成笔记;
- 速成(鼓吹)的方式是听课看视频;
- 较深层次则是整理知识、梳理结构,画原理图、思维导图;
- 更为深层而牢靠的则是实践、实操中Q&A和技术交流。
我们很难掌握某些知识,包括笔者亲身体会,就是大部分都停留在第 3 阶段,很少越过第 4 阶段。
到了第 4 阶段,就应该去划分边界,缩小关注范围,然后重点突破。就好比本文的梳理,至少可以明确,现在(及今后一段时间)的注意力,就完全可以集中在 HTTP 头部项及其包含的实现原理、客户端的 API (Ajax)、服务端的 API (完全可以通过 Nodejs 模块之http.js 来学习)。
其中,HTTP 头部项,可以慢慢积累,这里暂且不谈。本文下部分主要探讨通过客户端的 Ajax 来了解浏览器和服务器间的 HTTP 通信是怎样的。
浏览器端调试 HTTP
以一个问题开始
当客户端请求被 abort(取消)掉后,浏览器和服务器分别会如何处理这个请求?
这是个好问题,它立刻激发我的探究欲望。对于这个问题的验证,只需用上两个工具——浏览器和 Fiddler 抓包工具——就能搭建一个很好的验证环境。其中,浏览器中运行的 JavaScript 脚本非常简单,如下:
var xhr = new XMLHttpRequest();
xhr.open("GET", 'http://www.vrstarman.com/stack.html', true);
//状态变更
xhr.onreadystatechange = function(e){
console.log('请求状态值变更:', xhr.readyState);
if(xhr.readyState == '2'){
//xhr.abort();
}
};
//进行中
xhr.onprogress = function(e){
console.log('请求进行时状态:', xhr.readyState);
};
//中断
xhr.onabort = function(e){
console.log('请求取消事件:', e', '此时状态值:', xhr.readyState);
};
//加载完成
xhr.onload = function(e){
console.log('请求完成事件:', e);
};
//错误
xhr.onerror = function(){
console.log('请求错误时状态:', xhr.readyState);
};
xhr.send();
问题的变量因素有:
- 在不同状态阶段
readyState阶段abort掉请求; - 在程序的不同的位置执行
abort; - 在这些
abort测试中,验证的url分别为以下情形:- [v] 一个实际存在的 url
- [ ] 一个不存在的 url
- [ ] 一个跨域的 url
本文就用的首页地址http://www.jianshu.com/ 测试了第一种情形,并且已经收获颇丰。可以推测第二种情形和第一种差不多,但第三种会不同,非常值得验证。
验证结果及分析
| readyState | 状态含义解析 | abort 位置 |
|---|---|---|
| 0 | 请求未初始化, 即 open() 前的状态 |
此时 abord,后续方法抛出错误 |
| 1 | 请求已经建立,但是还未send(),此时打印状态是1。 send()之后打印状态,结果还是1 (按理说应该是 2),可见状态变更是滞后的,说明是异步的 |
在 open()之后 send()之前 abord,会报错,故用try{ xhr.send(); }catch(e){ }捕捉错误 |
| 2 | 请求已send(),正在处理中,并已经接收到响应数据(通常浏览器可从响应中解析出请求头、响应头) |
鉴于异步执行,将 xhr.abord() 放在 onreadystatechange 事件中 |
| 3 | 响应数据仍在接收和处理中,响应 body 已部分解析,但服务器还未全部发送完或浏览器还未全部解析完 |
在 readyState == 3 下 abord(),由于异步执行的原因,实际请求已接近(或达到)状态 4 |
| 4 | 响应已完成接收和解析,可获取并使用所有响应内容 | 从以上操作看,一个请求,只要不在状态 2 之前取消,都会经历完整的响应阶段,即完成状态 4 |
进一步详细解读
达到了不同的状态值,浏览器和服务器都分别做了哪些动作,以下是上述探索的详细解读。
状态为 0
状态为
0是被大多浏览器隐藏的。只在浏览器端new出了xhr对象,但还未建立连接就中断请求是没有意义的。
状态为 1
结果是无任何请求发出,且 打印的
readyState为0。
为什么还是0?虽然open()已执行,但因立即打印状态,还没有收到已建立连接的返回消息,故立即打印的状态是变更前的。
Fiddler 此时未显示任何http请求。
浏览器显示Provisional headers are shown,这与浏览器的可视化机制有关,真实情况浏览器并未发送请求。
状态为 2
readyState状态值变更滞后(因为异步),给判断带来干扰
但测试表明放在onreadystatechange事件中的abord(),会导致readyState值从2“跳” 到4。
浏览器已成功发送请求,并成功的解析了请求头、响应头。
Fiddler 监测出了http请求,表明服务器已成功发送请求数据。
但因为手动abord(),导致浏览器接收到了(部分甚至可能全部)响应但放弃了解析响应的body,所以页面无数据显示。
状态为 3
尽管是中途
abord(),但readyState完整经历4个状态变化。
onprogress事件只激发了2次。
浏览器处于一个不确定是否完全解析响应的状态中,反复测试并打印xhr.response会发现有时解析了完整的数据,有时则在中间产生了中断。
服务器已经确定发出了(几乎)所有响应内容。
由于在状态4前中断,浏览器未确切是否已完成全部接收和解析,故在浏览器控制台的 Preview 中无法看到内容。
状态为 4
abord会导致xhr.response和xhr.responseText被清空。
服务器端全部响应也发送完毕。
浏览器已经全部接受、并完成解析,这在浏览器控制台的 Preview中能看到。
但还是因为abord(),导致了对响应body内容的情况,所以还是无法最终显示在document中。除非在abord()前执行document.write(xhr.response);
其中,对 readyState == 2 即 abord() 的情形,服务器到底有没有响应,若有,响应了什么内容?因为从浏览器的控制台无从确认,对于这一步的存疑,还好可以借助 Fiddler 的拦截,一目了然。
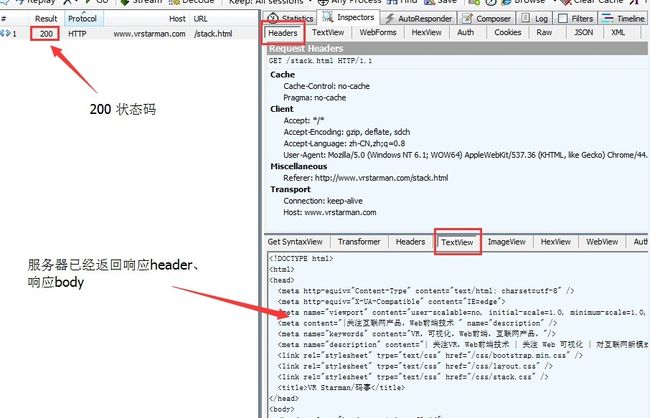
对于跨域的 url ,在下不同 HTTP 请求阶段被 abord 情况的探索,就暂不描述了。强烈建议读者一并探索下。
另外,HTTP 头部项、以及 HTTP 服务端的一些特性的学习,后续找时间再写。