- Spark Core是基于RDD形成的,RDD之间都会有依赖关系。而Spark Streaming是在RDD之上增加了时间维度,DStream就是RDD的模板,随着时间的流逝不断地实例化DStream,以数据进行填充DStream。DStream的依赖关系构成Dstream Graph,根据DStream Graph的依赖转换成RDD的依赖。DStream Graph就是静态的RDD DAG模板。
- DStream之是逻辑级别,而RDD才是物理级别。Dstrem只是在RDD的基础上加上了时间的维度,所以整个Spark Streaming就是时空维度。
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]] ()
- DStream在计算的时候compute需要传入一个时间参数,通过时间获取相应的RDD,然后再对RDD进行计算
def compute(validTime: Time): Option[RDD[T]]
- 我们运行一个简单的Spark Streaming例子
objectNetworkWordCount {
defmain(args:Array[String]) {
if (args.length< 2) {
System.err.println("Usage: NetworkWordCount ")
System.exit(1)
}
val sparkConf= newSparkConf().setAppName("NetworkWordCount").setMaster("local[2]")
val ssc = newStreamingContext(sparkConf,Seconds(1))
val lines= ssc.socketTextStream(args(0), args(1).toInt,StorageLevel.MEMORY_AND_DISK_SER)
val words= lines.flatMap(_.split(""))
val wordCounts= words.map(x => (x,1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
我们查看SparkStreaming的运行日志,就可以看出和RDD的运行几乎是一致的:
2016-05-20 06:54:10,056 INFO [JobScheduler] scheduler.JobScheduler (Logging.scala:logInfo(58)) - Finished job streaming job 1463698450000 ms.0 from job set of time 1463698450000 ms
2016-05-20 06:54:10,056 INFO [JobScheduler] scheduler.JobScheduler (Logging.scala:logInfo(58)) - Total delay: 0.056 s for time 1463698450000 ms (execution: 0.044 s)
2016-05-20 06:54:10,057 INFO [JobGenerator] rdd.ShuffledRDD (Logging.scala:logInfo(58)) - Removing RDD 4 from persistence list
2016-05-20 06:54:10,062 INFO [JobGenerator] rdd.MapPartitionsRDD (Logging.scala:logInfo(58)) - Removing RDD 3 from persistence list
2016-05-20 06:54:10,062 INFO [block-manager-slave-async-thread-pool-0] storage.BlockManager (Logging.scala:logInfo(58)) - Removing RDD 4
2016-05-20 06:54:10,062 INFO [block-manager-slave-async-thread-pool-1] storage.BlockManager (Logging.scala:logInfo(58)) - Removing RDD 3
2016-05-20 06:54:10,063 INFO [JobGenerator] rdd.MapPartitionsRDD (Logging.scala:logInfo(58)) - Removing RDD 2 from persistence list
2016-05-20 06:54:10,063 INFO [block-manager-slave-async-thread-pool-2] storage.BlockManager (Logging.scala:logInfo(58)) - Removing RDD 2
2016-05-20 06:54:10,064 INFO [JobGenerator] rdd.BlockRDD (Logging.scala:logInfo(58)) - Removing RDD 1 from persistence list
2016-05-20 06:54:10,067 INFO [block-manager-slave-async-thread-pool-7] storage.BlockManager (Logging.scala:logInfo(58)) - Removing RDD 1
2016-05-20 06:54:10,067 INFO [JobGenerator] dstream.SocketInputDStream (Logging.scala:logInfo(58)) - Removing blocks of RDD BlockRDD[1] at socketTextStream at NetworkWordCount.scala:21 of time 1463698450000 ms
2016-05-20 06:54:10,068 INFO [JobGenerator] scheduler.ReceivedBlockTracker (Logging.scala:logInfo(58)) - Deleting batches ArrayBuffer()
2016-05-20 06:54:10,068 INFO [JobGenerator] scheduler.InputInfoTracker (Logging.scala:logInfo(58)) - remove old batch metadata:
2016-05-20 06:54:15,015 INFO [Spark Context Cleaner] spark.ContextCleaner (Logging.scala:logInfo(58)) - Cleaned accumulator 5
2016-05-20 06:54:15,015 INFO [JobGenerator] scheduler.JobScheduler (Logging.scala:logInfo(58)) - Added jobs for time 1463698455000 ms
2016-05-20 06:54:15,016 INFO [dispatcher-event-loop-0] storage.BlockManagerInfo (Logging.scala:logInfo(58)) - Removed broadcast_4_piece0 on localhost:62612 in memory (size: 1626.0 B, free: 1311.0 MB)
2016-05-20 06:54:15,016 INFO [JobScheduler] scheduler.JobScheduler (Logging.scala:logInfo(58)) - Starting job streaming job 1463698455000 ms.0 from job set of time 1463698455000 ms
2016-05-20 06:54:15,020 INFO [streaming-job-executor-0] spark.SparkContext (Logging.scala:logInfo(58)) - Starting job: print at NetworkWordCount.scala:26
2016-05-20 06:54:15,021 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Registering RDD 11 (map at NetworkWordCount.scala:25)
2016-05-20 06:54:15,021 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Got job 5 (print at NetworkWordCount.scala:26) with 1 output partitions
2016-05-20 06:54:15,021 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Final stage: ResultStage 10 (print at NetworkWordCount.scala:26)
2016-05-20 06:54:15,021 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Parents of final stage: List(ShuffleMapStage 9)
2016-05-20 06:54:15,021 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Missing parents: List()
2016-05-20 06:54:15,022 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Submitting ResultStage 10 (ShuffledRDD[12] at reduceByKey at NetworkWordCount.scala:25), which has no missing parents
2016-05-20 06:54:15,024 INFO [dag-scheduler-event-loop] storage.MemoryStore (Logging.scala:logInfo(58)) - Block broadcast_5 stored as values in memory (estimated size 2.6 KB, free 60.9 KB)
2016-05-20 06:54:15,026 INFO [dag-scheduler-event-loop] storage.MemoryStore (Logging.scala:logInfo(58)) - Block broadcast_5_piece0 stored as bytes in memory (estimated size 1627.0 B, free 62.5 KB)
2016-05-20 06:54:15,027 INFO [dispatcher-event-loop-2] storage.BlockManagerInfo (Logging.scala:logInfo(58)) - Added broadcast_5_piece0 in memory on localhost:62612 (size: 1627.0 B, free: 1311.0 MB)
2016-05-20 06:54:15,027 INFO [dag-scheduler-event-loop] spark.SparkContext (Logging.scala:logInfo(58)) - Created broadcast 5 from broadcast at DAGScheduler.scala:1006
2016-05-20 06:54:15,027 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Submitting 1 missing tasks from ResultStage 10 (ShuffledRDD[12] at reduceByKey at NetworkWordCount.scala:25)
2016-05-20 06:54:15,028 INFO [dag-scheduler-event-loop] scheduler.TaskSchedulerImpl (Logging.scala:logInfo(58)) - Adding task set 10.0 with 1 tasks
2016-05-20 06:54:15,028 INFO [dispatcher-event-loop-3] scheduler.TaskSetManager (Logging.scala:logInfo(58)) - Starting task 0.0 in stage 10.0 (TID 5, localhost, partition 0,PROCESS_LOCAL, 1894 bytes)
2016-05-20 06:54:15,029 INFO [Executor task launch worker-1] executor.Executor (Logging.scala:logInfo(58)) - Running task 0.0 in stage 10.0 (TID 5)
2016-05-20 06:54:15,031 INFO [Executor task launch worker-1] storage.ShuffleBlockFetcherIterator (Logging.scala:logInfo(58)) - Getting 0 non-empty blocks out of 0 blocks
2016-05-20 06:54:15,031 INFO [Executor task launch worker-1] storage.ShuffleBlockFetcherIterator (Logging.scala:logInfo(58)) - Started 0 remote fetches in 0 ms
2016-05-20 06:54:15,032 INFO [Executor task launch worker-1] executor.Executor (Logging.scala:logInfo(58)) - Finished task 0.0 in stage 10.0 (TID 5). 1161 bytes result sent to driver
2016-05-20 06:54:15,033 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - ResultStage 10 (print at NetworkWordCount.scala:26) finished in 0.005 s
2016-05-20 06:54:15,033 INFO [task-result-getter-0] scheduler.TaskSetManager (Logging.scala:logInfo(58)) - Finished task 0.0 in stage 10.0 (TID 5) in 5 ms on localhost (1/1)
2016-05-20 06:54:15,034 INFO [task-result-getter-0] scheduler.TaskSchedulerImpl (Logging.scala:logInfo(58)) - Removed TaskSet 10.0, whose tasks have all completed, from pool
2016-05-20 06:54:15,034 INFO [streaming-job-executor-0] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Job 5 finished: print at NetworkWordCount.scala:26, took 0.013596 s
2016-05-20 06:54:15,040 INFO [Spark Context Cleaner] spark.ContextCleaner (Logging.scala:logInfo(58)) - Cleaned accumulator 6
2016-05-20 06:54:15,041 INFO [dispatcher-event-loop-1] storage.BlockManagerInfo (Logging.scala:logInfo(58)) - Removed broadcast_5_piece0 on localhost:62612 in memory (size: 1627.0 B, free: 1311.0 MB)
2016-05-20 06:54:15,043 INFO [streaming-job-executor-0] spark.SparkContext (Logging.scala:logInfo(58)) - Starting job: print at NetworkWordCount.scala:26
2016-05-20 06:54:15,044 INFO [dag-scheduler-event-loop] spark.MapOutputTrackerMaster (Logging.scala:logInfo(58)) - Size of output statuses for shuffle 2 is 82 bytes
2016-05-20 06:54:15,044 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Got job 6 (print at NetworkWordCount.scala:26) with 1 output partitions
2016-05-20 06:54:15,044 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Final stage: ResultStage 12 (print at NetworkWordCount.scala:26)
2016-05-20 06:54:15,044 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Parents of final stage: List(ShuffleMapStage 11)
2016-05-20 06:54:15,044 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Missing parents: List()
2016-05-20 06:54:15,045 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Submitting ResultStage 12 (ShuffledRDD[12] at reduceByKey at NetworkWordCount.scala:25), which has no missing parents
2016-05-20 06:54:15,046 INFO [dag-scheduler-event-loop] storage.MemoryStore (Logging.scala:logInfo(58)) - Block broadcast_6 stored as values in memory (estimated size 2.6 KB, free 60.9 KB)
2016-05-20 06:54:15,048 INFO [dag-scheduler-event-loop] storage.MemoryStore (Logging.scala:logInfo(58)) - Block broadcast_6_piece0 stored as bytes in memory (estimated size 1627.0 B, free 62.5 KB)
2016-05-20 06:54:15,050 INFO [dispatcher-event-loop-0] storage.BlockManagerInfo (Logging.scala:logInfo(58)) - Added broadcast_6_piece0 in memory on localhost:62612 (size: 1627.0 B, free: 1311.0 MB)
2016-05-20 06:54:15,050 INFO [dag-scheduler-event-loop] spark.SparkContext (Logging.scala:logInfo(58)) - Created broadcast 6 from broadcast at DAGScheduler.scala:1006
2016-05-20 06:54:15,050 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Submitting 1 missing tasks from ResultStage 12 (ShuffledRDD[12] at reduceByKey at NetworkWordCount.scala:25)
2016-05-20 06:54:15,050 INFO [dag-scheduler-event-loop] scheduler.TaskSchedulerImpl (Logging.scala:logInfo(58)) - Adding task set 12.0 with 1 tasks
2016-05-20 06:54:15,051 INFO [dispatcher-event-loop-3] scheduler.TaskSetManager (Logging.scala:logInfo(58)) - Starting task 0.0 in stage 12.0 (TID 6, localhost, partition 1,PROCESS_LOCAL, 1894 bytes)
2016-05-20 06:54:15,052 INFO [Executor task launch worker-1] executor.Executor (Logging.scala:logInfo(58)) - Running task 0.0 in stage 12.0 (TID 6)
2016-05-20 06:54:15,054 INFO [Executor task launch worker-1] storage.ShuffleBlockFetcherIterator (Logging.scala:logInfo(58)) - Getting 0 non-empty blocks out of 0 blocks
2016-05-20 06:54:15,054 INFO [Executor task launch worker-1] storage.ShuffleBlockFetcherIterator (Logging.scala:logInfo(58)) - Started 0 remote fetches in 1 ms
2016-05-20 06:54:15,055 INFO [Executor task launch worker-1] executor.Executor (Logging.scala:logInfo(58)) - Finished task 0.0 in stage 12.0 (TID 6). 1161 bytes result sent to driver
2016-05-20 06:54:15,055 INFO [task-result-getter-1] scheduler.TaskSetManager (Logging.scala:logInfo(58)) - Finished task 0.0 in stage 12.0 (TID 6) in 4 ms on localhost (1/1)
2016-05-20 06:54:15,056 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - ResultStage 12 (print at NetworkWordCount.scala:26) finished in 0.004 s
2016-05-20 06:54:15,056 INFO [task-result-getter-1] scheduler.TaskSchedulerImpl (Logging.scala:logInfo(58)) - Removed TaskSet 12.0, whose tasks have all completed, from pool
2016-05-20 06:54:15,056 INFO [streaming-job-executor-0] scheduler.DAGScheduler (Logging.scala:logInfo(58)) - Job 6 finished: print at NetworkWordCount.scala:26, took 0.012564 s
-
动态的job控制器会根据我们设定的时间间隔收集到数据,让静态的Dstream Graph活起来,而来不断产生job执行。job的具体生成在以后介绍
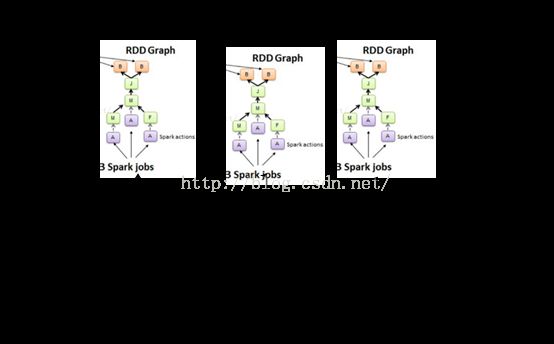
- 如果数据处理不过来,就可以限流,Spark Streaming在运行的过程中可以动态地调整自己的资源,具体内容以后介绍