1. 马尔可夫链
马尔可夫链是满足马尔可夫性质的随机过程。马尔可夫性质是无记忆性。
也就是说,这一时刻的状态,受且只受前一时刻的影响,而不受更往前时刻的状态的影响。我们下面说的隐藏状态序列就马尔可夫链。
2. 隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,用它处理的问题一般有两个特征:
第一:问题是基于序列的,比如时间序列,或者状态序列。
第二:问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观测到的,即隐藏状态序列,简称状态序列,该序列是马尔可夫链,由于该链不能直观观测,所以叫“隐”马尔可夫模型。
简单地说,状态序列前项能算出后项,但观测不到,观测序列前项算不出后项,但能观测到,观测序列可由状态序列算出。
HMM模型的主要参数是λ=(A,B,Π),数据的流程是通过初始状态Pi生成第一个隐藏状态h1,h1结合生成矩阵B生成观测状态o1,h1根据转移矩阵A生成h2,h2和B再生成o2,以此类推,生成一系列的观测值。
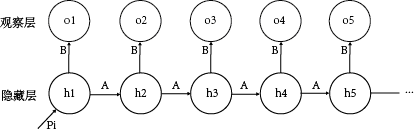
3. 举例
1) 问题描述
假设我关注了一支股票,它背后有主力高度控盘,我只能看到股票涨/跌(预测值:2种取值),看不到主力的操作:卖/不动/买(隐藏值:3种取值)。涨跌受主力操作影响大,现在我知道一周之内股票的涨跌,想推测这段时间主力的操作。假设我知道有以下信息:
i. 观测序列O={o1,o2,...oT}
一周的涨跌O={1, 0, 1, 1, 1}
ii. HMM模型λ=(A,B,Π)
- 隐藏状态转移矩阵A
主力从前一个操作到后一操作的转换概率A={{0.5, 0.3, 0.2},{0.2, 0.5, 0.3},{0.3, 0.2, 0.5}} - 隐藏状态对观测状态的生成矩阵B(3种->2种)
主力操作对价格的影响B={{0.6, 0.3, 0.1},{0.2, 0.3, 0.5}} - 隐藏状态的初始概率分布Pi(Π)
主力一开始的操作的可能性Pi={0.7, 0.2, 0.1}
2) 代码
import numpy as np
from hmmlearn import hmm
states = ["A", "B", "C"]
n_states = len(states)
observations = ["down","up"]
n_observations = len(observations)
p = np.array([0.7, 0.2, 0.1])
a = np.array([
[0.5, 0.2, 0.3],
[0.3, 0.5, 0.2],
[0.2, 0.3, 0.5]
])
b = np.array([
[0.6, 0.2],
[0.3, 0.3],
[0.1, 0.5]
])
o = np.array([[1, 0, 1, 1, 1]]).T
model = hmm.MultinomialHMM(n_components=n_states)
model.startprob_= p
model.transmat_= a
model.emissionprob_= b
logprob, h = model.decode(o, algorithm="viterbi")
print("The hidden h", ", ".join(map(lambda x: states[x], h)))
c) 分析
这里我们使用了Python的马尔可夫库hmmlearn,可通过命令 $ pip install hmmlearn安装(sklearn的hmm已停止更新,无法正常使用,所以用了hmmlearn库)
马尔可夫模型λ=(A,B,Π),A,B,Π是模型的参数,此例中我们直接给出,并填充到模型中,通过观测值和模型的参数,求取隐藏状态。
4. HMM的具体算法
第一:根据当前的观测序列求解其背后的状态序列,即示例中decode()函数(Viterbi方法)。
第二:根据模型λ=(A,B,Π),求当前观测序列O出现的概率(向前向后算法)
第三:给出几组观测序列O,求模型λ=(A,B,Π)中的参数(Baum-Welch方法)。具体方法是随机初始化模型参数A,B,Π;用样本O计算寻找更合适的参数;更新参数,再用样本拟合参数,直至参数收敛。
在实际使用中,比如语音识别,我们先用一些已有的观测数据O,训练模型λ的参数,然后用训练好的模型λ估计新的输入数据O出现的概率。
至此,我们介绍了HMM的核心操作及对应算法,如果你对具体的Viterbi或者Baum-Welch算法的实现感兴趣,推荐以下两篇文章,一篇是算法公式及说明,一篇是具体Python代码实现,建议对照着看:
http://www.cnblogs.com/hanahimi/p/4011765.html
http://www.cnblogs.com/pinard/p/6945257.html
5. 最大期望EM算法
EM(Expectation Maximization)最大期望算法是十大数据挖掘经典算法之一。之前一直没见过EM的实现工具和应用场景,直到看见HMM的具体算法。HMM的核心算法是通过观测值计算模型参数,具体使用Baum-Welch算法,它是EM的具体实现,下面来看看EM算法。
假设条件是X,结果是Y,条件能推出结果X->Y,但结果推不出条件,现在手里有一些对结果Y的观测值,想求X,那么我们举出X的所有可能性,再使用X->Y的公式求Y,看哪个X计算出的Y和当前观测最契合,就选哪个X。这就是最大似然的原理。在数据多的情况下,穷举因计算量太大而无法实现,最大期望EM是通过迭代逼近方式求取最大似然。
EM算法分为两个步骤:E步骤是求在当前参数值和样本下的期望函数,M步骤利用期望函数调整模型中的估计值,循环执行E和M直到参数收敛。
6. 隐马尔可夫模型HMM与循环神经网络RNN&LSTM
RNN是循环神经网络,LSTM是RNN的一种优化算法,近年来,RNN在很多领域取代了HMM。下面我们来看看它们的异同。
首先,RNN和HMM解决的都是基于序列的问题,也都有隐藏层的概念,它们都通过隐藏层的状态来生成可观测状态。
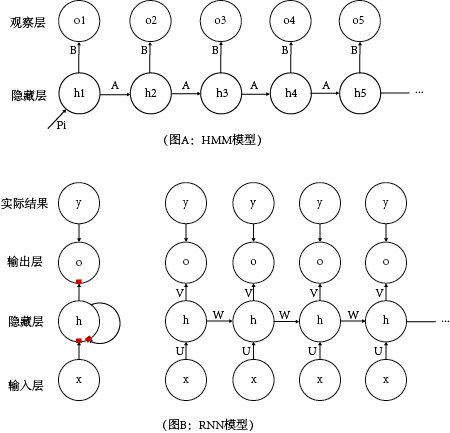
从对比图中可以看出,它们的数据流程很相似(Pi与U,A与W,B与V对应),调参数矩阵的过程都使用梯度方法(对各参数求偏导),RNN利用误差函数在梯度方向上调U,V,W(其中还涉及了激活函数),而HMM利用最大期望在梯度方向上调Pi,A,B(Baum-Welch算法),调参过程中也都用到类似学习率的参数。
不同的是,RNN中使用激活函数(红色方块)让该模型的表现力更强,以及LSTM方法修补了RNN中梯度消失的问题;相对来说RNN框架也更加灵活。
RNN和HMM不是完全不同的两类算法,它们有很多相似之处,我们也可以把RNN看成HMM的加强版。