前言
SynchronousQueue作为BlockingQueue体系中的一员,它与我们平常使用较多的ArrayBlockingQueue、LinkedBlockingQueue有着较大的差异,与此同时,它在实现的细节上也比前面的两个队列要复杂的多。在分析的过程中,如果有大神发现有不对之处,还望及时指正!
SynchrnousQueue基本介绍
SynchronousQueue主要有如下的特点:
- SynchronousQueue的容量为0,因此它是无法用于数据的存储。
- 每一次向队列中执行写操作时,写线程都会等待;直到另一个线程去执行读操作时,写线程才会返回;反之亦然,并且写入的元素不允许为null。
- 由于SynchronousQueue的容量为0,根本没有存储任何数据,因此执行peek方法返回队列中的元素时,总是返回null;如果执行迭代操作,同样也是没有任何元素可以迭代。
- SynchronousQueue将put、take两个截然不同的方法,统一抽象成一个transfer方法来进行处理,主要是根据方法的参数来判断是执行take操作还是put操作。
- SynchronousQueue和ReentrantLock类似,提供了公平与非公平两种策略的处理实现,其分别是基于队列与栈来进行实现,一个是
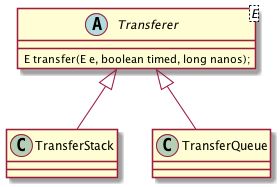
TransferQueue,另一个是TransferStack,它们都分别实现了Transferer接口,然后实现transfer方法。 后面我们会详细分析其具体的实现细节。
从上面对SynchronousQueue所描述的特点中可以看出,我们称其为一个阻塞队列,然而实际上它更像是一个数组交换的通道。我们看下API文档对使用场景的说明:

SynchronousQueue非常适合于"手递手传递"地设计,某个线程在执行操作时必须同步等待,直到其他的线程执行相反的操作才会返回,从而实现消息、事件、任务的传递。这种特征也正印证了SynchronousQueue的名字——同步队列。Executors线程池工具类所创建的cachedThreadPool,其底层就是使用SynchronousQueue来作为其缓冲任务的阻塞队列。
Transferer接口分析
上面我们已经提到,SynchronousQueue底层的TransferQueue和TransferQueue都是基于Transferer接口来进行实现的。下面我们先来看一下Transfer接口的说明:
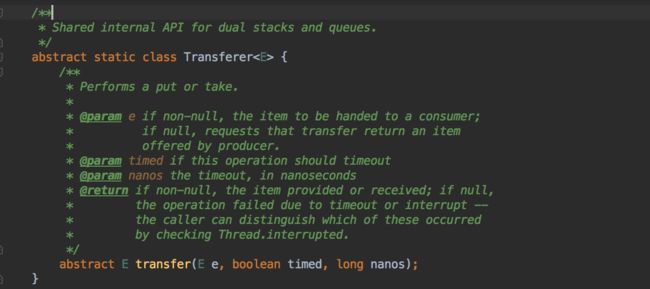
Transferer是定义在SynchronousQueue内部的共享API,它将put和task操作统一收敛到transfer方法中进行处理。如果当传入的e为非空,表示当前传递给一个消费者进行处理,如果e为空,则表示当前操作需要请求一个由生产者所提供的数据。timeout用于表示当前操作是否存在超时,nanos则表示超时的毫秒数。如果返回值为非空,则表示元素已经提供或者已经接受;如果返回的结果为空,则表示该次操作执行失败,其失败可能是因为超时或者线程中断而导致的,方法的调用者可以通过使用Thread.interrupted方法来判断失败的原因。

可以看到,无论是take,还是put、offer等操作,都是通过间接调用transfer方法来完成的。在SynchronousQueue内部,提供了两个子类TransferStack和TransferQueue。
SynchronousQueue的构造
private transient volatile Transferer transferer;
public SynchronousQueue() {
// 默认情况下,采用非公平的策略
this(false);
}
public SynchronousQueue(boolean fair) {
// 如果是公平策略,那么则使用队列来实现,否则就使用栈来实现
transferer = fair ? new TransferQueue() : new TransferStack();
}
SynchronousQueue的构造过程非常的简单,就是根据传入的策略,判断是否公平模式。如果是,就创建TransferQueue,否则就创建TransferStack。下面对于TransferQueue、TransferStack的实现将是我们研究的重点。
TransferQueue源码分析
由于TransferQueue的实现比起TransferStack要稍微简单一些,所以我们在这里先分析TransferQueue。前面我们已经介绍了TransferQueue是Synchronous在公平模式下的具体实现,其内存存储的数据被称之为QNode。无论是在执行put还是take操作,当执行线程需要同步等待一个互补的操作发生时,那么当前操作就会被包装成一个QNode,然后将节点添加到队列中进行等待,直到有一个与当前操作互补的操作发生,紧接着队列中的节点就会出队列,之前等待的线程也随之继续执行。
下图是TransferQueue的结构:

基于队列的transfer方法实现分析
在了解完TransferQueue的基本结构之后,下面我们来看一下TransferQueue的transfer方法是如何统一put与take操作的。其实现的基本思路是,通过在一个循环中,反复地执行如下的两个操作:
如果队列为空或者队列中已经包含了与当前操作模式相同的节点,此时线程就需要同步等待,那么就尝试将当前操作包装成一个QNode节点,添加到队列中;然后等待与当前操作互补的操作发生(比如当前是一个写操作,那么就等待一个读操作发生,反之亦然),并且返回节点的元素;如果在入队列的过程中,操作取消,那么也会返回。
如果队列中包含了与当前操作互补的等待节点,那么就尝试通过CAS操作更新等待节点的item字段,让后让等待节点出队列。
在上面整个过程中,SynchronousQueue并不会用到任何的锁机制,全部依赖CAS+LockSupport来完成线程并发操作与等待的处理。下面我们就分析一下transfer方法的具体实现。
transfer
E transfer(E e, boolean timed, long nanos) {
QNode s = null;
// 根据元素是否为空来判断当前是读操作还是写操作,如果是写,则isData为true,否则为false
boolean isData = (e != null);
for (;;) {
QNode t = tail; // 记录队列的尾部节点
QNode h = head; // 记录队列的头部节点
/*
* 首先检查一下队列是否初始化完成,如果未完成,则进行自旋,一直等到节点初始化完成
* 因为TransferQueue中的head和tail都是volatile的,因此不会出现在执行transfer方法时为空的情况
* 这里的判断目的仅仅是为了防止如果head和tail为非volatile的场景
*/
if (t == null || h == null)
continue;
/*
* 如果队列为空,即head等于tail的情况;或者tail节点的操作与当前操作一样
* 比如前面调用的线程执行的是写操作,当前线程执行的也是写操作
* 此时满足上面所说的第一种情况
*/
if (h == t || t.isData == isData) {
//记录tail节点的next节点
QNode tn = t.next;
// 如果出现t不等于tail情况,则意味着读不一致的情况
// 因为前面tail是由t赋值而来,而现在t却不等于tail,则两次读取结果不一样,此时也会进行自旋重试
// 该情况出现的可能是因为多个线程并发入队列时,一开始大家都将tail赋值给t,然后A线程将自己的节点添加到队列中
// 此时A线程新添加的节点就称为了新的tail节点,此时B线程再去比较的时候,就发现前后不一致,因此它会重新尝试进行入队列操作
if (t != tail)
continue;
/*
* 如果tail节点的next不为空,该情况下只有在多线程并发的情况下出现
* 比如此时两个写操作同时执行,它们都需要进行入队列,当B线程在获取t.next之前
* A线程已将自己的节点设置为原来tail的next,即tn节点,因此导致B线程通过tn不为空
* 注意:此时A线程只是将自己节点设置为tail的next,但是并未将自己的节点设置为tail
*/
if (tn != null) {
/* 这里我们假设当前执行的线程是B线程
* 此时A线程只是将新节点设置为原来tail的next,但是未将新节点设置为tail
* 因此B线程帮助A线程将它的节点设置为新的tail节点,这里仅仅是帮助操作而已
* B线程在帮助A线程的过程中,A线程可能已经完成了tail节点的设置
* 因为在 advanceTail中会首先判断t == tail,只有在成功的时候,才会尝试CAS操作,从而减少一次无畏的操作开销。
* B线程在尝试帮助A线程之后,自己需要重新进行节点的入队列操作
*/
advanceTail(t, tn);
continue;
}
// 如果设置了定时,但是定时的时间小于等于0,则直接返回null
if (timed && nanos <= 0)
return null;
// 此时创建新的节点s,后续准备让s进入队列
if (s == null)
s = new QNode(e, isData);
// 执行cas操作,设置s节点为t节点的next,如果执行失败,也是因为多个线程并发入队列的时候而导致
// 因此执行失败的线程需要进行入队列操作的重试,不过在下一次入队列的时候,它可以继续延用刚刚创建的s节点,而无需再重复创建
if (!t.casNext(null, s))
continue;
// 设置s节点为新的tail节点
advanceTail(t, s);
/*
* 等待fulfill发生,该方法会让当前执行线程等待,直到有一个模式互补的节点出现
* 比如当前节点是读节点,那么就必须等到一个写操作发生,并且让该读节点出队列,
* awaitFulfill操作在下面分析
*/
Object x = awaitFulfill(s, e, timed, nanos);
// 当执行等待返回之后,如果返回的结果等于节点本身,那么此时说明在等待的过程中执行线程发生了中断或者执行超时
// 如果x不等于s,则返回的是数据,如果当前s节点是一个写操作,则x为null,如果是读操作,则x为其读取到的数据
if (x == s) {
// 由于节点已经取消,此时会将节点从队列中移除,然后返回null,clean操作在后面分析
clean(t, s);
return null;
}
// 判断s节点是否已经从队列中断开,判断的方式即通过s.next是否等于自己
if (!s.isOffList()) {
// 尝试设置s节点为新的head节点,这里仅仅只是尝试操作而已
advanceHead(t, s);
// 如果x不等于null,则说明s节点是一个读操作的节点
if (x != null)
// 通过设置s的item等于自己,来清除原来的数据
s.item = s;
// 由于s节点的线程此时已经继续执行,因此清除节点的等待线程
s.waiter = null;
}
// 如果x不为null,则表示当前节点为读节点,因此返回其读取到的数据,如果为null,则为写节点,因此返回其写入的数据,即e。
return (x != null) ? (E)x : e;
}
else {
// 此时出现节点互补模式,队列中已经包含了与当前操作互补的节点
// 即上面所说的第二种情况
QNode m = h.next; // 获取头部节点的next,去执行fulfill操作
if (t != tail || m == null || h != head)
continue; // inconsistent read
Object x = m.item;
if (isData == (x != null) || // m节点已经存在与之互补节点,此时发生在前面有一个节点在take等待,此时两个线程同时并发地执行put
x == m || // m节点的元素等于节点自己,则说明操作已经取消
!m.casItem(x, e)) { // 更新m节点的item属性,如果执行失败,则由于多线程并发操作时所引起
advanceHead(h, m); // 将m节点设置新的头节点,这里也只是尝试帮助
continue;
}
// 将m节点设置为head节点,此时已经完成让模式互补的出队列操作
advanceHead(h, m);
// 让队列中等待的线程继续执行
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
}
}
awaitFulfill
通过上面分析transfer的过程,我们已经知道如果当线程发现当前队列为空或者当前队列中已经存在模式相同的节点,线程则会尝试进入等待状态,下面我们分析下线程等待的过程:
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
// 判断当前操作是否存在超时,如果存在,则计算出截止时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 获取到当前的执行线程
Thread w = Thread.currentThread();
/*
* 如果当前入队列的节点是head的next节点,当前节点一定是第一个出队列的节点,此时会让其进行自旋
* 这样的目的是在于当队列非常繁忙的情况下,因为在入队列的过程中,很有可能它的"互补操作"在下一时刻就发生了,通过自旋就可以去减少线程被挂起的可能
* 如果当前节点不是head的next节点,则说明前面还有节点拍着队伍需要依次出队列,因此它就无需自旋,直接入队列即可
*/
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
/*
* 判断当前线程是否已经中断,如果在等待的过程中线程发生中断,则取消该操作
* 此时即将节点的item设置为节点本身
*/
if (w.isInterrupted())
s.tryCancel(e);
Object x = s.item;
// 如果节点的item发生了改变,则说明操作已经取消,直接返回
if (x != e)
return x;
if (timed) {
//判断节点是否超时,如果超时,也取消当前等待操作
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
if (spins > 0)
//每一次自旋操作之后,都将标记值减1
--spins;
else if (s.waiter == null)
// 设置需要等待的线程
s.waiter = w;
else if (!timed)
//让线程等待
LockSupport.park(this);
// 如果在自旋了maxTimedSpins次之后,依旧没有超时,则先让线程等待给定的时间
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
clean
在分析完入队列过程以及等待的过程之后,下面我们来看下节点clean的处理。在SynchronousQueue中清除节点有一个比较特别的处理,即如果队列的尾部发生cancel,它不会去直接删除该节点,而是将尾部节点的前面那个节点标记为cleanMe节点。源码中并没有直接说明这样做的目的,这里我说一下个人的理解,未必完全正确。因为删除尾部节点会涉及到如下的2个操作:
(1). 将pred设置为新的tail
(2). 将pred的next设置为null
此时如果假设pred设置为了新的tail,在其设置next为null的时候,新的节点入队列
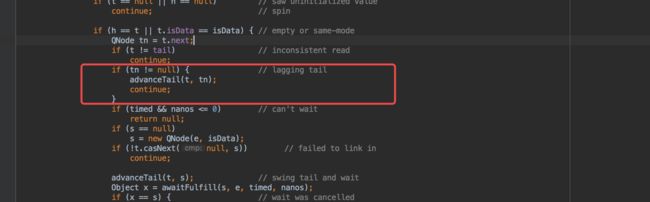
它发现tail的next不为null,就会试图帮助tail的next成为新的tail,这样就导致cancel的节点重新成为了tail,这种并发的场景是非常的不可控的,因此这里采取标记,延迟删除的策略。
void clean(QNode pred, QNode s) {
s.waiter = null; // forget thread
while (pred.next == s) { // Return early if already unlinked
QNode h = head;
QNode hn = h.next;
//情况1:首先判断head节点的next是否已经取消
if (hn != null && hn.isCancelled()) {
//如果取消,则将后面的节点作为新的head,然后将head的next设置为自己,这样原来的head节点就从队列中移除了
advanceHead(h, hn);
//再次循环的时候,由于pred等于原来的head,不再等于s,它的next因为上面的这步操作而改变了,因此它就节点完成了出队列的操作
continue;
}
// 为了确保读取的一致性,首先获取当前的tail节点,因为在后续的执行过程中,由于其他节点再次入队列,会导致tail节点发生变化
QNode t = tail;
// 如果head==tail,则说明队列为空,则直接跳出循环返回
if (t == h)
return;
// 获取tail的next,如果后面判断tn不为null,则说明在刚才的执行过程中,又有新的节点加入到了队列中
QNode tn = t.next;
// tail节点发生变化,即新的节点加入到队列中
if (t != tail)
continue;
// tn不等于空,也意味着新的节点加入到队列中,但是它只是将新节点设置为原来tail的next,还未将新节点设置为新的tail
if (tn != null) {
// 因此这里帮助新的节点tn成为新的tail
advanceTail(t, tn);
continue;
}
// 情况2:如果当前cancel的节点不是tail节点
if (s != t) {
// 获取cancel节点的next,此时可以直接将pred的next设置为sn
QNode sn = s.next;
/*
* head-->a-->s-->tail
* s在节点在awitFulfill的时候由于超时或者线程中断而导致等待操作取消,此时s进入到cancel方法中。
* head-->a-->tail
* 这里的pred是a,sn是tail。
*/
if (sn == s || pred.casNext(s, sn))
return;
}
/*
* 情况3:s节点是一个tail节点
*
* head-->s-->tail
*
* tail节点执行cancel
*
* (1).如果cleanme为空,则只是简单地将s标记为cleanme节点
*
* cleanme
* |
* head-->s-->tail
*
*
*/
QNode dp = cleanMe;
if (dp != null) { // Try unlinking previous cancelled node
QNode d = dp.next;
QNode dn;
if (d == null || // d is gone or
d == dp || // d is off list or
!d.isCancelled() || // d not cancelled or
(d != t && // d not tail and
(dn = d.next) != null && // has successor
dn != d && // that is on list
dp.casNext(d, dn))) // d unspliced
casCleanMe(dp, null);
if (dp == pred)
return; // s is already saved node
}
else if (casCleanMe(null, pred)) //将pred节点设置为cleanMe,延迟删除
return;
}
}
下面通过几张图来简单说明一下TransferQueue当发生读写操作时,队列中的变化情况,来帮助我们更好的理解其执行的过程:
-
当队列刚刚创建的时候,此时队列中只有一个节点,该节点即是head,又是tail。
 队列刚刚创建时状态
队列刚刚创建时状态 此时假设Thread 1执行put操作,放入"hello",此时队列发生如下的变化。

- 此时假设Thread 2执行put操作,放入"world",队列变化如下。

- 此时 Thread 3执行take操作,获取队列中的元素。

注意到,这里当执行take操作的时候,其实是让head的节点执行CAS操作,替换调原来的head;然后重新设置节点的item与waiter。通过上面的执行步骤可以看到,TransferQueue的入队列总是从尾部开始,而出队列总是从头部开始,这样就真正实现了先进先出的公平模式。
TransferStack源码分析
通过上面的分析,我们已经知道SynchronousQueue在公平模式下,TransferQueue的实现,下面我们来分析一下基于TransferStack的非公平模式实现。TransferStack是一个基于链表所实现的栈,在栈中的每一个元素被称为SNode(stack node),并且在TransferStack中只定义了一个head属性,表示栈顶元素。

下面我们来了解一下SNode的结构:

SNode是通过一个int类型的mode属性来标识这是一个读节点还是写节点,其具体的值定义在了
TransferStack中。
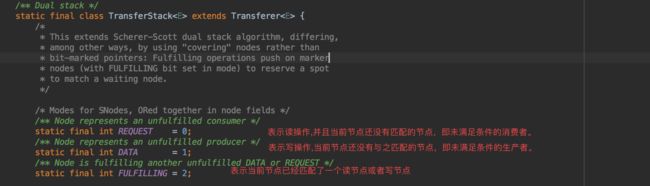
上面的FULFLLING比较特殊,实际上该值不是用于表示节点的模式,而是用于计算出节点的模式。当新节点与栈中原来的节点模式匹配时,假设新节点的状态为0(REQUEST),原来栈中的节点模式为1(DATA),那么在新节点入栈之前,会先将其标识成状态为已匹配到一个节点。因此TransferStack会将新节点的mode值与FULFLLING进行或运算,得到2(表示当前的写节点已经匹配到一个读节点);如果为3,在表示当前的读节点已经匹配到一个写节点。Doug Lea大神在这里的这样设计应该是为了节省空间,通过三个变量就可以表示4种状态,而无需定义4个变量。
transfer
前面我们在分析TransferQueue的时候已经知道,transfer方法是其操作的核心方法,对于TransferStack也同样如此,它也是将put和take操作都统一收敛到一个方法来进行处理。
从源代码的注释中我们可以看到,对于TransferStack的transfer方法而言,其基本的算法与TransQueue略有不同,通过循环地尝试执行如下的3个操作:
如果栈为空或者栈中已经包含了相同模式的节点,那么就会尝试将当前节点推入到栈中,然后一直等待,直到与之匹配的节点出现,最后返回。如果S节点入栈的操作在执行过程中被取消,那么则返回null。
如果栈已经包含了一个与当前模式相互补的节点,则尝试将当前线程作为满足匹配条件的新节点入栈,与栈中的等待节点进行匹配。在匹配完成之后,则将这一对所相匹配的节点从栈中弹出,然后返回匹配节点的内容。
如果当前栈顶元素找到和它匹配的节点,那么当前线程会去帮助它们进行继续匹配,在匹配完成后将它们弹出栈,紧接着再拿自己维护的节点去与继续匹配。
E transfer(E e, boolean timed, long nanos) {
SNode s = null;
// 判断是读操作还是写操作
int mode = (e == null) ? REQUEST : DATA;
for (; ; ) {
SNode h = head;
// 情况1:栈为空或者栈中包含模式相同的节点
if (h == null || h.mode == mode) {
if (timed && nanos <= 0) { // can't wait
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) { //创建新节点s,通过CAS让s成为head
// 当节点入栈之后,线程进入等待,直到有一个与之匹配操作发生或者操作取消才会返回
SNode m = awaitFulfill(s, timed, nanos);
// 在返回后,如果发现返回的结果等于自身,则说明在等待过程中已经取消操作,则将节点从栈中清除
if (m == s) {
clean(s);
return null;
}
// 判断s节点的next是否是head,如果是,则让s的next成为新的head节点
if ((h = head) != null && h.next == s)
casHead(h, s.next);
// 如果是读操作,则返回匹配节点的item,如果是写操作,则直接返回s的item
return (E) ((mode == REQUEST) ? m.item : s.item);
}
}
/*
* 情况2:当前操作与栈顶元素的操作是互补的,此时判断栈顶元素是否是一个匹配的节点
* 因为在多线程并发处理的情况下,会导致多个线程进行同时匹配头结点的情况
*/
else if (!isFulfilling(h.mode)) {
// 如果在匹配的过程中发现head已经取消操作,则直接移除head结点,让head的next成为新的结点
// 然后重新判断当前操作与新的Head是否可以匹配
if (h.isCancelled())
casHead(h, h.next);
// 创建匹配节点,注意:匹配节点的mode当前线程的mode重新计算得出,让匹配节点入栈
else if (casHead(h, s = snode(s, e, h, FULFILLING | mode))) {
for (; ; ) {
// 获取s的next,即原来的head,该节点正是与s互相匹配的节点
SNode m = s.next;
/*
* m节点等于null的情况比较特殊,我们假设现在栈中只有一个节点在等待。
* 当A、B两个线程同时进行匹配,即判断isFulfilling(h.mode),它们同时发现h节点未找到匹配节点,然后分别执行
* A线程执行的快些,当它在准备生成s节点的时候,
* B线程发现h节点cancel,然后将h.next设置为新的Head,由于栈中只有一个节点,因此h.next为null,导致新的head为null
* 此时A线程再去生成s节点的时候,就会造成s的next为null的情况发生。
*/
if (m == null) {
// 将head重新设置为null,通过一下轮重新生成s节点,进入栈中等待
casHead(s, null);
s = null;
break;
}
SNode mn = m.next;
// 因为m是当前待匹配的节点,所以让其与s进行匹配,在匹配成功后,通过将m的next设置为新的Head
// 该操作即完成s与m同时出栈的操作
if (m.tryMatch(s)) {
casHead(s, mn);
return (E) ((mode == REQUEST) ? m.item : s.item);
} else
// 如果匹配失败,则可能是在s与m匹配的过程中,m节点发生了cancel,从而导致匹配失败
// 那么就将m节点从栈中移除,让s指向m的next,即mn节点
s.casNext(m, mn);
}
}
}
// 情况3:即在多个线程与head节点进行匹配的时候,当前线程竞争失败,没有匹配成功,那么它会试图帮助已经找到匹配节点的两个节点进行快速匹配操作
else {
SNode m = h.next;
if (m == null)
casHead(h, null);
else {
// 此时会试图帮助其他正在匹配的节点进行处理,该逻辑与上面分析的一样
SNode mn = m.next;
if (m.tryMatch(h))
casHead(h, mn);
else
h.casNext(m, mn);
}
}
}
}
awaitFulfill
TransferStack的awaitFulfill与TransferQueue的思路基本是一样,即首先判断当前节点是否是下一个最先出队列或者出栈的节点,如果是,则进行一定次数的自旋操作,因此在自旋的过程中,可能有新的线程进来就可以完成与当前线程的匹配,从而减少当前线程的一次挂起;如果不是,则让其进行等待。下面我们简单看下其具体实现:
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
// 判断当前操作是否存在超时,如果存在,则计算出截止时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 获取到当前的执行线程
Thread w = Thread.currentThread();
// 判断其是否需要自旋,这里的判断逻辑与TransferQueue不一样
// 对于队列而言,只有当前节点是head节点、栈为空或者当前栈顶的节点正在进行与其他节点匹配时,则需要自旋
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel();
SNode m = s.match;
// 如果节点的match发生了改变,则说明操作已经取消,直接返回
if (m != null)
return m;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
if (spins > 0)
//每一次自旋操作之后,都将标记值减1
spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null)
// 设置需要等待的线程
s.waiter = w;
else if (!timed)
//让线程等待
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
// 如果在自旋了maxTimedSpins次之后,依旧没有超时,则先让线程等待给定的时间
LockSupport.parkNanos(this, nanos);
}
}
clean
当节点在等待过程中由于超时或者线程中断,就会导致其操作取消,此时需要将节点进行出栈。
下面我们分析一下节点出栈的过程:
void clean(SNode s) {
// 由于节点需要从栈中移除,首先先清除节点的数据以及绑定的线程
s.item = null;
s.waiter = null;
SNode past = s.next;
/*
* 这里在清除s节点时候,如果发现s节点的next也cancel了,也会随之将其从栈中移除。
* 但是这样在多个线程并发清除节点的时候,会存在节点找不到的情况。
*
* 假设A、B线程同时清除节点,A清除a节点,B清除b节点,b是a的next。
* 此时A先清除,让a节点出栈,然后A发现a的next也cancel了,那么也将其出栈。
* 此时B线程再去尝试清除b节点的时候,会发现b节点已经找不到了。
*
* 因此,这里首先获取到s的next为past,如果在遍历栈的过程中查找到past,则说明s肯定已经清除
*
* 如下是可能发生的两种情况:
*
* 图1: 图2:
* x <-head x <-head
* | |
* s (cancel状态) s (cancel状态)
* | |
* a (cancel状态) a <-past
* | |
* b <-past b
* | |
* c c
*
*
*/
if (past != null && past.isCancelled())
past = past.next;
SNode p;
/*
* 从栈顶开始,依次查找其后面的节点是否已经取消操作,直到找到s后面的节点,即我们前面所定义到的past节点,因为找到了past,所以一定说明已经找到s
* 1.如果上图1中的x节点也cancel,在执行完成后,其结果如下:
*
* b <-head
* |
* c
* 此时b节点就等于p
*
* 2.如果图1中的head节点不是cancel状态,则此时不会有节点出栈
*
*/
while ((p = head) != null && p != past && p.isCancelled())
casHead(p, p.next);
//如果上面的head是未cancel的,此时就需要从栈顶依次开始查找s节点将其删除
while (p != null && p != past) {
SNode n = p.next;
if (n != null && n.isCancelled())
p.casNext(n, n.next);
else
p = n;
}
}
在分析完TransferStack的实现之后,我们也通过几幅图来进一步看一看其入栈与出栈的过程


上面当两个线程同时进行写操作时,它们开始进行等待,紧接着线程3开始执行take操作,会发生如下3个步骤:
(1). 匹配节点入栈
(2). 节点互相匹配
(3). 匹配的两个节点出栈
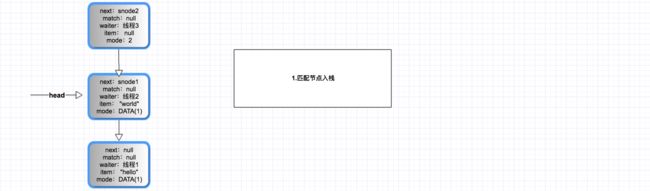


通过上面的图我们可以看到,TransferStack基于栈后进先出的特性,后入栈的线程会先出栈继续执行,这也正是其非公平的体现。
至此,SynchronousQueue的实现基本已经分析完毕。该类的实现比较复杂,尤其是节点出队列或者出栈的过程。分析过程中出现错误的地方,请多多指正!