配置ssh免密登陆
前提:master和slave节点配置相同。
本环境中已默认安装了SSH服务,所以我们只需要对其进行配置即可。
1、生成密钥命令:
ssh-keygen -P ""
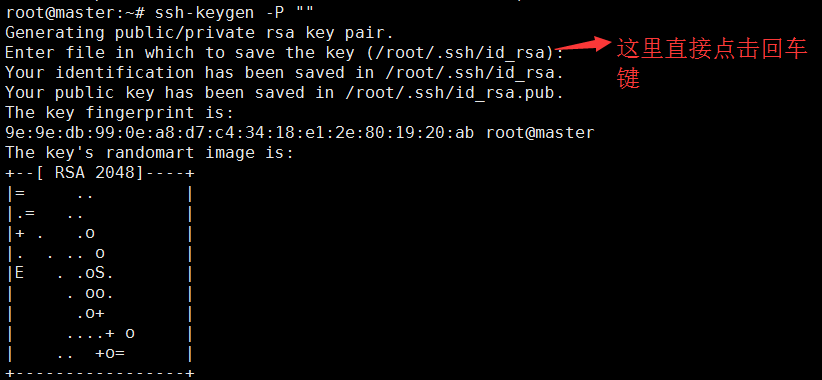
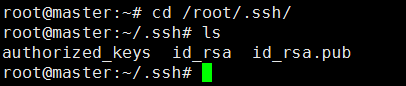
在/root/.ssh目录下可以看到有authorized_keys、id_rsa、id_rsa.pub三个文件
cd /root/.ssh
ls
2、将master的公钥id_rsa.pub复制到master、slave1、slave2的authorized_keys里面,这样就可以让master免密钥登录到master、slave1、slave2。
首先对master自身做免密,如下
ssh-copy-id [email protected]


测试ssh连接到master
ssh master

测试完毕,退出连接使用exit命令。

使用同样的方法让master节点能够免密登录到slave1、和slave2。
ssh-copy-id [email protected]
ssh-copy-id [email protected]
安装hadoop
1、切换到hadoop压缩包所在位置,解压文件
cd /opt
tar -zxvf /opt/hadoop-2.7.3.tar.gz -C /opt
2、配置环境变量
编辑/etc/profile文件,在PATH参数后面追加hadoop路径
vim /etc/profile
编辑如下:
export JAVA_HOME=/opt/jdk1.8.0_111
export PATH=PATH:/opt/hadoop-2.7.3/bin:/opt/hadoop-2.7.3/sbin
export CLASSPATH=.:JAVA_HOME/lib/tools.jar

使配置文件生效
source /etc/profile

切换到/opt/hadoop-2.7.3/etc/hadoop目录下
cd /opt/hadoop-2.7.3/etc/hadoop
ls

重命名mapred-site.xml.template为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
ls

3.1、文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为
localhost,分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为
NameNode 使用。 这里让 master 节点仅作为 NameNode 使用,因此将文件中原来的
localhost 删除,添加两行内容:Slave1和Slave2。
编辑slaves文件
vim slaves
编辑如下:
slave1
slave2

3.2、编辑文件 core-site.xml,改为下面的配置
vim core-site.xml
配置文件编辑如下:
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/opt/tmp

3.3、编辑文件 hdfs-site.xml,其中dfs.replication 一般设为 3吧 ,但我们有两个
Slave 节点,所以 dfs.replication 的值还是设为 2。
vim hdfs-site.xml
配置文件编辑如下
dfs.namenode.secondary.http-address
master:9001
dfs.replication
2
dfs.namenode.name.dir
/opt/dfs/name
dfs.datanode.data.dir
/opt/dfs/data

3.4、编辑文件 yarn-site.xml
vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
master

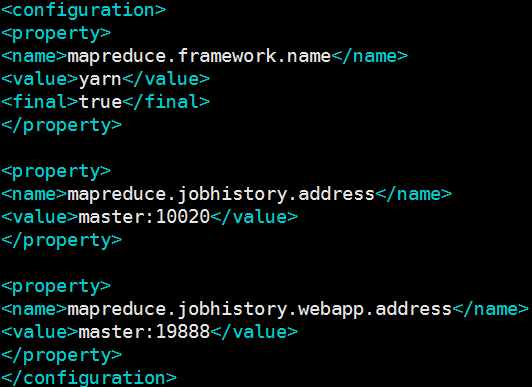
3.5、编辑文件 mapred-site.xml
vim mapred-site.xml
mapreduce.framework.name
yarn
true
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
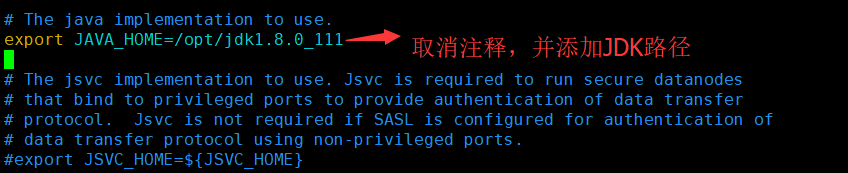
3.6、修改hadoop-env.sh文件下面java的路径
vim hadoop-env.sh
配置文件编辑如下:
export JAVA_HOME=/opt/jdk1.8.0_111
3.7、修改yarn-env.sh文件,修改JAVA_HOME值
vim yarn-env.sh
配置文件编辑如下:
export JAVA_HOME=/opt/jdk1.8.0_111
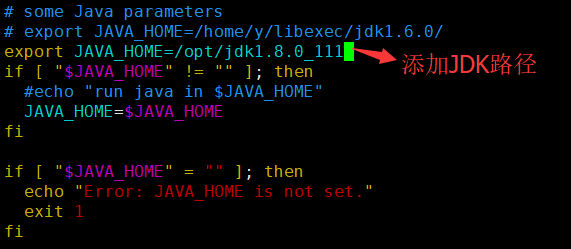
前提:安装hadoop时,master和slave节点配置文件完全相同,这里介绍了master的安装及配置。Slave可以通过手动配置,配置时请参考master,也可通过scp命令将master配置文件拷贝到slave的相同目录下,如:
scp -r /opt/hadoop-2.7.3 root@slave1:/opt
scp -r /opt/hadoop-2.7.3 root@slave2:/opt
将master节点的配置文件拷贝到slave节点,其中 scp -r 表示拷贝目录。
启动hadoop
前提:启动hadoop时,在master节点上面启动。
1、第一次启动需要在master的hadooop安装目录(/opt/hadoop-2.7.3)下执行format。
cd /opt/hadoop-2.7.3
./bin/hdfs namenode -format
2、启动hadoop命令,在master的hadooop安装目录的sbin(/opt/hadoop-2.7.3/sbin)下执行。
cd /opt/hadoop-2.7.3/sbin/
ls

2.1、启动命令
start-all.sh

jps查看集群进程
在hadoop集群开启的状态下,执行jps命令查看集群相关进程是否已完全启动。
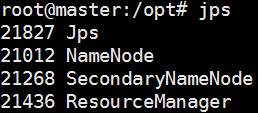
master节点:
启动验证,master节点上应该有4个进程,分别是Jps、NameNode、SecondaryNameNode、ResourceManager,则表示master节点上面启动hadoop成功。
jps
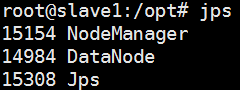
Slave1节点:
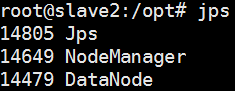
启动验证,slave1节点上应该有3个进程,分别是Jps、DataNode、NodeManager。
jps
Slave2节点:
启动验证,slave1节点上应该有3个进程,分别是Jps、DataNode、NodeManager。
jps
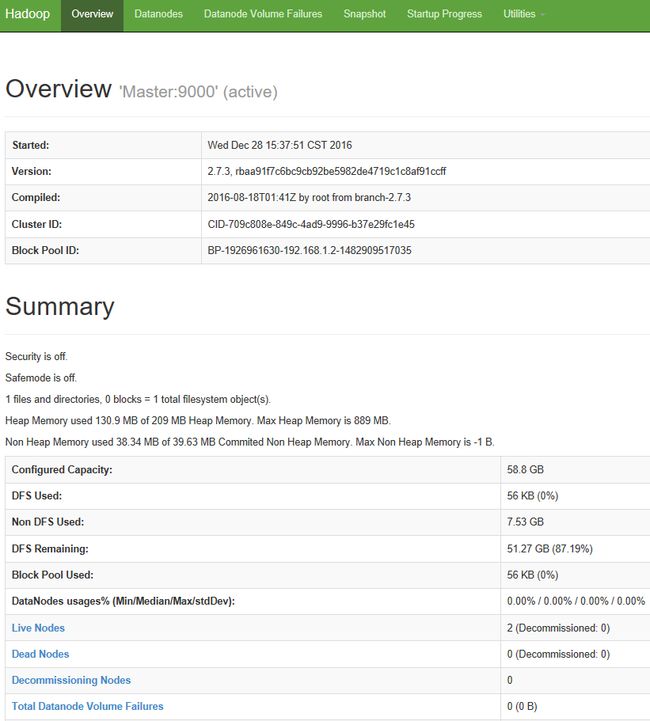
浏览器访问hadoop
1、打开desktop节点
,登录之后(密码为123456),在浏览器上面输入
http://images.handge.cn:50070
,可以查看hadoop集群的概况。注:这里的images.handge.cn是主节点的IP,50070是NameNode默认的端口号。
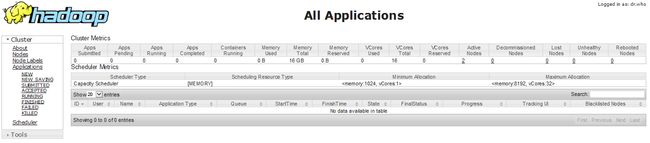
2、打开desktop节点
,登录之后在浏览器上面输入
http://images.handge.cn:8088
,查看hadoop集群中节点的情况。注:这里的images.handge.cn是主节点的IP,8088是默认的ResourceManager的端口号。
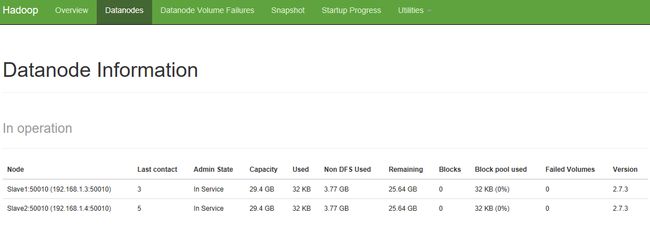
3、在hadoop集群的概况页面中,点击上方菜单栏里面的Datanodes,可以查看Datanode的详细信息。
eclipse配置
说明:Eclipse的配置需要在Desktop节点上,登录默认的密码是123456。
安装插件
-
eclipse想要运行在hadoop集群上,需要安装hadoop-eclipse-plugin插件。首先需要将/opt目录下的hadoop-eclipse-plugin-2.6.0.jar包复制到eclipse的目录的plugins下面。
1、登录之后,在左边菜单栏点击终端图标,如下:
 image
image1.1、在终端切换到root
su image
image1.2、将/opt目录下的hadoop-eclipse-plugin-2.6.0.jar包复制到eclipse的目录的plugins下。
scp /opt/hadoop-eclipse-plugin-2.6.0.jar /opt/eclipse/plugins image
image 环境配置
1、启动eclipse,切换到eclipse所在的目录下,这里的目录为(/opt/eclipse)
cd /opt/eclipse
ls

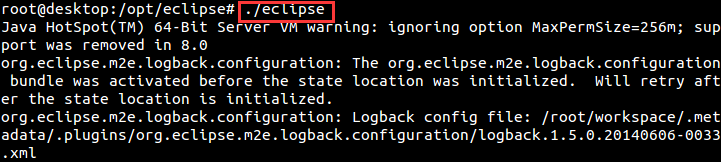
1.2、启动eclipse
./eclipse
2、点击上方菜单栏里面的“window->Preferences”, 点击Preferences。
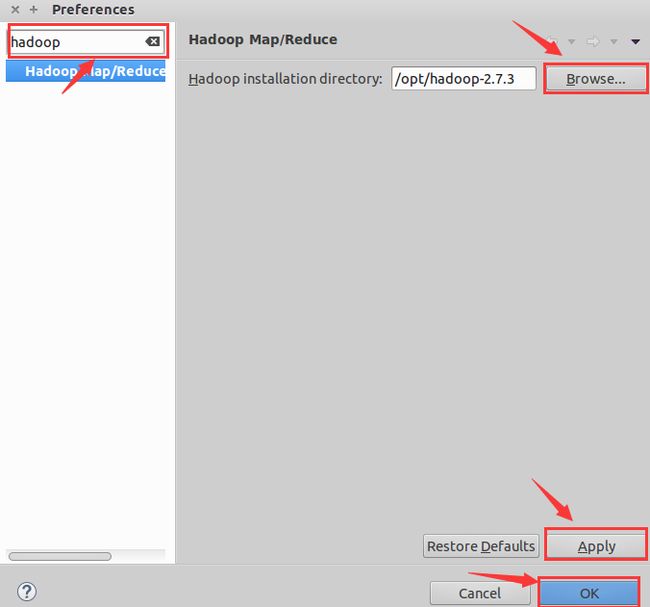
2.1、在搜索框中输入hadoop,选择“Hadoop Map/Reduce”。
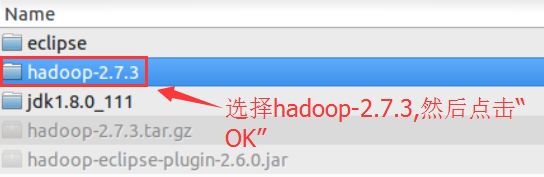
2.2、点击“浏览”添加hadoop的安装目录(这里的安装目录为:/opt/hadoop-2.7.3)。
2.3、点击“Apply”应用。 2.4、点击“OK”。
3、在界面左边的“Project Explorer”显示出“DFS
Location”,在上方菜单栏点击“window->Open
Perspective->Other”,在弹出框选择“MapReduce栏”,最后点击“OK”。在界面下方会显示如下界面:

4、新建一个Location:鼠标右键点击空白区域。如下图:
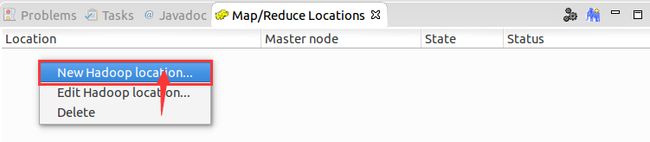
5、编辑新建的Location。如下图:
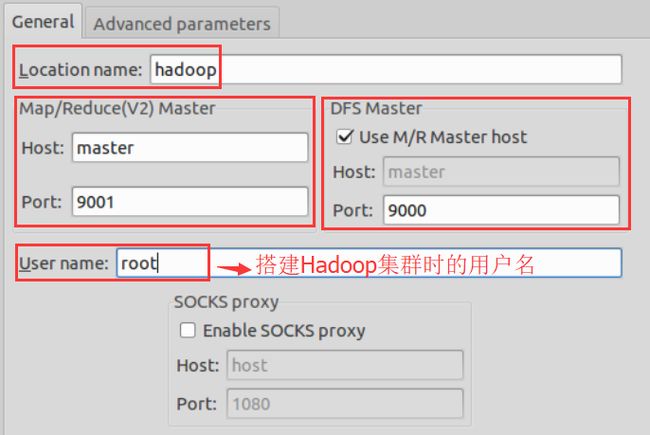
编辑新建的Location,需要注意一下几点:
(a)、Location name 是你为所创建的Location的命名,可以任意填写。
(b)、Map/Reduce(V2)
Master区域,有两个参数需要配置,Host和Port,其中,Host为主节点的hostname或者IP,Port是jobtracker的端口号,这里使用9001。
(c)、DFS
Master区域,同样有两个参数要配置,Host和Port,其中,Host默认和Map/Reduce(V2)
Master区域的Host相同,不需要做更改,Port处需要填写与core-site.xml文件里面的端口,这里填写9000。
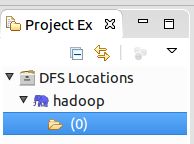
6、配置完毕之后,点击“Finish”。在界面下方会出现新建的Location。如下图:

在界面左侧的Project
Explorer中,则会出现相应的文件夹。(由于最开始没有建文件夹,因此这里显示为0)。如下图:
到这里,eclipse在hadoop-2.7.3上面的搭建已经完成。用户就可以使用Eclipse环境在hadoop集群上进行开发。
停止hadoop
执行停止命令,即:
stop-all.sh