一、模型有什么用?
在这里讲讲我对模型的个人理解,模型有很多种选择,random forest、logistics regression、Xgboost、还有第三篇专门讲到的神经网络(Neural Network)等等,都可以想象成一个内部不同构造的盒子,而现实世界也有一个我们搞不清楚的“上帝盒子”,数据经过“上帝盒子”之后会产生一个结果,而我们只是尽全力去模仿这个盒子,如果放进去数据后,出来的结果不一样,就用“螺丝刀”拧一下盒子的某个零件,再试试,迭代多次,试图仿造一个高仿真的“上帝盒子”。
经过重启篇的第一篇机器学习预判客户流失--预处理(Preprocessing)后,我们手上已经有预处理后的数据,随时准备着放进模型进行训练。而强大的sklearn都把模型封装好了,直接用就是(但是封装太好后,反而觉得TensorFlow的一步步来更深刻理解机器学习)。
二、有什么模型(model)
现在的思路是各种ensemble模型轮流来一次看看效果,选几个还不错的继续调参优化。
三、默认参数跑
以random forest为例说明一次默认参数训练的程序:
# 1、读取数据,选择特征提取前的数据先试试
data = pd.read_csv("haoma11yue_after_onehot_and_RobustScaler.csv", index_col=0, parse_dates=True)
print(data.shape)
# 2、拆分train set和test set
X = data.loc[:, data.columns != 'yonghuzhuangtai']
y = data.loc[:, data.columns == 'yonghuzhuangtai']
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.22, random_state = 0)
# 3、默认参数训练
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier() #默认参数
random_forest.fit(X_train,y_train.values.ravel())
y_pred = random_forest.predict(X_test.values) # 在test set中使用train后的模型
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(y_test,y_pred,title='Confusion matrix') # 画混淆矩阵
各种模型的默认参数跑一遍后的f1对比如下:
# threshold LogisticRegression RandomForest AdaBoostClassifie \
# 0.1 0.405979 0.495127 0.053547
# 0.2 0.513290 0.561127 0.053547
# 0.25 0.533361 0.561127 0.053547
# 0.3 0.536322 0.611567 0.053547
# 0.35 0.530696 0.611567 0.053547
# 0.4 0.511683 0.627388 0.053547
# 0.45 0.486014 0.627388 0.069147
# 0.5 0.449934 0.608544 0.510414
# 0.6 0.359860 0.567101 0.000000
# 0.65 0.311111 0.567101 0.000000
# 0.7 0.261382 0.491794 0.000000
# 0.75 0.211934 0.491794 0.000000
# 0.8 0.170394 0.374882 0.000000
# 0.85 0.142235 0.374882 0.000000
# 0.9 0.111769 0.215969 0.000000
# time 506.035444 15.628484 92.934639
# threshold GradientBoostingClassifier ExtraTreesClassifier XGBClassifier \
# 0.1 0.437860 0.488229 0.415315
# 0.2 0.586919 0.551792 0.598231
# 0.25 0.607899 0.551881 0.609399
# 0.3 0.611326 0.582324 0.608264
# 0.35 0.612293 0.582324 0.601542
# 0.4 0.605018 0.591883 0.597690
# 0.45 0.593697 0.591883 0.589189
# 0.5 0.587211 0.564064 0.583230
# 0.6 0.569728 0.512568 0.555934
# 0.65 0.550586 0.512568 0.529348
# 0.7 0.519846 0.439964 0.501970
# 0.75 0.481748 0.439964 0.462256
# 0.8 0.411944 0.323587 0.397783
# 0.85 0.325399 0.323587 0.275908
# 0.9 0.203042 0.178635 0.127031
# time 254.957400 8.558467 147.439363
# threshold MLPClassifier
# 0.1 0.426606
# 0.2 0.551230
# 0.25 0.582513
# 0.3 0.596386
# 0.35 0.600496
# 0.4 0.602100
# 0.45 0.593110
# 0.5 0.586122
# 0.6 0.564208
# 0.65 0.546416
# 0.7 0.523497
# 0.75 0.489865
# 0.8 0.448980
# 0.85 0.396341
# 0.9 0.321163
# time 228.245112
默认参数下,不同thresholdvalue下,各个model的最佳f1:
| Model | f1 | threshold_value |
|---|---|---|
| LogisticRegression | 0.536322 | 0.3 |
| RandomForest | 0.627388 | 0.4,0.45 |
| AdaBoostClassifie | 0.510414 | 0.5 |
| GradientBoostingClassifier | 0.611326 | 0.3 |
| ExtraTreesClassifier | 0.591883 | 0.4,0.45 |
| XGBClassifier | 0.609399 | 0.25 |
| MLPClassifier | 0.602100 | 0.4 |
默认参数下,效果最好的是最传统的ensemble model:random forest。
四、调参
选择对random forest的参数进行“暴力调参”,试图再提升一点。
有什么可以调节的参数,重点参考此博客:

以调节n_estimators为例
# 罗列n_estimators可能的取值
randomforest_param_grid = {'n_estimators':list((50,70,90,100,120,150))}
# 用不同取值的n_estimators进行训练
grid = GridSearchCV(RandomForestClassifier(min_samples_split=100,min_samples_leaf=20,max_depth=8,\
max_features='sqrt',oob_score=True,random_state=10),\
param_grid=randomforest_param_grid, cv=5 ,scoring = 'f1')#scoring = 'roc_auc' or 'f1'
grid.fit(X_train,y_train.values.ravel())
# 记录最好的n_estimators取值
best_n_estimators = grid.best_estimator_.n_estimators
重复以上的过程,完成对所有参数的尝试,得到对应的最优参数集合:
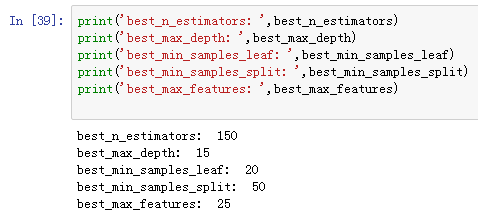
使用最优参数集合再跑一次,得出:
from sklearn.ensemble import RandomForestRegressor,RandomForestClassifier
#用上之前的调参结果
random_forest_2 = RandomForestClassifier(n_estimators=best_n_estimators,\
max_depth= best_max_depth,\
min_samples_leaf=best_min_samples_leaf,\
min_samples_split=best_min_samples_split,\
max_features= best_max_features,\
oob_score=True,random_state=10 )
random_forest_2.fit(X_train,y_train.values.ravel())
y_pred = random_forest_2.predict(X_test.values)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(y_test,y_pred,title='Confusion matrix')
threshold RandomForest RandomForestClassifier_after
0.1 0.496879 0.443841
0.2 0.567852 0.589312
0.25 0.567852 0.620368
0.3 0.611631 0.630484
0.35 0.611631 0.628904
0.4 0.629425 0.624911
0.45 0.629425 0.620005
0.5 0.613506 0.614813
0.6 0.564349 0.590402
0.65 0.564349 0.566819
0.7 0.477984 0.540466
0.75 0.477984 0.501147
0.8 0.357303 0.439289
0.85 0.357303 0.353772
0.9 0.196943 0.231652
time 17.285579 582.548320
| RandomForest | f1 | threshold_value |
|---|---|---|
| 默认参数 | f1-0.629425 | threshold_value:0.4,0.45 |
| 调参后 | f1-0.630484 | threshold_value:0.3 |
性能有0.1%的提升。看来这次提升不大高,可以继续摸索不同的参数。
整个训练使用的时间(2018-06-28 23:24:37至 2018-06-29 10:13:14),接近11个小时,默认参数训练一次用时17.29s,调参后的参数训练用时582.55s。后面试试用特征选取后的数据再训练看看效果和时间的差别。
五、特征选取、数据标准化对模型的影响
探寻一下,预处理中的特征选取、数据标准化等步骤的影响。
5.1、使用特征选取后的数据进行同样参数的训练,得到的结果对比如下:
还是在random forest模型的基础上比较
| 特征选取 | 模型参数 | f1 | threshold_value | 训练时间 |
|---|---|---|---|---|
| 没有特征选取-69个feature | 默认参数 | f1-0.629425 | 0.4,0.45 | 17.29s |
| 选取30个特征 | 默认参数 | f1-0.619808 | 0.4 | 15.80s |
| 没有特征选取-69个feature | 调参后 | f1-0.630484 | 0.3 | 582.55x |
| 选取30个特征 | 调参后 | f1-0.626765 | 0.3 | 668s |
小结:
- 默认参数下,使用30个特征比69个特征,f1下降了1%。
- 调参后的,使用30个特征比69个特征,f1下降了0.37%。
- 使用30个特征,整个暴力调参过程(2018-06-29 13:37:21至2018-06-29 22:47:35),耗时9个小时多一点,比使用69个特征,使用11个小时,节省2个小时。(好像节省得不多!)
5.2、使用数据标准化前的数据进行同样参数的训练,得到的结果对比如下:
| RandomForest默认参数 | f1 | threshold_value |
|---|---|---|
| 数据标准化后 | f1-0.629425 | 0.4,0.45 |
| 数据标准化前 | f1-0.615385 | 0.4,0.45 |
小结:如果使用没有标准化的数据进行训练,f1会下降1.404%。
六、模型是否有预判性
使用历史数据训练出来的模型对当前数据进行预测,具体的预测效果如何呢?
做一个思想实验,T月的流失客户训练出来的模型,f1是60%,然后用到T+1的全量数据中进行预测,f1是57%,低了3%,数据还算是有延续性,可以预测,同时也说明模型需要不停的学习新数据,自我迭代。
备注下什么评估标准:

截图来源:还是 强大的wiki.
评估标准一大堆,独爱f1,混淆矩阵,横坐标是预测,纵坐标是实际发生,性能主要看三个指标:
-
recall 召回率,真实流失客户中,多少被预判为流失。
 image.png
image.png -
precision 准确率,预测为流失的客户中,真的会走的的有多少。
 image.png
image.png
-
f1,综合考虑recall 和 precision的指标。
 image.png
image.png
再解释通俗讲一遍就是,模型预测的1000个客户,有800个确实最后离网了,80%的precision,但是也有另外800个真实离网的没被预测到,50%的recall。预测的都蛮准,但是预测不全。
写在第二篇最后,提醒自己,改改程序代码,更简洁点。现阶段,最好的f1是0.630484,神经网络能突破吗?
也试试SVM
THE END......