
本文是论文Treadmarks: Distributed Shared Memory on Standard Workstations and Operating Systems 的读书笔记,水平有限,若有任何错误的地方,请不吝指出。
本文是mit 6.824 Schedule: Spring 2016的第12课,前面课程内容可以在分布式找到,更多详细资料可以到:distributed-system查看。
介绍
在并发编程中,我们需要处理两个关键问题:
- 线程之间如何通信
- 线程之间如何同步
通信是指线程之间以何种机制来交换信息,在命令式编程中,线程之间的通信机制有两种:
- 共享内存
- 消息传递
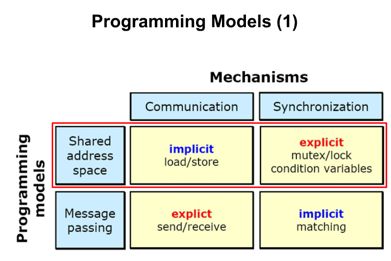
我们从通信和同步两个维度来看共享内存和消息传递。
在共享内存的并发模型里,线程之间共享程序的公共状态,线程之间通过写-读内存中的公共状态来隐式进行通信。在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过明确的发送消息来显式进行通信。
同步是指程序用于控制不同线程之间操作发生相对顺序的机制。在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
通过上面的介绍我们知道了共享内存是一种隐式的通信手段,需要显示的方法来实现同步。
而在分布式系统中,我们希望能够的是能尽可能的利用普通的机器,来达到并行计算的目标,而distributed shared memory (DSM) 在分布式系统中实现了共享内存,让所有process都共享一个全局地址空间,通过提供简单的api,方便process的访问。
先让我们看下api

其中barrier,acquire和realease用于同步操作,一旦调用barrier等待所有process都到达这个点后才继续执行,acquire和realease则用于锁的获取和释放。
设计
在实现DSM时,主要考虑的两个问题是:
- 一致性
- False Sharing
首先在分布式系统中,为了提高性能,往往会对同一份数据做本地缓存,加快访问,但是数据虽然有多份,但是需要保证数据的一致性,同一份数据可能有多个副本,一旦数据做出了改变,需要通知所有持有副本的process,数据已经改变了。
我们先来看下如果要实现这种严格的数据改变,就必须可见,系统需要怎么做?
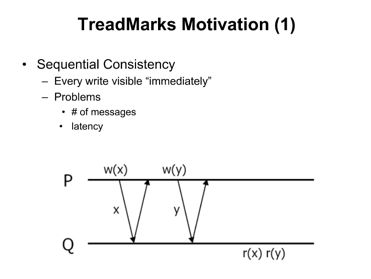
如上图所示,每个写操作一旦完成,必须要通知所有其他的进程该行为,带来的问题是:
- 消息数的增加
- 延迟
这种严格的一致性被称为是:sequence consistency,一般系统为了其他一些因素,都会做出一些trade-off,TreadMarks则是采取了release consistency,只有在同步点上才要求数据同步,看图:

使用release consistency的目标是:
- 减少消息数
- 减少延迟
那此处具体的同步点是什么时候呢?
前面提到过TreadMarks提供了acquire和release两个同步操作,当发生同步操作的时候,进行数据的同步。

此时在release的时候,将在acquire和release之间的数据改变广播给所有的持有数据副本的process,但是由于需要等待所有副本答复说已经收到通知,release操作会比较耗时。

TreadMarks在实现release consistency采用了Lazy Release Consistency,
- 只有当下次acquire锁的时候才会去获取改变
- 获取再取有效的减少了消息数
Eager和Lazy在实际运行中减少的消息数,可以通过下图直观的看到:

下一个需要解决的问题是:False Sharing,那什么是False Sharing?
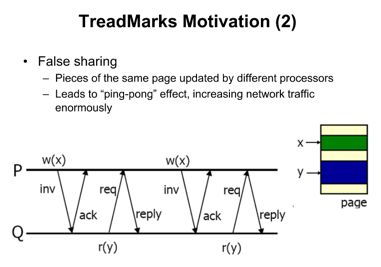
我们看到P和Q都是操作同一个page,但是P是写x,而Q是读y,但是由于P写完x后通知了Q改页已经数据更改了,失效了保存在Q中的副本,因此Q再去访问y的时候,必须要去P处获取该页的数据,加重了数据的传输成本。那解决办法有什么呢?采用 multiply writer protocol,具体来讲就是
- 采用copy-on-write机制
- 一旦某个进程被授权访问write-shared的数据,将包含数据的页标志为copy-on-write
- 第一次更改页数据的时候,会创建一个备份:twin

当release操作的时候,TreadMarks会:
- 比较twin和修改过后的数据
- 将不同保存为diff
- 通知所有的副本(write notice)
- 当其他process访问改页的时候,会去请求diffs

TreadMarks在diffs的创建上,采取了Lazy的策略,只有当其他processor请求页改变的时候,才会去创建diffs。
数据结构
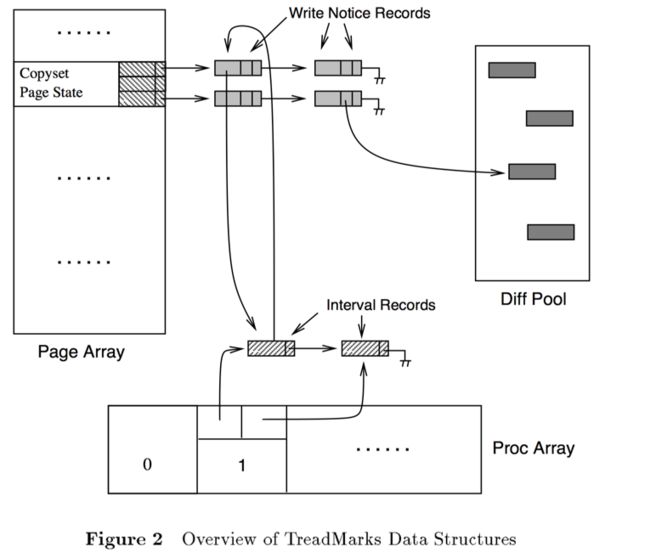
主要数据结构如上图所示,包括了
- Page Array
- Proc Array
- write notice records
- diff pool
此处PageArray中每个entry都是一个page,包含的数据有
- 页的当前状态:no access, read-only access, read-write access
- 当前持有当前页的processor
- 一个以processor_id为index的array,每个array index都是来自processor的write notice,并且以interval排序,如果write notice对应的diffs已经创建,则会有一个指针指向
每个ProcArray则是记录了processor知道的intervals records,每个interval records指向了当前intervals知道的write notices。
下面举个例子:
M0: a1 x=1 r1 a2 y=9 r2
M1: a1 x=2 r1
M2: a1 a2 z = x + y r2 r1
有M0,M1,M2,3个进程,其中a和r代表acquire和release,那此时M2中获取到x的值是M0设置的x=1还是M1设置的x=2呢?
这就要引入一个叫vector clock的东西,通过一组图来看下是怎么回事。

起初P1,P2,P3开始counters都是0,

当有本地事件发生的时候,P1对应的counter加1

P3也发生了本地事件,counter加1

当P1收到P3发送来的消息的时候,本地counter加1,其余counter进行更新

P1发送事件自己的counter加1,P2接收事件,自己的counter加1,其余counter进行更新;
上面的图基本上就说明了vector clock是怎么回事,维护了分布式系统中的一个因果关系。
现在我们再回到之前的例子:
M0: a1 x=1 r1 a2 y=9 r2
M1: a1 x=2 r1
M2: a1 a2 z = x + y r2 r1
此时M2怎么知道x等于几?当M2在获取锁1的时候,会去请求前一个释放锁的进程,可能是M1也可能是M0,并将自己的vector clock传递过去,然后锁的前一个releaser同自己的vector clock比较,将改变传递过来,具体通过一个图来说明:
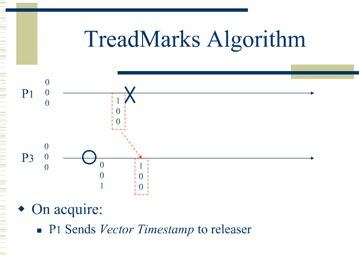
P1发送Vector timestamp给releaser P3

P3对于已经更新的counters附上invalidations

P3将其发送给P1

P1收到invalidation后,请求diffs,并将diffs应用到page。
性能
略
参考
Treadmarks: Distributed Shared Memory on Standard Workstations and Operating Systems - PowerPoint PPT
TreadMarks - PowerPoint PPT Presentation
这是6.824: Distributed Systems的第12课,你的鼓励是我继续写下去的动力,期待我们共同进步。