什么是Zookeeper?
总结一句话,就是:
ZooKeeper是一种分布式协调服务,可以实现分布式应用配置管理、统一命名服务、状态同步服务、集群管理、分布式锁和分布式队列等功能。
从这句话我们可以知道 Zookeeper 的基本定位是作为一个分布式服务协调框架,能够提供配置管理、统一命名服务、转态同步服务、管理集群、分布式锁和分布式队列等功能。
为什么选择Zookeeper?
在讲《分布式专题(2)- 分布式 Java通信》时我们说过,所谓分布式,无非就是“将一个系统拆分成多个子系统并散布到不同设备”的过程而已。在微服务的大潮之中, 我们把系统拆分成了多个服务,根据需要部署在多个机器上,这些服务非常灵活,单个或几个系统的故障不会使整个系统出现故障。并且可以随着访问量弹性扩展,能够持续不间断地提供服务。
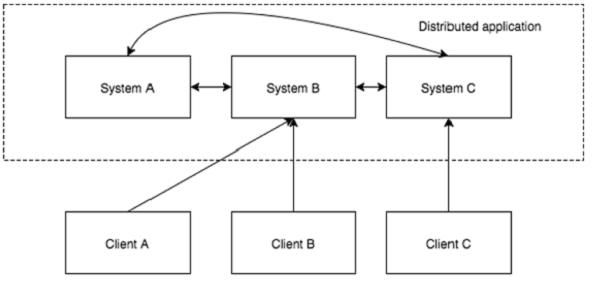
虽然分布式应用给我们带来了诸多好处,但拆分系统的同时也带来了巨大的复杂性,我们要写一个分布式应用还是非常困难的,如需要处理分布式session、分布式跨域、分布式任务调度、分布式事务、分布式锁、分布式局部故障等问题。如局部故障问题,一个消息通过网络在两个节点之间传递时,网络如果发生故障,发送方并不知道接收方是否接收到了这个消息。他可能在网络故障前就收到了此消息,也可能没有收到,又或者可能接收方的进程死了。发送方了解情况的唯一方法就是再次连接接收方,并向他进行询问。这就是局部故障:根本不知道操作是否失败。因此,大部分分布式应用需要一个主控、协调控制器来管理物理分布的子进程。目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制。协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器。协调服务非常容易出错,并很难从故障中恢复。例如:协调服务很容易处于竞态甚至死锁。Zookeeper的设计目的,是为了减轻分布式应用程序所承担的协调任务。
Zookeeper并不能阻止局部故障的发生,因为它们的本质是分布式系统。他当然也不会隐藏局部故障。ZooKeeper的目的就是提供一些工具集,用来建立安全处理局部故障的分布式应用。
ZooKeeper是一个分布式小文件系统,并且被设计为高可用性(数据保持在内存中)。通过选举算法和集群复制可以避免单点故障,由于是文件系统,所以即使所有的ZooKeeper节点全部挂掉,数据也不会丢失,重启服务器之后,数据即可恢复。另外ZooKeeper的节点更新是原子的,也就是说更新不是成功就是失败。通过版本号,ZooKeeper实现了更新的乐观锁,当版本号不相符时,则表示待更新的节点已经被其他客户端提前更新了,而当前的整个更新操作将全部失败。当然所有的一切ZooKeeper已经为开发者提供了保障,我们需要做的只是调用API。与此同时,随着分布式应用的的不断深入,需要对集群管理逐步透明化监控集群和作业状态,可以充分利ZK的独有特性。
总结上面的几段话,得出选择使用Zookeeper的原因就是:
大部分分布式应用需要一个主控、协调控制器来管理物理分布的子进程;
大部分分布式应用需要开发私有的协调程序,缺乏一个通用的机制;
协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器;
ZooKeeper提供了通用且高可用的分布式服务,用以协调分布式应用
下面,我们先把Zookeeper下载回来安装,结合实例,一起来认识和理解“ZooKeeper是一种分布式协调服务,可以实现分布式应用配置管理、统一命名服务、状态同步服务、集群管理、分布式锁和分布式队列等功能”的含义。
Zookeeper数据模型
ZooKeeper是一种分布式协调服务,可以实现分布式应用配置管理、统一命名服务、状态同步服务、集群管理、分布式锁和分布式队列等功能。具体是通过它独特的数据结构来实现的,我们可以认为 Zookeeper = 文件系统+监听通知机制。下面我们看一下它的数据结构:
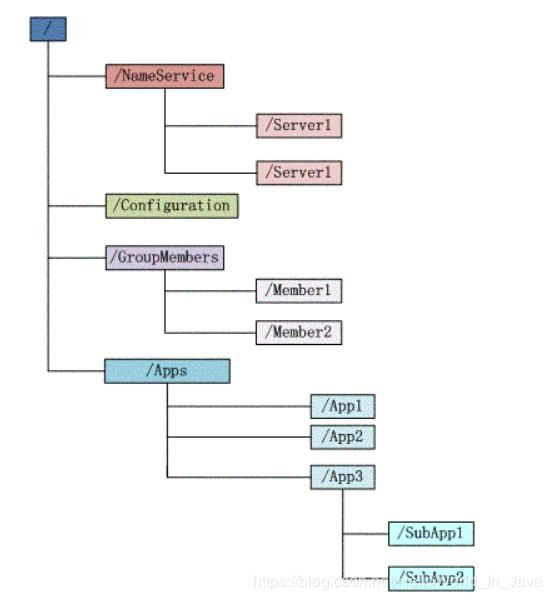
文件系统
在Zookeeper的数据结构中,每个子目录项如 NameService 都被称作为 znode(目录节点),和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有持久、持久有序、临时、临时有序四种类型的znode:
PERSISTENT(持久节点):客户端与zookeeper断开连接后,该节点依旧存在
PERSISTENT_SEQUENTIAL(持久有序节点):客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
EPHEMERAL(临时节点):客户端与zookeeper断开连接后,该节点被删除
EPHEMERAL_SEQUENTIAL(临时有序节点):客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
通知机制
zookeeper客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
我们说 Zookeeper = 文件系统+监听通知机制,好像看起来挺简单的啊(E=mc²看起来也挺简单的),它怎么就能通过这么简单两点东西,实现分布式应用配置管理、统一命名服务、状态同步服务、集群管理等功能呢?我们看一个它实现配置管理功能的例子,就大概知道它是怎么实现其它功能了。
配置管理
假设我们的程序是分布式部署在多台机器上,如果我们要改变程序的配置文件,需要逐台机器去修改,非常麻烦,现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 zookeeper 的通知,然后从 zookeeper 获取新的配置信息应用到系统中。
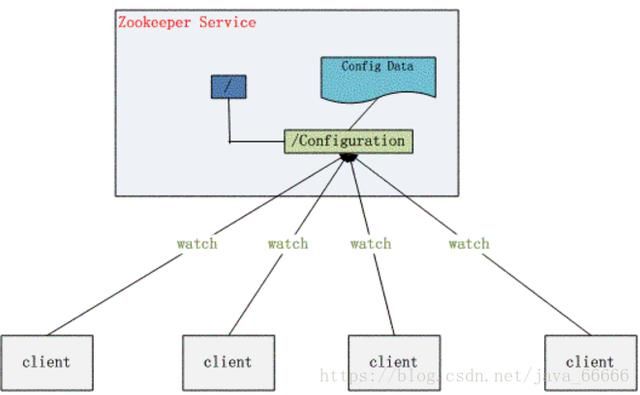
是不是通过配置管理这个例子,对Zookeeper的了解就更清晰了?还有另外一个经典用法,如下
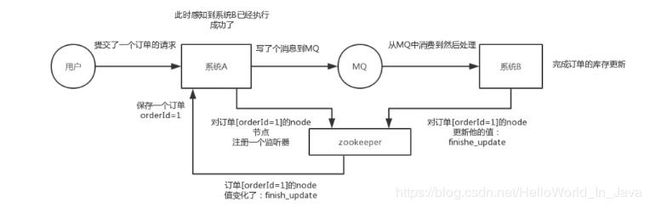
如上图所示,系统A发送一个请求到MQ,然后系统B消费消息之后处理了。那系统A如何知道系统B的处理结果?
用ZK就可实现分布式系统之间的协调工作!
系统A发送请求之后可以在ZK上对某个节点的值注册监听器,一旦系统B处理完了就修改ZK那个节点的值,A立马就可以收到通知。
通过上面这两个例子,我们对 “Zookeeper = 文件系统+监听通知机制,ZooKeeper是一种分布式协调服务,可以实现分布式应用配置管理、统一命名服务、状态同步服务、集群管理、分布式锁和分布式队列等功能”可以有更形象地理解。
下面我们就看看Zookeeper一些基本命令,如节点的增删改查等,然后通过Zookeeper提供的API,一起用Java代码实现配置管理、统一命名服务、状态同步服务、集群管理、分布式锁和分布式队列等功能。
Zookeeper基本命令
Zookeeper是用来解决分布式应用中经常遇到的数据管理问题,对于数据,那基础的无非都是增删改查。下面我们启动zookeeper服务端,然后启动zookeeper客户端,一起敲一下它增删改查的命令。
zookeeper基本的五个命令为 ls 、 create 、 delete 、 set 、get 。输入-h可以查看所有命令,相关命令示例可参考这里。
下面开始使用
1、使用 ls 命令来查看当前 ZooKeeper 中所包含的内容(默认只有zookeeper一个节点)

2、创建一个新的 znode ,使用 create /zkPro myData
3、再次使用 ls 命令来查看现在 zookeeper 中所包含的内容:

4、下面我们运行 get 命令来确认第二步中所创建的 znode 是否包含我们所创建的字符串:

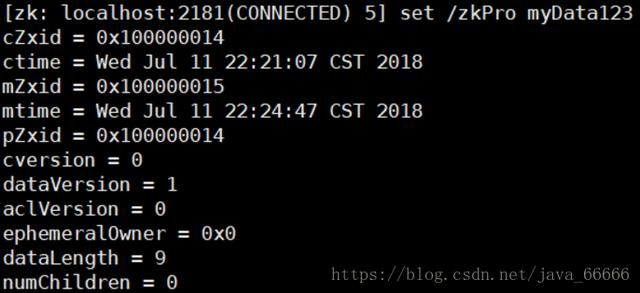
5、下面我们通过 set 命令来对 zk 所关联的字符串进行设置:
6、下面我们将刚才创建的 znode 删除

可以看到,客户端中对节点进行增删改查的命令还是非常简单的。
Zookeeper集群
以上的讲解中都是基于单机模式,这种模式下,如果当前主机宕机,那么所有依赖于当前zookeeper服务工作的其他服务器都不能在进行正常工作,这种事件称为单节点故障。所以这种模式一般用在测试环境。为了防止这种情况出现,生产环境一般都是会在多台机器上配置zookeeper来组成集群,以实现容错和高可用。集群就涉及到数据一致性的问题,即集群中的的数据都应该要保持同步。为此,zookeeper集群引入了Leader、Follower的概念。即对来自于Client的写服务(Write Requst),都会被转发到Leader节点来处理,Leader节点会对这次的更新发起投票,并且发送提议消息给集群中的其他节点,当半数以上的Follower节点将本次修改持久化成功之后,Leader 节点会认为这次写请求处理成功了,提交本次的事务。而来自于Client的读服务(Read Requst),是直接由对应Server的本地副本来进行服务的。具体可以参考Zookeeper一致性原理(ZAB协议),另外此处补充几个著名的分布式理论。
zookeeper搭建集群也很简单,只需要简单的几步即可完成。
(在一台机器上搭建多个zookeeper就是俗称的伪集群了,资源有限,此处模拟搭建的是伪集群)
1.修改zoo.cfg配置文件
在conf下将zoo_sample.cfg复制为zoo-1.cfg并修改内容如下(其它配置不用动,只修改目录和端口,并添加集群信息):
dataDir=/tmp/zookeeper-1
clientPort=2181
server.1=127.0.0.1:12181:13181
server.2=127.0.0.1:12182:13182
server.3=127.0.0.1:12183:13183
对比单机模式,配置zk集群时配置文件只需要添加一句:server.id=ip:port1:port2 即可,配置3条即指集群中有3个zk。
可以看到zookeeper的配置中有三个端口,其作用如下:
clientPort:表示与服务端与 clinet 端交换信息的端口号;
port1:表示follower节点与leader节点交换信息的端口号;
port2:表示leader节点挂掉了, 来重新选举leader需要的端口号。
2.复制zoo-1.cfg配置文件
再从zoo-1.cfg复制两个配置文件zoo-2.cfg和zoo-3.cfg,只需修改dataDir和clientPort不同即可,其它配置保存不变。
# zoo2.cfg中的目录和clientPort:
dataDir=/tmp/zookeeper-2
clientPort=2182
# zoo3.cfg中的目录和clientPort:
dataDir=/tmp/zookeeper-3
clientPort=218
3.创建dataDir目录和标识server.id
每个人都有自己的身份证,每台电脑都有自己的Mac地址,每个zookeeper也有自己唯一标识,就是 server.id 中的id,这个值需要记录在 dataDir 的 myid 文件中。所以我们要为集群中的zookeeper创建这个myid文件,内容就是我们zoo.cfg中配置的id。
# 创建zoo-1.cfg对应的目录及server.id
mkdir /tmp/zookeeper-1
vim /tmp/zookeeper-1/myid
1
# 创建zoo-2.cfg对应的目录及server.id
mkdir /tmp/zookeeper-2
vim /tmp/zookeeper-2/myid
2
# 创建zoo-3.cfg对应的目录及server.id
mkdir /tmp/zookeeper-3
vim /tmp/zookeeper-3/myid
3
4.启动集群实例
bin/zkServer.sh start conf/zoo-1.cfg
bin/zkServer.sh start conf/zoo-2.cfg
bin/zkServer.sh start conf/zoo-3.cfg
5.检测集群状态
bin/zkServer.sh status conf/zoo-1.cfg
bin/zkServer.sh status conf/zoo-2.cfg
bin/zkServer.sh status conf/zoo-3.cfg
可以看到,有一台leader、两台作为follower,集群启动成功。选举过程可以参看这里。

可以通过多个客户端连接集群中不同的机器,并修改其中一台机器上的数据,观察数据是否会同步更新到其它机器上
可以通过安装zookeeper图形化界面来更方便地观察zk的节点信息和对zk节点进行增删改查
终于把zookeeper的基本使用和集群讲完了。接下来,我们就一起再次理解“ZooKeeper是一种分布式协调服务,可以实现分布式应用配置管理、统一命名服务、状态同步服务、集群管理、分布式锁和分布式队列等功能”这句话。
最新免费java,架构,大数据AI编程资料获取添加
薇信:18410263200
通过验证填写“111”(备注必填)