python量化框架有很多,zipline是一个比较好的选择(在之后的安装中我后悔了),在github上星也是最多的,国内外很多量化都在用,中,英文档齐全,社区完整,发展成熟(好,不吹了)
安装
文档上有很多种安装,这里主要用anaconda在linux上安装(conda自行下载安装
)
zipline目前能良好支持 python2.7 python3.5,建议你不要有其他想法,我最先就是用的其他版本,结果爆了一堆奇奇怪怪的错误还无法解决。
# 创建一个3.5的python环境
$ conda create -n env_zipline python=3.5
# 激活环境
$ source activate env_zipline (winddows 使用 activate env_zipline )
# 安装zipline
$ conda install -c Quantopian zipline
# -- 其他 --
# 停用环境
$ source deactivate
# 查看conda环境的目录
$ conda env list
# pycharm集成
在pycharm中的File->setting->Project:XXXX->Project Interperter添加刚才查看的目录就行了
数据绑定
我没有下载数据,国内速度感人,请自行想办法,我那该死的1核1g的服务器,根本干不了,进程会被killed,加大了swap虚拟内存也不行,不了了之
# 默认数据 需要绑定一次
# 需要 Quandl 的 API key 来获取默认数据 https://docs.quandl.com/docs#section-authentication
# 可以去网站免费注册一个账号(获取API_KEY),并使用如下命令将数据灌入zipline。
$ QUANDL_API_KEY= zipline ingest [-b ]
# 其中 是数据包的名称,默认为 quandl
$ QUANDL_API_KEY=jYsYCRqJTk1C6GojWZ3- zipline ingest -b quandl
# 从.csv文件中加载数据
# 导入 csvdir 和 pandas 包 (可以编辑 ~/.zipline/extension.py,也可以直接写在策略中)
import pandas as pd
from zipline.data.bundles import register
from zipline.data.bundles.csvdir import csvdir_equities
# 指定开始和结束时间:
start_session = pd.Timestamp('2016-1-1', tz='utc')
end_session = pd.Timestamp('2018-1-1', tz='utc')
# 然后我们可以传入 .csv 文件路径,用 register() 注册我们的自己编写的 bundle
register(
'custom-csvdir-bundle',
csvdir_equities(
['daily'],
'/path/to/your/csvs',
),
calendar_name='NYSE', # US equities
start_session=start_session,
end_session=end_session
)
# 运行命令导入自己编写的 bundle
$ zipline ingest -b custom-csvdir-bundle
# 我们可以通过命令行传递我们的csvs的位置
$ CSVDIR=/path/to/your/csvs zipline ingest -b custom-csvdir-bundle
# 默认情况下,数据将被写在 $ZIPLINE_ROOT/data/ (默认情况下 ZIPLINE_ROOT=~/.zipline )
# ingest 会将新数据写入$ZIPLINE_ROOT/data/ 并以当前日期命名,可以按日期查看旧数据,用旧数据进行回测。 使用旧数据进行回测,可以更容易地重现回测结果
# zipline 默认保存所有绑定的数据 数据目录会非常大,可以使用清理命令
# clean everything older than
$ zipline clean [-b ] --before
# clean everything newer than
$ zipline clean [-b ] --after
# keep everything in the range of [before, after] and delete the rest
$ zipline clean [-b ] --before --after
# clean all but the last runs
$ zipline clean [-b ] --keep-last 0 #数字表示保留最近的n次数据
# 查看zipline 数据
$ zipline bundles
编写算法策略
每个算法策略包含两个函数
initialize(context)handle_data(context, data)
在算法执行前,zipline首先会调用 initialize() 传入context,context是算法执行过程中共用的上下文信息,可以用来存储算法执行不同阶段的需要保存的数据。
初始化后,zipline会根据事件调用 handle_data(),每次调用,都会传入context与data,context是执行过程中唯一的一份,但data则与该次调用的事件相关,通常会包含此刻的开盘,最高、最低及收盘价。
来尝试写一个最简单的算法策略(就是官网的例子~)
from zipline.api import order, record, symbol
def initialize(context):
pass
def handle_data(context, data):
order(symbol('AAPL'), 10)
record(AAPL=data.current(symbol('AAPL'), 'price'
可以看到,首先我们引入一些需要的函数。策略中所有常用的函数可以在 zipline.api 中找到。 这里的 order() 函数接受两个参数:一个股票代码,一个数量(为负则为卖出或做空)。 在例子中,每次迭代我们买入 10 股 APPL 股票。更多 order() 信息,可参阅 Quantopian 文档 。
record() 函数能在每一次迭代的时候记录一些临时数据。 第一个参数接受 变量名=变量值 的这样参数。回测结束进行分析的时候,能够通过变量名访问到 这些记录的数据(下面会有示例)。您还可以看到如何在 data 事件框架中访问之前记录的 AAPL 股票的价格数据(更多信息请访问 这里 )
运行算法策略
zipline 提供三种方式
- 命令行
IPython Notebook-
run_algorithm()函数
命令行
zipline run -f ../../zipline/examples/buyapple.py --start 2016-1-1 --end 2018-1-1 -o buyapple_out.pickle
-f 指定策略算法路径 即文件路径
--start 和 --end 指定回测时间区间
-b 设置使用的数据(默认为 quandl)
-o 指定文件名,回测结果将以 DateFrame 的格式保存到 Python 的 pickle 文件内
-c 指定配置文件的路径,这样就不用每次都指定各种参数了(请参阅文档)
IPython Notebook 不作介绍
run_algorithm()运行
文档上没有说明,这种方式其实是ide中,程序内部中,使用python运行,实际是使用TradingAlgorithm类运行
传参方式
from zipline import TradingAlgorithm
import pandas as pd
def initialize(context):
pass
def handle_data(context, data):
pass
algo_obj = TradingAlgorithm(initialize=initialize,
handle_data=handle_data)
data = pd.read_csv('AAPL.csv')
perf_manual = algo_obj.run(data)
也可以使用继承
rom zipline.algorithm import TradingAlgorithm
import pandas as pd
class Strategy(TradingAlgorithm):
def initialize(self):
pass
def handle_data(self, data):
pass
if __name__ == '__main__':
data = pd.read_csv("AAPL.csv")
simple_algo = Strategy()
results = simple_algo.run(data)
当然,参数我没传完,还有回测时间 等。
重点是运行后,在实例化的时候报错了
zipline报错JSONDecodeError
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
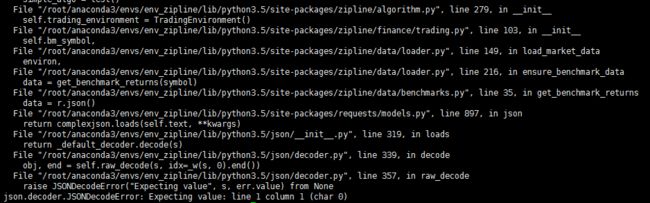
谷歌搜了半天也没找到问题,最后在zipline社区论坛github中找到了这个问题
zipline 1.3.0 JSONDecodeError
这个问题是当时一个月前发现的,是因为在benchmarks.py中使用IEX API获取基准数据的api于2019年6月15日删除,使用此API尝试下载任何库存数据都将报错,功能现在转移到新的API IEX Cloud,在请求时需要加上注册后用户的token
解决办法,修改benchmarks.py文件
def get_benchmark_returns(symbol):
"""
Get a Series of benchmark returns from IEX associated with `symbol`.
Default is `SPY`.
Parameters
----------
symbol : str
Benchmark symbol for which we're getting the returns.
The data is provided by IEX (https://iextrading.com/), and we can
get up to 5 years worth of data.
"""
IEX_TOKEN = 'pk_TOKEN_COMES_HERE' # 这里新增你在iex注册后拿到的令牌token
r = requests.get(
# 原代码删除
# 'https://api.iextrading.com/1.0/stock/{}/chart/5y'.format(symbol)
# 改为新连接
'https://cloud.iexapis.com/stable/stock/{}/chart/5y?token={}'.format(
symbol, IEX_TOKEN)
)
data = r.json()
df = pd.DataFrame(data)
df.index = pd.DatetimeIndex(df['date'])
df = df['close']
return df.sort_index().tz_localize('UTC').pct_change(1).iloc[1:]
新增IEX_TOKEN = '你的token '
'https://api.iextrading.com/1.0/stock/{}/chart/5y'.format(symbol)
更改
'https://cloud.iexapis.com/stable/stock/{}/chart/5y?token={}'.format(symbol, IEX_TOKEN)
这是更改基准下载方法以请求其他API的解决办法,还有人提出了通过将所有数据条目设置为零来创建虚拟基准文件,但不建议
没想到最后居然要改源代码,我也很绝望,希望之后Zipline Maintainers尽快修护这个问题