k-近邻算法
k-近邻算法一般流程
- 1收集数据:可以使用任何方法。
- 2准备数据:距离计算所需要的数值,最好是结构化的数据格式。
- 3分析数据:可以使用任何方法。
- 4训练算法:此步骤不适用于k-近邻算法。
- 5测试算法:计算错误率。
- 6使用算法:首先需要输入样本数据和结构化的输入结果,然后运行k-近邻算法判定输入数据分别属于那个分类,最后应用对计算出的分类执行后续的处理。
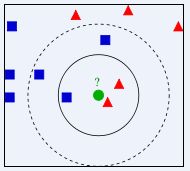
根据上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在, 我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。
- 如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。其关键还在于K值的选取,所以应当谨慎。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
KNN 算法本身简单有效,它是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。
python代码实现说明
科学计算包:numpy
运算符模块:operator
shape函数说明
shape函数是numpy.core.fromnumeric中的函数,它的功能是查看矩阵或者数组的维数
代码:
>>> a = array([[1,2,3],[5,6,9],[9,8,9]])
>>> a.shape
(3, 3)
>>> a.shape[0]
3
numpy.tile函数说明
函数形式:tile(A,rep)
功能:重复A的各个维度
参数类型:
A: Array类的都可以
rep:A沿着各个维度重复的次数
>>> a =array([[1,2,3],[5,6,9],[9,8,9]])
>>> tile(a,3)
array([[1, 2, 3, 1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9, 9, 8, 9]])
>>> tile(a,[3,2])
array([[1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9],
[1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9],
[1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9]])
>>> tile(a,[2,2,3])
array([[[1, 2, 3, 1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9, 9, 8, 9],
[1, 2, 3, 1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9, 9, 8, 9]],
[[1, 2, 3, 1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9, 9, 8, 9],
[1, 2, 3, 1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9, 9, 8, 9]]])
reps的数字从后往前分别对应A的第N个维度的重复次数。
如:
- tile(A,3)表示A的第一个维度重复3遍。
- tile(A,(3,2))表示A的第一个维度重复2遍,然后第二个维度重复3遍。
- tile(A,(2,2,3))表示A的第一个维度重复3遍,第二个维度重复2遍,第三个维度重复2遍。
sum函数说明
函数形式:sum(axis = 0 or 1)
函数功能:没有axis参数表示全部相加,axis=0表示按列相加,axis=1表示按照行的方向相加(取‘厉害’谐音)
>>> b = tile(a,[3,2])
>>> b
array([[1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9],
[1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9],
[1, 2, 3, 1, 2, 3],
[5, 6, 9, 5, 6, 9],
[9, 8, 9, 9, 8, 9]])
>>> c = b.sum(axis = 0)
>>> c
array([45, 48, 63, 45, 48, 63])
>>> d = b.sum(axis = 1)
>>> d
array([12, 40, 52, 12, 40, 52, 12, 40, 52])
>>> e = b.sum()
>>> e
312
>>>
argsort函数说明
函数形式:argsort(x) or x.argsort()
参数功能:argsort函数返回的是数组值从小到大的索引值
>>> x = array([3,4,2,5,1,6])
#按升序排列
>>> x.argsort()
array([4, 2, 0, 1, 3, 5])
#按升序排列
>>> argsort(-x)
array([5, 3, 1, 0, 2, 4])
>>>
sort函数、sorted函数说明
函数形式:sorted(iterable,cmp,key,reverse)
函数功能:排序
- sort对列表list进行排序,而sorted可以对list或者iterator进行排序
- sort函数对列表list进行排序时会影响列表list本身,而sorted不会
参数类型:
iterable:是可迭代类型;
cmp:用于比较的函数,比较什么由key决定;
key:用列表元素的某个属性或函数进行作为关键字,有默认值,迭代集合中的一项;
reverse:排序规则. reverse = True 降序 或者 reverse = False 升序,有默认值。
返回值:是一个经过排序的可迭代类型,与iterable一样。
>>> a = [7,3,9,4,1]
>>> sorted(a)
[1, 3, 4, 7, 9]
>>> a
[7, 3, 9, 4, 1]
>>> a.sort()
>>> a
[1, 3, 4, 7, 9]
operator.itemgetter函数
>>> a = [1,2,3]
>>> b = operator.itemgetter(1)//定义函数b,获取对象的第1个域的值
>>> b(a)
2
>>> b = operator.itemgetter(0,1)//定义函数b,获取对象的第1个域和第0个的值
>>> b(a)
(1, 2)
源码