一、 消息队列
1.1 队列与消息队列
简单的来说,消息队列就是基于“先进先出的一种数据结构”,在开发中经常会用到。但是在实际生产中,期望这个队列是高可用的(消除单节点故障)、高性能的(应对大流量冲击)、消息可靠性(持久化、认证)。所以对消息队列的要求就很高了。经常会用到RabbitMq、ActivityMq、RocketMQ等消息中间件提供消息队列的能力。

1.2 消息队列的作用
应用解耦

从可用性的角度来看,多个错误率底的子系统强耦合在一起,得到的是一个高错误率的整体系统。如图1-2,如果因为子系统的故障或者升级等原因造成暂时不可用,那么都会造成系统整体的故障,影响用户的使用体验。这时候如果变成基于消息队列的方式后,子系统之间使用队列通信,即使暂时的不可用,消息会缓存在队列中,等待系统修复后再进行相关逻辑
作为缓冲消除流量峰值
流量峰值:就像早高峰和晚高峰一样,在互联网的某些业务场景下,比如双11或者是春节抢火车票,短时间内会有大量请求进来,造成一个流量高峰。
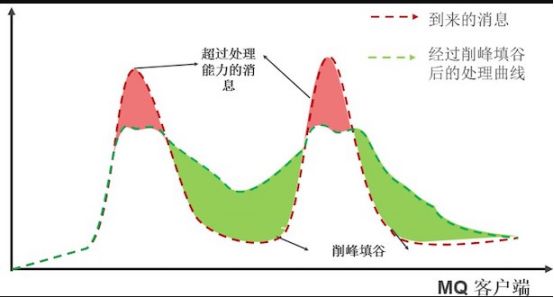
比如说一次秒杀活动,12:00:00 这一秒有1w个请求,但是12:00:00~12:10:00内平均每秒请求只有1000,如果有消息队列作为缓冲,系统只需要能支撑1000tps下不崩溃就可以,不需要加到1w tps不崩溃。
消息分发功能
在大数据时代,数据对很多公司来说就像金矿,公司需要依赖对数据的分析,进行用户画像 、精准推送、流程优化等各种操作, 并且对处理的实时性要求越来越高 数据是不断产生的,各个分析团队、算法团队都要依赖这些数据来进行工作,这个时候有个可持久化的消息队列就非常重要 数据的产生方只需要把各自的数据写人一个消息队列即可 数据使用方根据各自需求订阅感兴趣的数据,不同数据团队所订阅的数据可以重复也可以不重复,互不干扰,也不必和数据产生方关联

二、 RocketMq消息队列
2.1 概述
RocketMQ是一个消息中间件。rocketMq基于高可用分布式集群技术,提供消息发布订阅、消息轨迹查询、定时(延时)消息、持久化消息、资源统计、监控报警等一系列消息云服务,是目前较为优秀的消息队列中间件
2.2 架构及术语

术语说明:
| 角色 | 说明 |
|---|---|
| Producer | 生产者,用于将消息发送到RocketMQ,生产者本身既可以是生成消息,也可以对外提供接口,由外部来调用接口,再由生产者将受到的消息发送给MQ。 |
| Consumer | 消费者,从Broker拉取消息进行消费。从应用角度来说有两类消费者: |
| Broker | RocketMQ服务器,也是整个服务的核心,它实现了消息的存储、拉取功能。每个broker上提供对指定topic的服务。理解了broker的原理以及它和其他服务交互的过程,也就命令消息中间件的原理,其实都大同小异。它具有2中角色 : Master:能写、能读。 Slave:只能读,不能写 |
| Topic | 消息的主题,由用于定义并在服务端配置,消费者可以按照主题进行订阅,也就是消息分类,通常一个应用一个Topic |
| Message | 在生产者、消费者、服务器之间传递的消息,一个message必须属于一个Topic,以流传递,可以是文本消息也可以是媒体流消息 |
| Nameserver | 一个无状态的名称服务,可以集群部署,可以理解为注册中心,nameServer集群之间不互相通信 |
| Tag | 用于对消息进行过滤,理解文件message的子主题,同一业务不同目的的message可以用相同的topic但是可以用不同的tag来区分 |
结合上表格的术语说明可以丰富一下刚才的角色图

1.3 消息消费者
pull与push消费方式
在RocketMQ中消息消费者分为两种,PUSH 和 PULL,大多数场景使用的是 PUSH 模式,这两种模式分别对应的是 DefaultMQPushConsumer 类和 DefaultMQPullConsumer 类。PUSH 模式实际上在内部还是使用的 PULL 方式实现的,通过 PULL 不断地轮询 Broker 获取消息,当不存在新消息时,Broker 会挂起 PULL 请求(5秒后再check),直到有新消息产生才取消挂起,返回新消息。
在 push 方式中这是通过“长轮询”方式达到 Push 效果的方法,长轮询方式既有 Pull 的优点,又兼具 Push 方式的实时性。可以在 DefaultMQPushConsumer
源码中看到有大量的 PullRequest 语句。
流量控制
pushConsumer会通过processqueue来判断获取但未被消费但消息个数,消息总大小,offset但跨度,任何一个值超过设定大小就会隔一段时间再拉去消息,从而达到控制流量但目的。
在RocketMQ里限流是自动控制的,满足下面条件会触发流量限制
当前的ProcessQueue正在处理的消息数量>1000
队列中最大最小偏移量(Offset)差距>2000
限流的做法是放弃本次拉取消息的动作,并且这个队列的下一次拉取任务将在50毫秒后才加入到拉取任务队列。
2.4 消息生产者
消息生产者是用来向Broker发送消息,默认使用DefaultMQProducer类,发送消息主要有五个步骤
设置生产者的集群(GroupName)
设置实例名(InstanceName),同一个集群下的生产者实例名不能一样
设置发送失败重试次数
设置NameServer地址
组装消息并发送
消息的发送方式有三种,同步、异步、和ignore
同步发送消息,要等消息发送成功才返回成功,成功的定义:消息是否存储到磁盘,消息是否同步到Slave,消息是否在Slave上被写入磁盘。需要结合具体配置的刷盘策略、主从策略来定。
异步发送消息, 消息发送不返回结果,结果通过设置指定的类回调处理。
忽略结果,消息发送不返回结果,也不处理 回调,不管消息发送成不成功只管发送。这种模式用在不关心消息是否发送成功,消息发送成功与否对业务没有影响或者影响很小的情况
根据实际的业务场景、性能需求选择合适的消息发送模式。
此外RocketMq支持消息延迟,在生产者发送消息时设置,消息延迟只支持固定的时间模板
(1 s/5s/1 Os/30s/I m/2m/3m/4m/5m/6m/7m /8m /9m /10m/20m/30m/12h)
时间模板可以在启动RocketMQ Broker的时候配置
2.5 消息存储(Broker)
消息存储是RocketMq的核心,分布式队列对消息可靠性有高的要求,所以数据要通过磁盘去存储,对于高性能磁盘来说,磁盘存储的顺序写速度可达600MB/s,随机写速度大概只有100Kb/s。在RocketMq里面,处理磁盘存储的思路是:尽量保证顺序写。
相应的策略是:RocketMq使用两个存储文件相互配合,一个是ConsumerQueue,另一个是CommitLog,其中CommitLog是真正的物理存储文件,而consumerQueue作为一个中间的结构只存偏移信息,下图下方为一条消息的consumerQueue的格式,由偏移量、大小、Tag的Hashcode组成的。实际情况中大部分的consumerQueue都可以直接读入内存,所以速度很快。一个topic对应多个consumerQueue。

从上图可以看到,ConsumeQueue 中一条消息的格式为:
1.开头为CommitLog文件的Offset,通过Offset可以快速定位到消息的开头
2.第二个部分为消息的size,消息在CommitLog文件中开始和借宿的位置分别为Offset,Offset+size
3.Tag HashCode为上面属于介绍说到的属于Topic的一个子主题,用于区分同一个Topic下不同类型的消息,这里只存Tag的一个HashCode
MappedByteBuffer:“零拷贝”技术**
一般来说一台服务器把磁盘的内容发送给客户端,需要先read(file,tmp_buf,len)然后write(socket,tmp_buf,len),这两部操作包含:从磁盘复制数据到内核态内存,然后从内核态内存复制到用户态,从用户态内存复制到网络驱动的内核态内存,最后复制到网卡中进行传输,而使用Java 7中MappedByteBuffer,可以省去向用户态的内存复制,提高速度。
总的来说,RocketMq的存储机制使用了顺序写和随机读,顺序写使用CommitLog +ConsumerQueue实现,提升了写入效率。虽然读取是随机的,但是可以利用操作系统的pagecache机制,可以批量的从磁盘读取,作为cache存到内存中,加速后续的读取速度。