架构
ArangoDB的集群是遵循master/master架构的,没有单点故障,遵循CAP理论中的“CP”。“CP”的意思就是当发生网络分区通讯异常的时候,数据库优先考虑内部一致性而非可用性。使用“master / master”意味着客户端可以将其请求发送到任意节点,并且在每个节点上看到的数据库视图都是一致的。 “没有单点故障”意味着群集中任何一个节点完全宕机都不会对整个集群的服务产生任何影响,集群都可以继续提供服务。
通过这种方式,ArangoDB被设计为分布式多模型数据库。本节简要介绍了集群体系结构以及如何实现上述特性和功能。
ArangoDB集群
ArangoDB集群由许多ArangoDB实例组成,这些实例通过网络相互通信。它们分别具备不同的角色,关于各个角色的描述会在下面详细解释。集群的配置信息保存在“Agency”中,Agency是一个高度可用的弹性分布式键/值存储,agency服务由奇数个进行Raft复制的ArangoDB的实例组成。
对于ArangoDB集群中的各种实例,有4个不同的角色:Agent,Coordinator,Primary 和Secondary DBserver。下面我们将会对每种角色进行详细阐述。请注意,无论实例是哪种角色,实例都是基于同一个Docker镜像运行相同的二进制文件。ArangoDB集群的整体架构如下图所示:
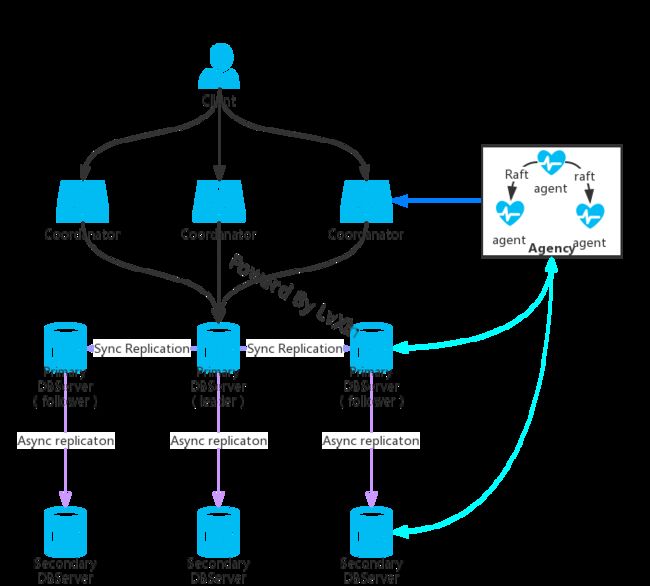
Agent
一个或多个Agent形成ArangoDB集群中服务“agency”。“agency”是整个集群配置信息的存储中心。“agency”执行leader选举并为整个群集提供其他同步服务。“agency”是整个集群的心脏,所有其他任何组件都依赖于“agency”。
“agency”对集群外部是不可见的。由于“agency”是整个ArangoDB集群的核心,因此必须具备高容错性。为了实现这一点,Agent之间采用Raft 一致性算法进行复制。
"agency"管理一个大型配置树。它支持在此树上执行事务性读取和写入操作,而其他服务器可以为树的所有更改订阅HTTP回调。
Coordinator
若外部client端需要访问ArangoDB,则必须通过Coordinator。它们将协调集群任务,如执行查询和运行Foxx服务。它们知道数据的存储位置,并优化用户提交的查询。Coordinator是无状态的,因此可以根据需要随时关闭或重新启动。
Primary DBserver
Primary DBserver是实际托管数据的服务器。它们托管数据分片并使用进行分片的同步复制,主分区可以是分片的领导者或跟随者。
Client端不应从外部直接访问它们,而应通过Coordinators间接访问它们。Coordinator向其发起查询,Primary DBserver负责执行部分或者全部查询。
Secondary DBserver
Secondary DBserver是Primary DBserver的异步复制。如果只使用同步复制,则根本不需要Secondary DBserver。对于每个Primary DBserver,可以有一个或多个Secondary DBserver。由于复制以异步方式工作(最终一致性),因此复制不会影响Primary DBserver的性能,但是,Secondary DBserver的数据副本可能会略微过时。Secondary DBserver非常适合用于备份,因为它们不会影响正常的群集服务和操作。
Cluster ID
群集中的每个非 agency ArangoDB实例在其启动时都会为其分配一个唯一的ID。使用该ID,可以在整个群集中识别节点。集群中的所有操作都将通过此ID进行各个实例间的互相通信。
Sharding
ArangoDB集群以Shard的形式在各个Primary DBserver之间分布数据,而这个过程对集群外部来说是完全透明的,通过这种方式,我们实现了“主 - 主复制”。Client端可以与任何Coordinator通信,无论何时读取或写入数据,Coordinator都会自动确定最优的数据读取或写的位置。各个Shard的相关信息也是存储在“agency”中,各个Coordinator通过“agency”实现了Shard的信息的共享。
集群配置建议
ArangoDB的架构非常灵活,允许进行多种配置,以适用于不同的使用场景:
1.默认配置是在每台计算机上运行一个coordinator和一个Primary DBserver。这样就自然的实现了经典的主/主设置,因为在不同节点之间存在完美的对称性,Client可以与任何一个协调器进行通信,并且所有Client看到的数据视图都是一致的。
2.可以部署比DBservers更多的coordinators。当需要部署大量的Foxx服务时,这种方式比较适合,因为Foxx是运行在coordinator上的。
3.如果数据量比较大,而查询请求并不多,则可以部署的DBServer的数量可以比Coordinator多。
4.DBServer与coordinator分开部署。可以在应用程序服务器(例如node.js服务器)上部署Coordinator,在另外的独立的服务器上部署agent程序和DBServer。这避免了应用服务器和数据库之间的网络调准次数,从而减少了延迟。从本质上讲,这会将一些数据库分发逻辑移动到客户端运行的机器上。
综上所述:Coordinator层是可以独立于DBServer层进行独立部署和扩展的。
Replication
ArangoDB在集群内部提供了两种data repliation的方式:同步和异步。下面我们将会分别对这两种方式进行详细说明。
具备自动FailOver特性的同步复制
ArangoDB可以基于每个Shard进行同步复制。您可以针对每个collection配置每个分片的副本数。任何时候,只要某个shard中的其中一个副本声明为“leader”,所有其他副本就都是“follower”。针对此shard的写入操作始终发送到持有leader副本的DBserver,该DBServer在完成本地副本的写入之后,会将更改同步复制到所有的follower,只有在所有的follower都复制成功之后,才会报告给Coordinator并视为该写入操作完成。读取操作也都由持有leader副本的DBServer提供服务,这样就可以为复杂事务提供快照语义。
如果持有某个Shard follower副本的DBserver宕机,则leader将无法再将其更改与该跟follower同步。在短暂的超时(3秒)之后,leader就会放弃该follower,并声明该follower已经out of sync,并将该follower排除在外,继续服务。当持有follower副本的DBServer恢复正常后,它会自动将其数据与leader重新同步,并恢复同步复制。
若持有某个shard的leader副本的DBServere宕机,那么该leader将不再服务于任何请求。它也不再向“agency”发送心跳。因此,“agency”Raft leader中的监控进程将会采取必要措施(在丢失心跳15秒之后),即将持有该shard的follower中的一个DBServer提升为该shard的leader。这会涉及到agency的重新配置,并导致coordinator将对该shard的请求定位到新的leader上。其他的follower会自动将其数据与新的leader重新同步。当具有原始leader副本的DBserver恢复时,它发现已经产生了新的leader,因此它会将其数据与新领导者重新同步。
所有shard的数据同步都以增量方式完成,通过这种方式重新同步会很快。通过这种同步方式可以在不中断服务的情况下,完成shard在不同DBServer之间的移动。因此,ArangoDB集群可以将特定DBServer上的所有数据移动到其他DBServer,然后关闭该服务器,通过这种方式,可以在不中服务,不丢失数据的前提下进行ArangoDB集群缩容。此外,可以手动或自动进行shard的rebalance。
所有这些操作都可以通过REST / JSON API或图形Web UI触发。所有故障转移操作都在ArangoDB集群中自动完全的。
显然,同步复制会降低写入的性能(导致写入操作延时增加)。但是,用户可以将复制因子设置为1,这意味着只保留每个分片的一个副本,从而关闭同步复制。对于低延迟写入操作很重要但是又不太重要或易于恢复的数据,将复制因子设置为1比较合适。
具备自动FailOver特性的同步复制
异步复制的工作机制与同步复制不同,因为它涉及到使用primary dbserver和secondary dbserver。每个secondary dbserver通过异步方式轮询来复制primary dbserver上保存的所有数据。这个过程对primary dbserver的性能影响很小。缺点是在secondary dbserver上的数据更新要晚于primary dbserver上的数据,存在数据更新的延时。如果primary dbserver在此延时期间宕机,则提交和确认的数据可能会丢失。
不过,arangodb还针对异步复制提供了自动故障转移功能。与同步复制情况相反,此处故障转移管理是在ArangoDB集群外部完成的。在未来的版本中,arangodb可能会将此功能移至agency中,但截至目前,该功能是通过ArangoDB的Mesos框架调度程序完成的(见下文)。
异步复制的粒度是一个完整的ArangoDB实例,包含驻留在该实例上的所有数据,这意味着若启动异步复制,那么arangodb的实例数量将会翻倍。相比而言,同步复制更灵活,在同步复制中实例的大小是随意的,而且如果一个dbserver失败,则可以在剩余的dbserver之间重新平衡数据。
微服务与零运维
ArangoDB的设计和功能适用于微服务架构。使用Foxx服务,可以非常轻松地在ArangoDB集群中部署以数据为中心的微服务。
此外,可以在同一个项目中部署多个ArangoDB实例。项目的一些模块可能需要可扩展的文档存储,另一部分可能需要图形数据库,而另一部分可能需要混合各种数据模型的多模型数据库的全部功能。通过将单一技术用于项目中的各个模块,可以极大地提升效率。
为了尽量减少arangodb的运维成本,我们尽可能地实现ArangoDB的零管理与零运维。正在运行的ArangoDB集群可以实现故障自愈。
Apache Mesos 集成
对于分布式部署,ArangoDB默认使用Apache Mesos作为基础部署组件。 ArangoDB是一个通过了全部认证的DC / OS软件包,一旦拥有现有的DC / OS集群,就可以简单地完成快速部署。即使在一个普通的Apache Mesos集群上,也可以只需一个API调用和一些JSON配置,通过Marathon完成ArangoDB的部署。
这种方式的优点是我们不仅可以实现初始部署,还可以实现后续的自动failover和ArangoDB集群的扩容(手动或甚至自动触发)。由于所有操作都是通过图形Web UI或通过JSON / REST调用,因此甚至可以非常轻松地实现自动缩放。
因为DC / OS集群部署各种服务非常方便,所以是部署微服务架构的非常自然的环境,包括在同一DC / OS集群中可能存在多个ArangoDB集群实例。内置的服务发现使得连接各种微服务变得非常简单,Mesos会自动处理各种任务的分发和部署。
查看 部署 章节,了解如何完成集群化部署。
可以通过简单地使用正确的命令行选项启动一批Docker容器来构建ArangoDB集群,甚至可以在单个机器上启动多个ArangoDB进程来部署ArangoDB集群。在这种方式下,在部署的ArangoDB集群中将会采用同步复制,并且可以提供自动failover的功能。但是,由于ArangoDB集群本身无法启动其他实例,因此无法自动更换故障节点,并且必须手动就进行扩容和缩容。因此不建议在生产环境采用这种方式进行部署。
数据模型及扩展性
本节说明ArangoDB支持的不同的数据模型。
Key/value 模型
K/V数据模型是最容易扩展的。在ArangoDB中,由于文档集合始终具有主键_key属性,因此很容易给予文档实现K/V存储,并且不存在其他二级索引的情况下,文档集合的行为类似于简单的K/V存储。
在K/V模型中唯一的操作就是单键查找和单键/值对插入和更新。如果_key是唯一的分片属性,则分片是相对于主键完成的,这时所有这些操作都是线性缩放的。如果_key是唯一的分片属性或者根据文档中的其他属性值进行分片,则即使查找单个键也会涉及访问所有分片,因此服务能力不能线性扩展。
Document模型
Document模型中,即使存在二级索引,二级索引也和以及索引的属性基本相同,因为分片集合的索引与每个分片的本地索引基本相同。因此,单个文档操作仍然会随着群集的大小线性扩展,除非特殊的分片配置才会是的文档操作(查询和写入)的性能及其低下。
更深入的分析,请参考 这篇博客 其中说明了如何实现ArangoDB对单文档操作的线性可伸缩性。
复杂查询和Join
AQL查询语言支持复杂查询,二级索引以及join。特别是二级索引以及join查询,这种操作的性能无法给予集群规模进行提升,因为如果要加入的数据驻留在不同的机器和分片上,则必须扫描所有的分片。 AQL查询执行引擎在整个集群中组织数据管道,以最有效的方式汇总结果。查询优化器知道集群的拓扑结构,并知道哪些数据在哪里以及如何编制索引。因此,它可以在针对查询的哪些部分应该在集群中的哪个位置运行时做出明智的决策。
虽然入册,但是对于某些复杂的join查询,能采取的优化措施还是有限的。
图数据库
图形数据库特别适用于涉及进行未知长度路径的查询。例如:在图中的两个顶点之间找到最短路径,或者找到与在给定顶点处开始的特殊匹配的所有路径。
但是,如果路径上的顶点和边分布在整个集群中,则需要在节点和分片之间需要进行大量的通信,性能就会受到影响。为了在规模上实现良好性能,则需要在集群中的分片中合理地分布数据。大多数时候,ArangoDB的应用程序开发人员和用户最了解他们的图表是如何构建的。因此,ArangoDB允许用户根据图数据的分片来指定。一个比较有效的优化措施就是:确保始发于某个顶点的边与该顶点位于同一个分片或者节点上。
限制
ArangoDB没有水平伸缩性限制。核心的“agency”模块可以轻松地支持数百台DBServer和Coordinator,一般的数据库操作都是完全分布式的,一般不需要“agency”的介入。
同样,Agency的监控进程可以轻松监控大量服务器,因为监控进程的所有活动都不需要高性能。
显然,ArangoDB集群受CPU,内存,磁盘和网络带宽和延迟等可用资源的限制。
参考:
https://docs.arangodb.com/3.3/Manual/Scalability/Architecture.html
https://docs.arangodb.com/3.3/Manual/Scalability/DataModels.html