hive的库、表等数据实际是hdfs系统中的目录和文件,让开发者可以通过sql语句, 像操作关系数据库一样操作文件内容, 比如执行查询,统计,插入等操作。一直很好奇hive是如何做到这些的。通过参考网上几篇不错的文档, 有点小心得分享出来。主要的参考链接
http://tech.meituan.com/hive-sql-to-mapreduce.html
http://www.slideshare.net/recruitcojp/internal-hive
注明:本文的图片借用slideshare内容。
hive的整体架构图如下所示, compiler部分负责把HiveSQL转换成MapReduce任务。
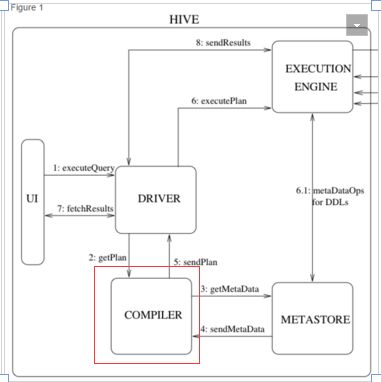
基本转换步骤
hiveSQL转换成MapReduce的执行计划包括如下几个步骤:
HiveSQL ->AST(抽象语法树) -> QB(查询块) ->OperatorTree(操作树)->优化后的操作树->mapreduce任务树->优化后的mapreduce任务树

SQL Parser:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象 语法树AST Tree;
Semantic Analyzer:遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
Logical plan:遍历QueryBlock,翻译为执行操作树OperatorTree;
Logical plan optimizer: 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
Physical plan:遍历OperatorTree,翻译为MapReduce任务;
Logical plan optimizer:物理层优化器进行MapReduce任务的变换,生成最终的执行计划;
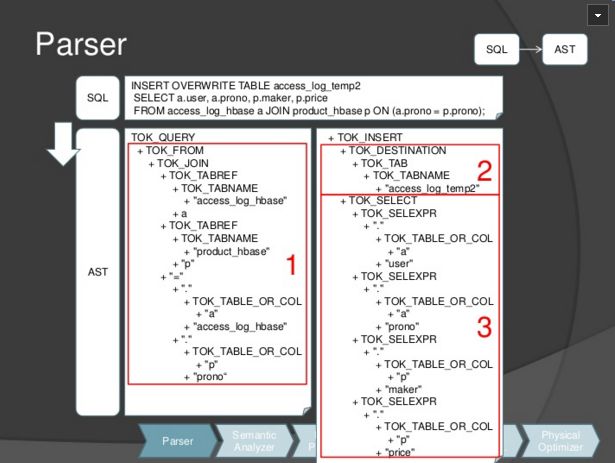
step1: SQL Parser
如下图所示, sql语句可以解析为三个部分
AST中第一个部分对应SQL语句中FROM access_log_hbase a JOIN product_hbase p ON (a.prono=p.prono)。
insert overwrite table对应第二部分。
select a.user, a.prono, p.maker, p.price对应第三部分。
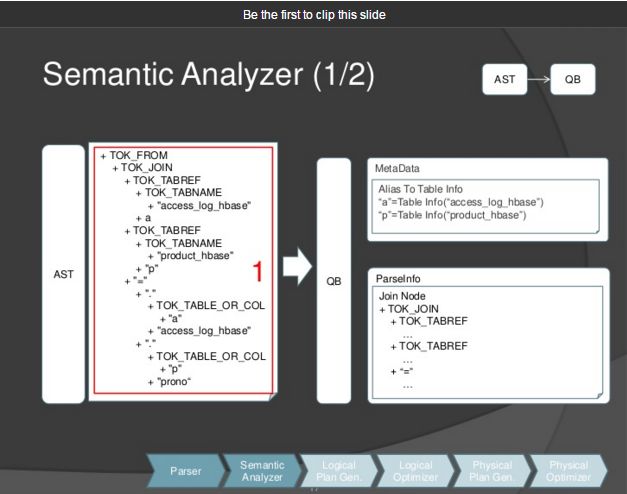
step2: Semantic Analyzer
这个步骤把AST转换成基本的查询块QB,如下图所示
QB的对象包括如下属性:
aliasToTabs:保存表格别名的信息
aliasToSubq:保存子查询的信息
qbm:保存每个输入表的元信息,比如表在HDFS上的路径,保存表数据的文件格式等
QBParseInfo对象包括如下属性:
joinExpr: 保存TOK_JOIN节点信息
destToxx:保存输出和各个操作的ASTNode节点的对应关系。

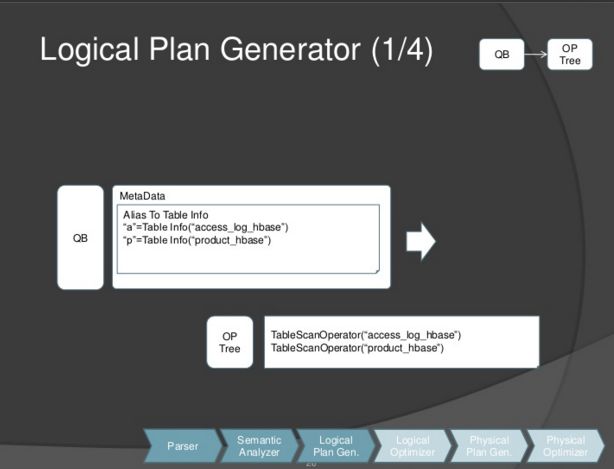
如下图中, 表格别名a, p保存到aliasTotabs, 分别对应“access_log_hbase", " product_hbase"。
TOK_JOIN信息保存到ParseInfo对象:joinExpr
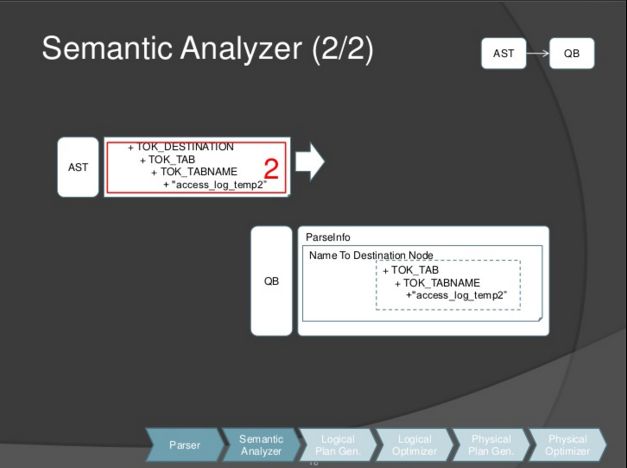
下图所示,TOK_DESTINATION节点保存到nameToDest属性中。
下图所示,TOK_SELECT节点保存到nameToDest属性中。

step3:Logical Plan
该步骤是把查询块QB转换操作树。
操作树基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator。
TableScanOperator: 扫描数据表中数据,从原表中取数据。
JoinOperator完成Join操作。
FilterOperator完成过滤操作, 对应sql里面的where语句功能
ReduceSinkOperator:标志着Hive Map阶段的结束, Reduce阶段的开始。
SelectOperator:reduce阶段输出select中的列
FileSinkOperator: 生成结果数据到输出文件。
从两个输入表格中读入数据, 用operator树表示为两个TableScanOperator节点
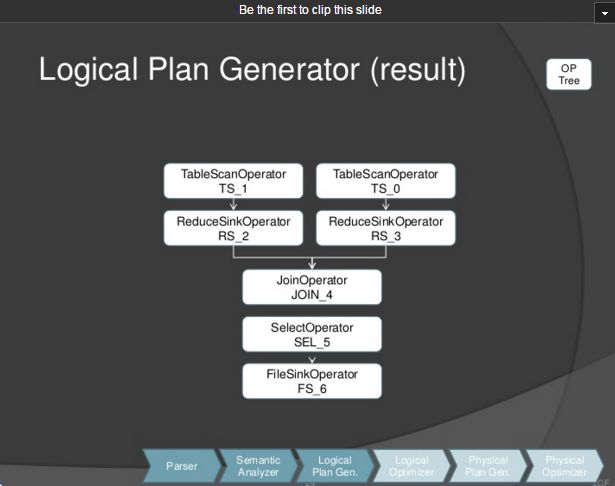
Join放在reduce阶段执行, 执行join节点前,加入两个ReduceSinkOperator节点,表示当前map阶段结束, 进入到reduce阶段。

selectoperator节点,从reduce节点获取select指定的列值。

nameToDest ASTNode节点,转换为FileSinkOperator节点, 把结果写入到目标文件。

通过上面几个转换步骤, 最终生成的logical计划树。
logical plan tree还可以通过logical plan optimizer进一步优化, 优化完成的逻辑优化树还有转换成物理执行计划和物理执行计划优化。本文不做详细介绍, 后续有时间再补充。
PS: 查看hive sql编译后的执行计划
hive> explain select * from tablename;
参考文档:
http://tech.meituan.com/hive-sql-to-mapreduce.html
http://www.slideshare.net/recruitcojp/internal-hive
http://lxw1234.com/archives/2015/09/476.htm