参考四月党同好的crawl思路 ,爬取URL:https://www.pixiv.net/search.php?s_mode=s_tag&word=%E5%AE%AB%E5%9B%AD%E8%96%B0
1).模拟登录 pixiv登录入口
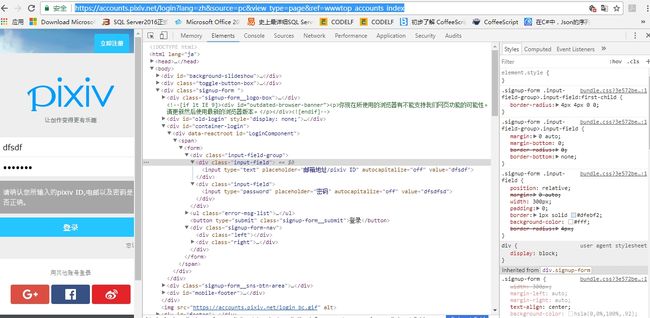
analysis.jpg
解析DOM结构时,未发现表单字段name值,模拟表单post,
email字段name值为pixiv_id,password的name值为password
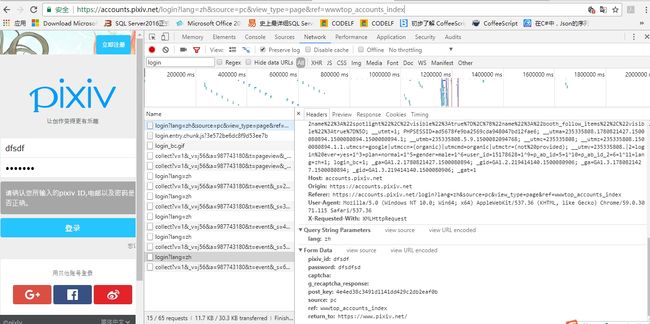
fromdata
分析URL
- 登录URL https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index
- 用户设置URL https://www.pixiv.net/setting_profile.php
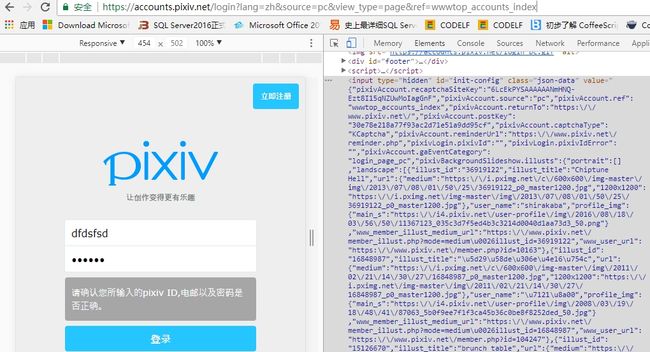
测试是否允许跟踪Cookies(ps:这里用题主的账号测试,求不黑)
import requests
session = requests.Session()
params ={'pixiv_id':'[email protected]','password':'knxy0616'}
s = session.post("https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index",params)
print("Cookies is set to:")
print(s.cookies.get_dict())
print("-------------------")
print("Going to Page")
s = session.get("https://www.pixiv.net/setting_profile.php")
print(s.text)
console output
C:\Users\26645\AppData\Local\Programs\Python\Python36\python.exe F:/pythonProject/PixivSpider/PixivChange.py
Cookies is set to:
{'PHPSESSID': '215f3e623ac9dda164ba310349d62f34', 'p_ab_id': '7', 'p_ab_id_2': '0'}
-------------------
Going to Page
イラスト コミュニケーションサービス[pixiv(ピクシブ)]
- 构造请求头
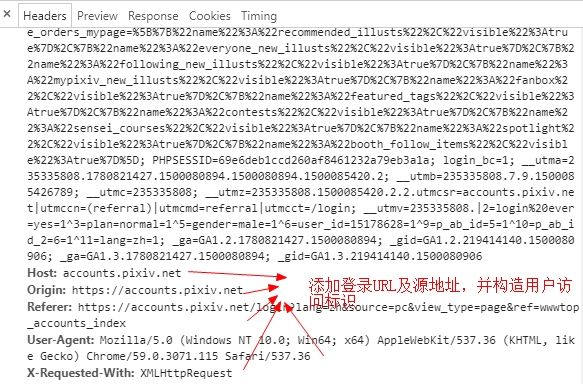
header.jpg
def _init_(self):
self.base_url = 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index'
self.login_url = 'https://accounts.pixiv.net/api/login?lang=zh'
self.target_url = 'https://www.pixiv.net/search.php?s_mode=s_tag&word=%E5%AE%AB%E5%9B%AD%E8%96%B0'
self.main_url = 'http://www.pixiv.net'
self.headers = {
'Host': 'accounts.pixiv.net',
'Origin': 'https://accounts.pixiv.net',
'Referer': 'https: // accounts.pixiv.net / login'
'?lang = zh & source = pc & view_type = page & ref = wwwtop_accounts_index',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
- 构造请求体
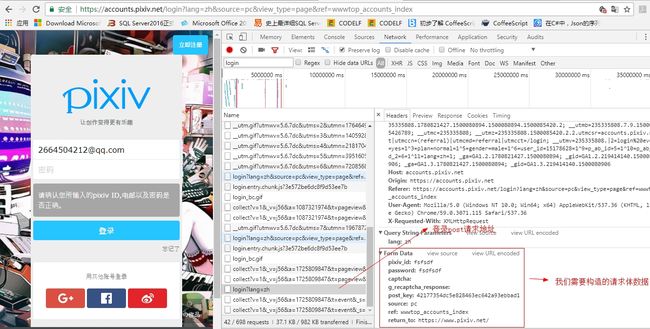
from.jpg
self.pixiv_id = 'userid',
self.password = '*****',
self.post_key = []
self.return_to = 'https://www.pixiv.net/'
#存放图片路径
self.load_path = 'F:\work\picture'
self.ip_list = []
- 捕捉需要获取的字段
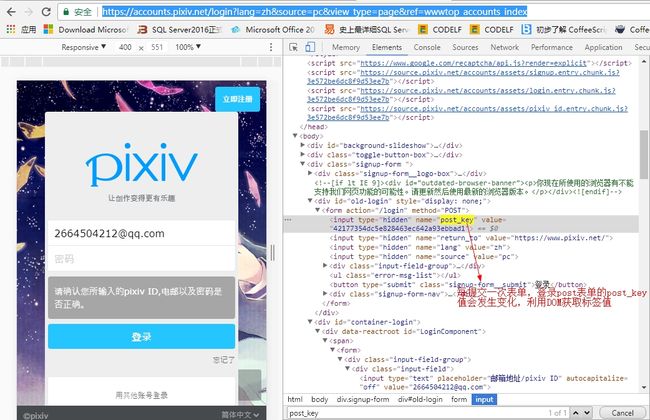
Post_Key.jpg
def login(self):
post_key_xml = self.get(self.base_url,headers = self.headers).text
post_key_soup = BeautifulSoup(post_key_xml,'lxml')
self.post_key = post_key_soup.find(name='post_key')['value']
#构造请求体
data = {
'pixiv_id': self.pixiv_id,
'password': self.password,
'post_key': self.post_key,
'return_to': self.return_to
}
#模拟登录post
self.post(self.base_url,data=data,headers=self.headers)
- 测试登录
import requests
from bs4 import BeautifulSoup
se = requests.Session()
class Pixiv(object):
def __init__(self):
self.base_url = 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index'
self.login_url = 'https://accounts.pixiv.net/api/login?lang=zh'
self.target_url = 'https://www.pixiv.net/search.php?s_mode=s_tag&word=%E5%AE%AB%E5%9B%AD%E8%96%B0'
self.main_url = 'http://www.pixiv.net'
self.headers = {
# 'Host': 'accounts.pixiv.net',
# 'Origin': 'https://accounts.pixiv.net',
'Referer': 'https: // accounts.pixiv.net / login'
'?lang = zh & source = pc & view_type = page & ref = wwwtop_accounts_index',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest'
}
self.pixiv_id = 'userid',
self.password = 'password',
self.post_key = []
self.return_to = 'https://www.pixiv.net/'
# 存放图片路径
self.load_path = 'F:\work\picture'
self.ip_list = []
def login(self):
post_key_xml = se.get(self.base_url, headers=self.headers).text
post_key_soup = BeautifulSoup(post_key_xml, 'lxml')
self.post_key = post_key_soup.find('input')['value']
# 构造请求体
data = {
'pixiv_id': self.pixiv_id,
'password': self.password,
'post_key': self.post_key,
'return_to': self.return_to
}
se.post(self.login_url, data=data, headers=self.headers)
if __name__ == '__main__':
pixiv = Pixiv()
pixiv.login()
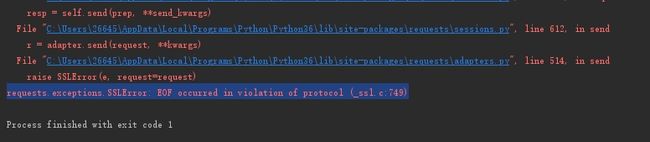
console output:事故现场,遭遇反爬
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "F:/pythonProject/PixivSpider/PixivChange.py", line 99, in
pixiv.login()
File "F:/pythonProject/PixivSpider/PixivChange.py", line 84, in login
post_key_xml = se.get(self.base_url, headers=self.headers).text
File "C:\Users\26645\AppData\Local\Programs\Python\Python36\lib\site-packages\requests\sessions.py", line 515, in get
return self.request('GET', url, **kwargs)
File "C:\Users\26645\AppData\Local\Programs\Python\Python36\lib\site-packages\requests\sessions.py", line 502, in request
resp = self.send(prep, **send_kwargs)
File "C:\Users\26645\AppData\Local\Programs\Python\Python36\lib\site-packages\requests\sessions.py", line 612, in send
r = adapter.send(request, **kwargs)
File "C:\Users\26645\AppData\Local\Programs\Python\Python36\lib\site-packages\requests\adapters.py", line 514, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: EOF occurred in violation of protocol (_ssl.c:749)
看了一下这位朋友的讲解,爬虫的作用是将找到的大量数据爬取到本地,
通常网站管理员会用限制ip频率的方式进行反爬虫,找了一个ip代理池维护访问ip
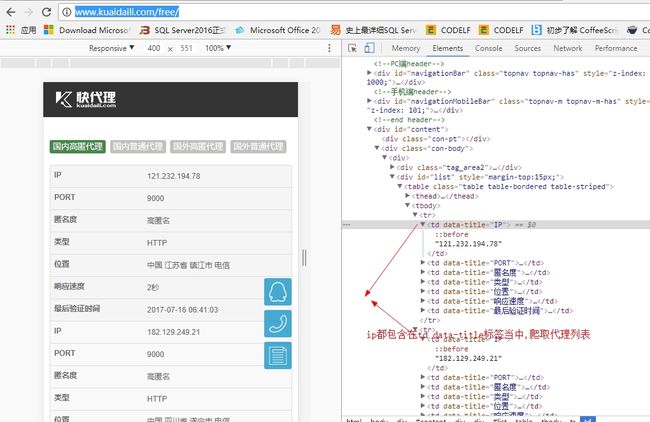
Ip_Proxy.jpg
- 获取ip代理池 (ps:若要使用正则:
r'(.*?)') def get_proxy(self): html = requests.get("http://www.kuaidaili.com/free/") # bsObj=BeautifulSoup(html,"html.parser",from_encoding="iso-8859-1") bsObj = BeautifulSoup(html.text, 'html.parser') ip_info_ip = bsObj.findAll("td", {"data-title": "IP"}) ip_info_port = bsObj.findAll("td", {"data-title": "PORT"}) # print(ip_info_ip) i = 0 for ip_info in ip_info_ip: ip_info = str(ip_info_ip[i].text) + ':' + str(ip_info_port[i].text) i = i + 1 self.ip_list.append(ip_info) print(ip_info)console output: 拿到IP代理池
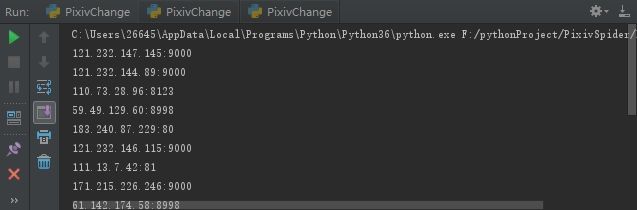 ip_list.jpg
ip_list.jpg接着我们需要设置爬取网页错误时,设置延时及时更换ip代理
6)设置http代理延时构建思路:
- 检查爬取网站是否有空闲的动态端口(ps:p站看起来不太可能有,加个判断以防万一),如果有发出一个get请求获取页面
- 随机从ip列表中用5个ip进行尝试
- 给定一个5秒的延时。将之前构建的代理池ip随机选择一条,如果失败则尝试ip总数-1,否则开始使用ip代理
def get_html(self, url, timeout,proxy=None, num_entries=5): if proxy is None: try: return se.get(url,headers=self.headers,num_entries=5,timeout=timeout) except: if num_entries > 0: print('获取网页出错,5秒后将会重新倒数第',num_entries,'次') time.sleep(5) return self.get_html(url,timeout,num_entries=num_entries-1) else: print('开始使用代理') time.sleep(5) ip = ''.join(str(random.choice(self.ip_list))).strip() now_proxy = {'http':ip} return self.get_html(url,timeout,proxy=now_proxy) else: try: return se.get(url,headers =self.headers,proxy=proxy,timeout=timeout) except: if num_entries>0: print('正在更换代理,5秒后重新获取第',num_entries,'次') time.sleep(5) ip = ''.join(str(random.choice(self.ip_list))).strip() now_proxy = {'http': ip} return self.get_html(url, timeout, proxy=now_proxy) else: print('使用代理失败') return self.get_hmtl(url.timeout) def work(self): self.login() for page_num in range(1,10): path = str(page_num) now_html = self.get_html(self.target_url+str(page_num),3) print('第{page}被保存完毕',format(page=page_num)) time.sleep(2)console ouput
 python.jpg
python.jpg依然反爬。。emmm查看全部日志发现,json字符串中的posetkey未拿到,于是回过来单独拿下json试试
 json.jpg
json.jpg- 获取json测试SSLERROR
def get_json(self): html = se.get(self.base_url,params=self.params) start = html.text.find(r'') self.json_data = html.text[start:end] print(self.json_data) def work(self): self.login() for page_num in range(1,10): path = str(page_num) now_html = self.get_html(self.target_url+str(page_num),3) print('第{page}被保存完毕',format(page=page_num)) time.sleep(2) if __name__ == '__main__': pixiv = Pixiv() pixiv.get_json()console output
 SSLError.jpg
SSLError.jpg
解决方法 :原来是因为在访问服务器的同时,需要配置SSL证书进行伪装,对比了下自己的情况,install pyOpenssl就好了7)利用BeatifulSoup模拟登录
import random import requests from bs4 import BeautifulSoup from urllib.request import urlopen import re import os import time from selenium import webdriver import ssl se = requests.Session() chromedriver ="F:\dirver\chromedriver.exe" os.environ["webdriver.chrome.driver"] =chromedriver class Pixiv(object): def __init__(self): self.base_url = 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index' self.login_url = 'https://accounts.pixiv.net/api/login?lang=zh' self.target_url = 'https://www.pixiv.net/search.php?s_mode=s_tag&word=%E5%AE%AB%E5%9B%AD%E8%96%B0' self.main_url = 'http://www.pixiv.net' self.params = { 'lang': 'zh', 'source': 'pc', 'view_type': 'page', 'ref': 'wwwtop_accounts_index' } self.headers = { # 'Host': 'accounts.pixiv.net', # 'Origin': 'https://accounts.pixiv.net', 'Referer': 'https: // accounts.pixiv.net / login' '?lang = zh & source = pc & view_type = page & ref = wwwtop_accounts_index', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)' ' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36', # 'X-Requested-With': 'XMLHttpRequest' } self.pixiv_id = 'userid', self.password = 'pwd', self.post_key = [] self.return_to = 'https://www.pixiv.net/' # 存放图片路径 self.load_path = 'F:\work\picture' self.ip_list = [] self.json_data = "" def login(self): # se.headers = self.headers # r = se.get(self.login_url,params=self.params) # pattern = re.compile(r'name="post_key"value="(.*?)">') # result = pattern.findall(r.text) # self.post_key = result[0] # 构造请求体 post_key_html = se.get(self.base_url,headers= self.headers).text post_key_soup = BeautifulSoup(post_key_html,'lxml') self.post_key = post_key_soup.find('input')['value'] data = { 'pixiv_id': self.pixiv_id, 'password': self.password, 'post_key': self.post_key, 'return_to': self.return_to } q = se.post(self.login_url, data=data, headers=self.headers) result = se.get(self.main_url) print(q.text) print(result.text) def get_proxy(self): html = requests.get("http://www.kuaidaili.com/free/") # bsObj=BeautifulSoup(html,"html.parser",from_encoding="iso-8859-1") bsObj = BeautifulSoup(html.text, 'html.parser') ip_info_ip = bsObj.findAll("td", {"data-title": "IP"}) ip_info_port = bsObj.findAll("td", {"data-title": "PORT"}) # print(ip_info_ip) i = 0 for ip_info in ip_info_ip: ip_info = str(ip_info_ip[i].text) + ':' + str(ip_info_port[i].text) i = i + 1 self.ip_list.append(ip_info) print(ip_info) def get_html(self, url, timeout,proxy=None, num_entries=5): self.get_proxy() if proxy is None: try: return se.get(url,headers=self.headers,num_entries=5,timeout=timeout) except: if num_entries > 0: print('获取网页出错,5秒后将会重新倒数第',num_entries,'次') time.sleep(5) return self.get_html(url,timeout,num_entries=num_entries-1) else: print('开始使用代理') time.sleep(5) ip = ''.join(str(random.choice(self.ip_list))).strip() now_proxy = {'http':ip} return self.get_html(url,timeout,proxy=now_proxy) else: try: return se.get(url,headers =self.headers,proxy=proxy,timeout=timeout) except: if num_entries>0: print('正在更换代理,5秒后重新获取第',num_entries,'次') time.sleep(5) ip = ''.join(str(random.choice(self.ip_list))).strip() now_proxy = {'http': ip} return self.get_html(url, timeout, proxy=now_proxy,num_entries=num_entries-1) else: print('使用代理失败') return self.get_hmtl(url.timeout) def work(self): self.login() for page_num in range(1,10): path = str(page_num) now_html = self.get_html(self.target_url+str(page_num),3) print('第{page}被保存完毕',format(page=page_num)) time.sleep(2) if __name__ == '__main__': pixiv = Pixiv() pixiv.login()console output*:拿到验证信息,验证返回校验的hash字符串一致
 token.jpg
token.jpg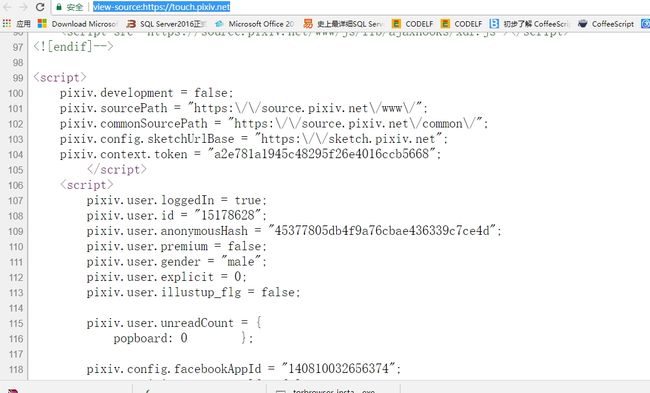 entype.jpg
entype.jpg2.创建爬取文件夹
def mkdir(self,path): path = path.strip() is_exist =os.path.exists(os.path.join(self.load_path,path)) if not is_exist: print('创建一个名字为 '+path+' 的文件夹') os.makedirs(os.path.join(self.load_path,path)) os.chdir(os.path.join(self.load_path,path)) return True else: print('名字为 '+path+' 的文件夹已经存在') os.chdir(os.path.join(self.load_path,path)) return False mkdir.jpg
mkdir.jpg3 从爬取页面抓取图片
以第一张素描照片为例:图片信息URL =main_url+href包含标签值
素描图躺着的地方~:div class="work-display"下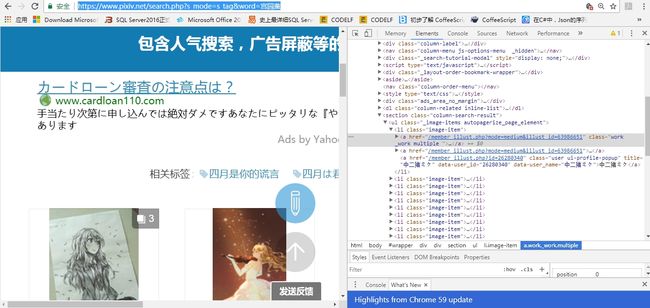 target_url.jpg
target_url.jpg jump_to_img.jpg
jump_to_img.jpg1)获取保存图片信息的所有
li标签列表def get_img(self,html,page_num): li_soup =BeautifulSoup(html,'lxml') li_list = li_soup.find_all('li',attrs={'class','image-item'}) for li in li_list: href = li.find('a')['href'] print(href) jump_to_url =self.main_url +href jump_to_html = self.get_html(jump_to_url,3).text img_soup =BeautifulSoup(jump_to_html,'lxml') img_info = img_soup.find('div',attrs={'class','work_display'})\ .find('div',attrs={'class','_layout-thumbnail'}) if img_info is None: continue self.download_img(img_info,jump_to_url,page_num)- 获取图片信息同时,保存图片信息到指定文件中
def download_img(self,img_info,href,page_num): title = img_info.find('img')['alt'] src =img_info.find('img')['src'] src_headers = self.headers src_headers['Referer'] = href try: html =requests.get(src,headers=src_headers) img=html.content except: print('爬取图片失败') return False title = title.replace('?', '_').replace('/', '_').replace('\\', '_').replace('*', '_').replace('|', '_').\ replace('>', '_').replace('<', '_').replace(':', '_').replace('"', '_').strip() # 去掉那些不能在文件名里面的.记得加上strip()去掉换行 if os.path.exists(os.path.join(self.load_path,str(page_num)),title+'.jpg'): for i in range(1,100): if not os.path.exists(os.path.join(self.load_path,str(page_num),title+str(i))+'.jpg'): title = title+str(i) break; print('正在保存名字为: '+title+' 的图片') with open(title+'.jpg','b') as f: f.write(img) print('保存该图片完毕')console output
 onSuccess.jpg
onSuccess.jpg picture.jpg
picture.jpg然而因为中途撤掉了代理,所以爬了五张就挂了,qwq我的大四月啊~
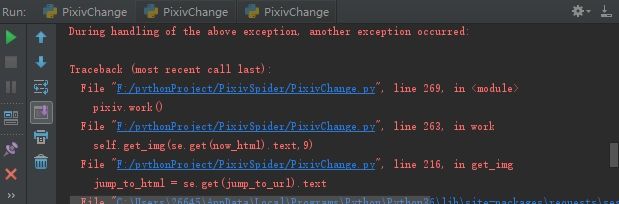 NoProxy.jpg
NoProxy.jpg代码清单
import random import requests from bs4 import BeautifulSoup from urllib.request import urlopen import re import os import time from selenium import webdriver import ssl se = requests.Session() chromedriver ="F:\dirver\chromedriver.exe" os.environ["webdriver.chrome.driver"] =chromedriver class Pixiv(object): def __init__(self): self.base_url = 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index' self.login_url = 'https://accounts.pixiv.net/api/login?lang=zh' self.target_url = 'https://www.pixiv.net/search.php?word=%E5%AE%AB%E5%9B%AD%E8%96%B0&order=date_d' self.main_url = 'http://www.pixiv.net' self.params = { 'lang': 'zh', 'source': 'pc', 'view_type': 'page', 'ref': 'wwwtop_accounts_index' } self.headers = { # 'Host': 'accounts.pixiv.net', # 'Origin': 'https://accounts.pixiv.net', 'Referer': 'https: // accounts.pixiv.net / login' '?lang = zh & source = pc & view_type = page & ref = wwwtop_accounts_index', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)' ' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36', # 'X-Requested-With': 'XMLHttpRequest' } self.pixiv_id = 'userid', self.password = 'pwd', self.post_key = [] self.return_to = 'https://www.pixiv.net/' # 存放图片路径 self.load_path = 'F:\work\picture' self.ip_list = [] self.json_data = "" def login(self): # se.headers = self.headers # r = se.get(self.login_url,params=self.params) # pattern = re.compile(r'name="post_key"value="(.*?)">') # result = pattern.findall(r.text) # self.post_key = result[0] # 构造请求体 post_key_html = se.get(self.base_url,headers= self.headers).text post_key_soup = BeautifulSoup(post_key_html,'lxml') self.post_key = post_key_soup.find('input')['value'] data = { 'pixiv_id': self.pixiv_id, 'password': self.password, 'post_key': self.post_key, 'return_to': self.return_to } q = se.post(self.login_url, data=data, headers=self.headers) result = se.get(self.main_url) # print(q.text) # print(result.text) def get_proxy(self): html = requests.get("http://www.kuaidaili.com/free/") # bsObj=BeautifulSoup(html,"html.parser",from_encoding="iso-8859-1") bsObj = BeautifulSoup(html.text, 'html.parser') ip_info_ip = bsObj.findAll("td", {"data-title": "IP"}) ip_info_port = bsObj.findAll("td", {"data-title": "PORT"}) # print(ip_info_ip) i = 0 for ip_info in ip_info_ip: ip = str(ip_info_ip[i].text) + ':' + str(ip_info_port[i].text) i = i + 1 ip_replace = re.sub('\n','',ip) self.ip_list.append(ip_replace.strip()) # print(self.ip_list) # html = requests.get("http://www.kuaidaili.com/free/") # # bsObj=BeautifulSoup(html,"html.parser",from_encoding="iso-8859-1") # bsObj = BeautifulSoup(html.text,'lxml') # ListTable = bsObj.find_all("table",class_="list") # res_tr = r'(.*?) ' # m_tr = re.findall(res_tr, html.text, re.S|re.M) # res_td_ip = r'(.*?) ' # res_td_port = r'(.*?) ' # # for ip_list_enable in m_tr: # port = re.findall(res_td_port,ip_list_enable,re.S|re.M) # # ip_list_enable =ip_address+':'+port # ip_address = re.findall(res_td_ip, ip_list_enable, re.S | re.M) # # post_temp = re.sub('\n','',ip_list_enable) # # self.ip_list.append(post_temp.strip()) # print(ip_address) # i=0 # for ip in self.ip_list_temp: # ip = ip_list_temp[i].contents # i = i + 1 # self.ip_list.append(ip) # print(ip) # ip_list_temp = re.findall(r'(.*?) ',bsObj.text) # for ip in ip_list_temp: # i = re.sub('\n','',ip) # self.ip_list.append(i.strip()) # print(i.strip()) def get_html(self, url, timeout,proxy=None, num_entries=5): if proxy is None: try: return se.get(url,headers=self.headers,num_entries=5,timeout=timeout) except: if num_entries > 0: print('获取网页出错,5秒后将会重新倒数第',num_entries,'次') time.sleep(5) return self.get_html(url,timeout,num_entries=num_entries-1) else: print('开始使用代理') time.sleep(5) ip = ''.join(str(random.choice(self.ip_list))).strip() print(random.choice(self.ip_list)) now_proxy = {'http':ip} return self.get_html(url,timeout,proxy=now_proxy) else: try: return se.get(url,headers =self.headers,proxy=proxy,timeout=timeout) except: if num_entries > 0: print('正在更换代理,5秒后重新获取第',num_entries,'次') time.sleep(5) ip = ''.join(str(random.choice(self.ip_list))).strip() now_proxy = {'http': ip} return self.get_html(url, timeout, proxy=now_proxy,num_entries=num_entries-1) else: print('使用代理失败') return self.get_hmtl(url.timeout) def mkdir(self,path): path = path.strip() is_exist =os.path.exists(os.path.join(self.load_path,path)) if not is_exist: print('创建一个名字为 '+path+' 的文件夹') os.makedirs(os.path.join(self.load_path,path)) os.chdir(os.path.join(self.load_path,path)) return True else: print('名字为 '+path+' 的文件夹已经存在') os.chdir(os.path.join(self.load_path,path)) return False def get_img(self,html,page_num): li_soup =BeautifulSoup(html,'html5lib') li_list = li_soup.find_all('li',attrs={'class','image-item'}) for li in li_list: href = li.find('a')['href'] # print(href) jump_to_url =self.main_url +href jump_to_html = se.get(jump_to_url).text img_soup =BeautifulSoup(jump_to_html,'html5lib') img_info =img_soup.find('div',{'class':'works_display'})\ .find('div',attrs={'class':'_layout-thumbnail'}) # print(img_info) if img_info is None: print("图片未找到") continue # else: # print(jump_to_url) # print(img_info) self.download_img(img_info,jump_to_url,page_num) def download_img(self,img_info,href,page_num): title = img_info.find('img')['alt'] src = img_info.find('img')['src'] src_headers = self.headers src_headers['Referer'] = href try: html = requests.get(src,headers=src_headers) img = html.content except: print('爬取图片失败') return False title = title.replace('?', '_').replace('/', '_').replace('\\', '_').replace('*', '_').replace('|', '_').\ replace('>', '_').replace('<', '_').replace(':', '_').replace('"', '_').strip() # 去掉那些不能在文件名里面的.记得加上strip()去掉换行 if os.path.exists(os.path.join(self.load_path,str(page_num),title+'.jpg')): for i in range(1,100): if not os.path.exists(os.path.join(self.load_path,str(page_num),title+str(i)+'.jpg')): title = title+str(i) break; print('正在保存名字为: '+title+' 的图片') with open(title+'.jpg','ab') as f: f.write(img) print('保存该图片完毕') def work(self): self.login() for page_num in range(1,10): path = str(page_num) self.mkdir(path) # now_html = self.get_html(self.target_url+str(page_num),3) now_html = self.target_url+"&p="+str(page_num) print(now_html) self.get_img(se.get(now_html).text,9) print('第{page}被保存完毕',format(page_num)) time.sleep(2) if __name__ == '__main__': pixiv = Pixiv() pixiv.work() # pixiv.get_proxy() # pixiv.get_html(pixiv.ip_list,5) # pixiv.get_html(pixiv.target_url,5) # pixiv.get_proxy()你可能感兴趣的:(Python 爬虫学习(5)Go!Go!Crawl Pixiv)