第一章 Spring之旅
[TOC]
前言
在诞生之初,创建spring的主要目的就是用来替代更加基重量级的企业级Java技术,尤其是EJB,相对于EJB,Spring提供了更加轻量级和简单的编程模型。
为降低java开发的复杂性,spring采取的四种策略
- 基于POJO的轻量级和最小侵入性编程
- 通过依赖注入和面向接口实现松耦合
- 基于切面和管理进行声明式编程
- 通过切面和模板减少样板式代码
什么是最小侵入性编程?
一些框架要求继承他们提供的类或现他们的接口导致应用和框架绑死,这是侵入性编程(PS : Spring Data好像就是这么干的 XD)。而具有最小侵入性编程的框架不会强迫这些,最坏的情况是需要使用注解。
public class HelloWorld{
public void sayHello(){
System.out.println("Hello World!");
}
}
这是一个非常简单的Java类(POJO),Spring赋予POJO魔力的方式之一就是通过DI(依赖注入)来装配他们,帮助应用对象之间保持低耦合。
一个简单的勇者骑士类
BraveKnight.class
public class BraveKnight implements Knight {
//拯救少女请求
private RescueDamselQuest quest;
public BraveKnight(){
this.quest = new RescueDamselQuest();
}
@Override
public void embarkOnQuest() {
quest.embark();
}
}
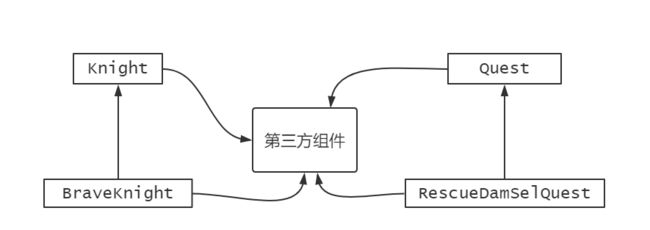
BraveKnight和RescueDamselQuest紧密的耦合在一起。
耦合具有两面性,一方面,高耦合度代码难以复用、难以测试、难以理解,当修复一个bug时,将会出现一个或更多bug。另一方面,一定程度的耦合度是必须的 —— 完全没有耦合的代码什么也做不了。
对象的依赖关系将由系统中负责协调对象的第三方组件在创建对象的时候进行设定,对象无需自行创建或管理他们的依赖关系。
"灵活"的勇敢骑士:构造器注入
BraveKnight.class
public class BraveKnight implements Knight {
private Quest quest;
// 构造器注入
public BraveKnight(Quest quest){
this.quest = quest;
}
@Override
public void embarkOnQuest() {
quest.embark();
}
}
BraveKnight 没有自行创建探险任务,而是在构造的时候把Quest作为构造器参数传入,这是依赖注入的方式之一:构造器注入
下面写一个新的Quest实现:
SlayDragonQuest.class
public class SlayDragonQuest implements Quest {
private PrintStream printStream;
public SlayDragonQuest(PrintStream printStream){
this.printStream = printStream;
}
@Override
public void embark() {
printStream.println("勇士.请和恶龙争斗吧!");
}
}
构建应用组件之间的协作的行为通常称为装配。Spring有多种装配bean的方式,采用XML是很常见的一种装配方式。
构造器注入:基于XML进行装配
knights.xml
其中,BraveKnight . SlayDragonQuest . RescueDamselQuest 被声明为Spring中的bean。就BraveKnight来讲,它在构造时传入了对SlayDragonQuest的引用,将其作为构造器参数。同时,SlayDragonQuest bean 的声明使用了spring表达式语言,将System.out(这是一个PrintStream)传入到了SlayDragonQuest的构造器中。
加载XML文件:
public class KnightMain {
public static void main(String []args){
// 通过xml的方式 加载spring上下文
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("com/springinaction/knights.xml");
// 获取 knight bean
Knight knight = context.getBean(Knight.class);
knight.embarkOnQuest();
context.close();
}
}
Spring通过应用上下文(Application Context)装配bean的定义并把它们组装起来,Spring应用上下文全权负责对象的创建和组装,Spring自带了多种应用上下文的实现,它们之间主要的区别仅仅在于如何加载配置
KnightMain.class过程:
- 基于knights.xml创建Spring应用上下文
- 调用应用上下文获取一个ID为knight的bean
- 简单调用
embarkOnQuest()方法执行探险任务
构造器注入:基于Java文件
Spring还支持基于Java的配置:
KnightConfig.class
@Configuration
public class KnightConfig {
@Bean
public Knight braveKnight(){
return new BraveKnight(rescueDamselQuest());
}
@Bean
public Quest rescueDamselQuest(){
return new RescueDamselQuest(System.out);
}
@Bean
public Quest slayDragonQuest(){
return new SlayDragonQuest(System.out);
}
}
KnightMain.class
public class KnightMain {
public static void main(String []args){
// 通过java配置的方式 加载spring上下文
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(KnightConfig.class);
// 第二种写法
// AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext("com.springinaction.config");
// 获取 knight bean
Knight knight = context.getBean(Knight.class);
knight.embarkOnQuest();
context.close();
}
}
基于切面进行声明式编程
DI(依赖注入)可以让互相协作的软件保持松散耦合,而面向切面编程(AOP)允许你把遍布应用各处的功能分离出来形成可重用的组件。
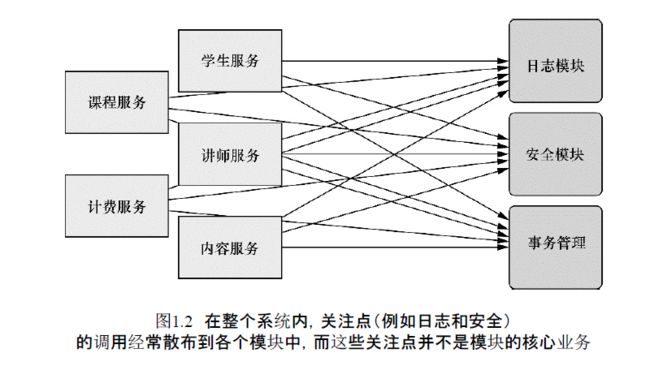
横切关注点:除了实现自身核心功能之外,一些组件还经常承担着额外的职责,诸如日志、事务管理和安全这样的系统服务经常融入到自身具有核心业务逻辑的组件中去,这些系统服务通常被称为横向关注点。
如果将这些关注点分散到多个组件中,代码将会带来双重复杂性:
- 实现系统关注点功能的代码将会分散到多个组件中去;即使把关注点抽象成独立的模块,其他模块仍然需要调用其方法。
- 组件会因为那些与自身核心业务无关的代码而变得混乱。例如一个向地址簿增加地址条目的方法不应该关注它是否是安全的或者是否支持事务。
AOP能够使服务模块化(比如说课程服务、学生服务...),并以声明的方式将横切关注点(例如日志模块、安全模块、事务管理模块...)应用到它们需要影响的组件中去。所造成的结果就是这些组件会具有更高的内聚性并且会更加关注自身的业务,完全不需要了解涉及系统服务
AOP应用
吟游诗人:Minstrel.class
public class Minstrel {
private PrintStream printStream;
public Minstrel(PrintStream printStream){
this.printStream = printStream;
}
/**
* 探险之前调用
*/
public void singBeforeQuest(){
printStream.println("探险之前调用.");
}
/**
* 探险之后调用
*/
public void singAfterQuest(){
printStream.println("探险之后调用.");
}
}
如果在BraveKnight.class中调用Minstrel的方法的话:
public void embarkOnQuest() {
minstrel.singBeforeQuest();
quest.embark();
minstrel.singAfterQuest();
}
显然有点不正确,Minstrel 吟游诗人应该做他分内的事情,而不需要minstrel的“提醒”。
我们需要做的是将Minstrel 声明为一个切面:
knights.xml
声明一个简单切面的方法 :
- 首先,把
Minstrel声明为一个bean - 在
- 在
Minstrel的bean,使其声明为一个切面 - 使用
expression属性来选择所应用的通知 - 使用
- 使用
输出如下:
探险之前调用.
勇士.请拯救你的少女!
11:17:15.056 [main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Returning cached instance of singleton bean 'minstrel'
探险之后调用.
使用模板消除样板式代码
为了实现简单的功能或者任务,不得不重复写一些重复冗长的代码,比如查询数据库。这就是样板式代码 :
package com.springinaction;
import java.sql.*;
public class BookMain {
public static void main(String []args){
Connection con = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
Book book = new Book();
try{
Class.forName("com.mysql.cj.jdbc.Driver");
con = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/graduate?serverTimezone=GMT&useSSL=true","root","root");
statement = con.prepareStatement("SELECT * FROM BOOK WHERE author = ?");
statement.setString(1,"施瓦辛格");
resultSet = statement.executeQuery();
while(resultSet.next()){
book.setId(resultSet.getLong("id"));
book.setDescription(resultSet.getString("description"));
book.setTitle(resultSet.getString("title"));
book.setIsbn(resultSet.getString("isbn"));
book.setAuthor(resultSet.getString("author"));
System.out.println(book);
}
}catch(Exception e){
e.printStackTrace();
if(resultSet!=null){
try {
resultSet.close();
} catch (SQLException e1) {
e1.printStackTrace();
}
}
if (statement != null){
try {
statement.close();
} catch (SQLException e1) {
e1.printStackTrace();
}
}
if (con != null){
try {
con.close();
} catch (SQLException e1) {
e1.printStackTrace();
}
}
}
}
}
如果说使用了Spring的JdbcTemplate的话,事情会变得比较简单 :
首先需要进行数据库的通用配置,假设文件名为applicationContext.xml
之后再创建BookJdbcTemplate类,操作底层数据库(增、删、改、查):
PS : 书上这一块儿写的比较简略,我稍微改了一些内容,并不是那么与时俱进的加入了JDK8的Lamada表达式(毕竟JDK11都快呼之欲出了)
@Repository
public class BookJdbcTemplate {
private final JdbcTemplate jdbcTemplate;
@Autowired
public BookJdbcTemplate(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public Book getBookById(Long id){
// sql查询
String sql = "SELECT * FROM BOOK WHERE ID = ?";
Book book = new Book();
RowMapper mapper = (rs , rowNum) -> {
book.setAuthor(rs.getString("author"));
book.setDescription(rs.getString("description"));
book.setId(rs.getLong("id"));
book.setIsbn(rs.getString("isbn"));
book.setTitle(rs.getString("title"));
return book;
};
return jdbcTemplate.queryForObject(sql , mapper , id);
}
}
之后就是主程序的编写了 :
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
JdbcTemplate jdbcTemplate = context.getBean(JdbcTemplate.class);
BookJdbcTemplate template = new BookJdbcTemplate(jdbcTemplate);
try {
Book book = template.getBookById(1L);
System.out.println(book);
}catch (EmptyResultDataAccessException ex){
System.out.println("未找到或找到多条数据.");
}
spring通过面向 POJO 编程、DI、切面和模板技术来简化 Java 开发中的复杂性。
容纳你的Bean:Spring容器
在基于Spring的应用中,你的应用对象生存与Spring容器中(container)中,Spring容器负责创建对象,装配它们,配置它们,并管理它们的整个生命周期从生存到死亡。
容器是Spring框架的核心,Spring容器使用DI管理构成应用的组件,它会创建相互协作的组件之间的关联。
Spring的容器并不是一个,Spring自带了多个容器实现,可以归为两个不同的类型:bean工厂和应用上下文。
bean工厂是最简单的容器,提供基本的依赖注入支持。应用上下文基于BeanFactory构建,并提供应用框架级别的服务,例如从属性文件解析文本以及发布应用事件给感兴趣的事件监听者。
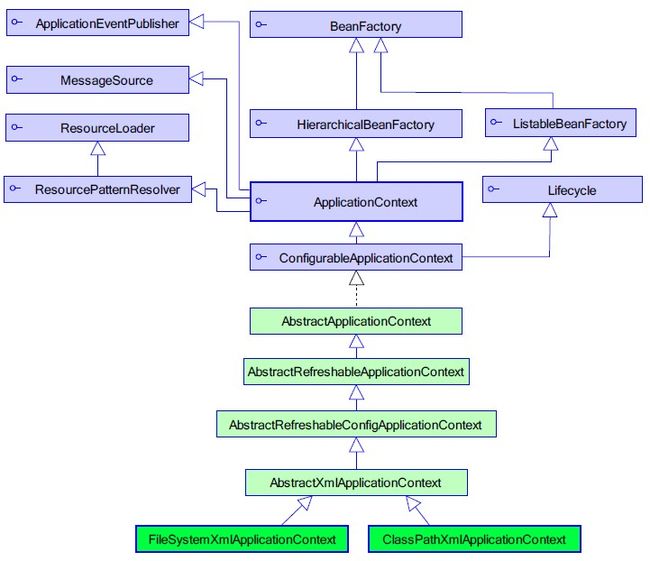
应用上下文使用的要更多更频繁一些。
使用应用上下文
-
AnnotationConfigApplicationContext: 从一个或多个基于Java的配置类中加载Spring应用上下文。 -
AnnotationConfigWebApplicationContext:从一个或多个基于Java配置类中加载Spring web应用上下文。 -
ClassPathXmlApplicationContext:从classpath路径下的一个或多个XML配置文件中加载上下文定义,把应用上下文的定义文件作为类资源。 -
FileSystemXmlApplicationContext:从文件系统下的一个或多个XML配置文件中加载上下文定义。 -
XmlWebApplicationContext:从WEB应用下的一个或多个XML配置文件中加载上下文定义。
无论是从类中还是从文件系统中加载应用上下文都是类似的:
例如,下面是从类路径中加载:
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("com/springinaction/knights.xml");
下面是从文件系统中加载
FileSystemXmlApplicationContext context = new FileSystemXmlApplicationContext("c:/knights.xml");
下面是Java配置文件加载:
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(KnightConfig.class);
bean 的声明周期
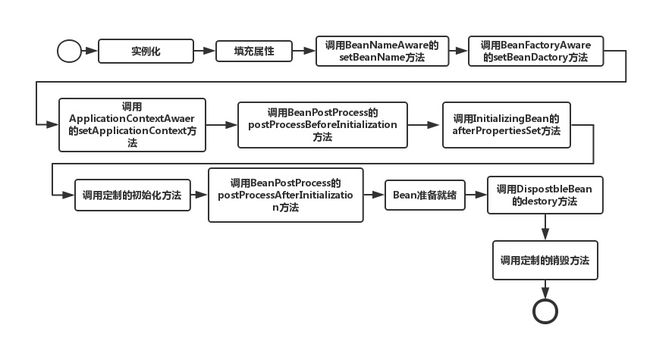
bean的声明周期经常会被问到,但是却又很难记忆 (建议把接下来的打印下来每天记忆):
作者:MOBIN-F
链接:https://www.zhihu.com/question/38597960/answer/77600561
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Spring对Bean进行实例化(相当于程序中的newXx())
Spring将值和Bean的引用注入进Bean对应的属性中
如果Bean实现了
BeanNameAware接口,Spring将Bean的ID传递给setBeanName()方法(实现BeanNameAware清主要是为了通过Bean的引用来获得Bean的ID,一般业务中是很少有用到Bean的ID的)如果Bean实现了
BeanFactoryAware接口,Spring将调用setBeanDactory(BeanFactory bf)方法并把BeanFactory容器实例作为参数传入。(实现BeanFactoryAware主要目的是为了获取Spring容器,如Bean通过Spring容器发布事件等)如果Bean实现了
ApplicationContextAware接口,Spring容器将调用setApplicationContext(ApplicationContext ctx)方法,把应用上下文作为参数传入。(作用与BeanFactory类似都是为了获取Spring容器,不同的是Spring容器在调用setApplicationContext方法时会把它自己作为setApplicationContext的参数传入,而Spring容器在调用setBeanDactory前需要程序员自己指定(注入)setBeanDactory里的参数BeanFactory )如果Bean实现了
BeanPostProcess接口,Spring将调用它们的postProcessBeforeInitialization(预初始化)方法(作用是在Bean实例创建成功后对进行增强处理,如对Bean进行修改,增加某个功能)如果Bean实现了
InitializingBean接口,Spring将调用它们的afterPropertiesSet方法,作用与在配置文件中对Bean使用init-method声明初始化的作用一样,都是在Bean的全部属性设置成功后执行的初始化方法。如果Bean实现了
BeanPostProcess接口,Spring将调用它们的postProcessAfterInitialization(后初始化)方法(作用与6的一样,只不过6是在Bean初始化前执行的,而这个是在Bean初始化后执行的,时机不同 )经过以上的工作后,Bean将一直驻留在应用上下文中给应用使用,直到应用上下文被销毁
如果Bean实现了
DispostbleBean接口,Spring将调用它的destory方法,作用与在配置文件中对Bean使用destory-method属性的作用一样,都是在Bean实例销毁前执行的方法。
Spring模块