学习使用Python爬取https://movie.douban.com/top250?start=0&filter= 网站的数据,并写入SQLite3数据库,然后使用pygal展示到网页上<新手学习>
网页展示.png
爬取数据写入数据库
import urllib.request
import sqlite3
from bs4 import BeautifulSoup
'''
https://movie.douban.com/top250?start=0&filter=
豆瓣电影TOP250信息爬取,并存入数据库
'''
class DouBanSpider(object):
def __init__(self):
self.page = 1
self.request_url = 'https://movie.douban.com/top250?start={url_page}&filter='
self.movies = {}
def get_page(self, go_page):
'''
:param go_page:
:return: '返回页面文本'
'''
url = self.request_url
page = str((go_page - 1) * 25)
try:
my_page = urllib.request.urlopen(url.format(url_page=page)).read().decode('utf-8')
except urllib.error.URLError as ueU:
print('发生错误:%s' % ueU)
return my_page
def find_info(self, my_page):
'''
:param my_page:
:return: {'电影名': ['分数', '星级', '评价人数', '名言']}
'''
soup = BeautifulSoup(my_page, 'html.parser')
# 是这个电影信息的模块,class为关键词,需加入后下横线
items = soup.find_all('div', class_="item")
people = '人评价'
star_num_dict = {
'rating5-t': '5',
'rating45-t': '4.5',
'rating4-t': '4',
'rating35-t': '3.5',
'rating3-t': '3',
'rating25-t': '2.5',
'rating2-t': '2',
'rating15-t': '1.5',
'rating1-t': '1',
'rating05-t': '0.5',
}
# movies = {}
for item in items:
# 创建空列表,列表内容为电影相关的信息,每经过一个循环就清空,字典的数据加入到字典,字典键为电影名,值为列表
tmp_list = []
# 排名
ranking_find = item.find('em', {'class': ''})
ranking = ranking_find.string
# 标题
title_find = item.find('span', {'class': 'title'})
title = title_find.string
star = item.find('div', {"class": "star"})
for child in star:
# 评分
score_find = item.find('span', {"class": "rating_num"})
score = score_find.string
# print(type(child))
#
#
# 评价人数
if people in str(child):
# print(child) # 819309人评价
evaluators_num = child.get_text().replace(people, '')
# 几星
if '-t' in str(child):
star_tmp = str(child).split('"')[1]
star_num = star_num_dict[star_tmp]
try:
# 名言,有些没有这一项,就把这个值赋“无”
inq_find = item.find('span', {"class": "inq"})
inq = inq_find.string
except AttributeError:
inq = '无'
# print(title)
# print(ranking)
# print(score, '分')
# print(star_num, '星')
# print(evaluators_num, '人评价')
# print(inq)
tmp_list.append(ranking)
tmp_list.append(score)
tmp_list.append(star_num)
tmp_list.append(evaluators_num)
tmp_list.append(inq)
self.movies[title] = tmp_list
# break
return self.movies
def start_spider(self):
'''
获取豆瓣电影TOP250所有电影信息
:return: self.movies
'''
while self.page <= 10:
print('正在获取第{page}页的内容!'.format(page=self.page))
my_page = self.get_page(self.page)
self.movies = dict(self.movies, **self.find_info(my_page)) # 两个字典相加
# 也可以使用self.movies = dict(self.movies.items(), self.find_info(my_page).items())
self.page += 1
return self.movies
def save_data(self):
'''
保存self.start_spider()返回的数据到数据库
:return: null
'''
sql_db = 'test.db'
try:
sql_conn = sqlite3.connect(sql_db)
except sqlite3.Error as e:
print('连接sqlite3数据库失败\n', e, ' ', e.args[0])
return
# 获取游标
sql_cursor = sql_conn.cursor()
# 如果表存在就删除
sql_del = 'drop table if exists movies_table;'
try:
sql_cursor.execute(sql_del)
except sqlite3.Error as sqlEdel:
print('删除数据库出错\n', sqlEdel)
return
sql_conn.commit()
# 创建表
sql_add = '''create table movies_table(
name TEXT NOT NULL,
ranking INTEGER,
score REAL,
star_num REAL,
evaluators_num INTEGER,
inq TEXT
);'''
try:
sql_cursor.execute(sql_add)
except sqlite3.Error as sqlEadd:
print('创建表出错\n', sqlEadd)
return
sql_conn.commit()
# 添加数据
for k, v in self.start_spider().items():
# print(k, v[0])
name = k
ranking = v[0]
score = v[1]
star_num = v[2]
evaluators_num = v[3]
inq = v[4]
sql_insert = '''insert into movies_table(name, ranking, score, star_num, evaluators_num, inq)
values ("%s", "%s", "%s", "%s", "%s", "%s");''' % (name, ranking, score, star_num, evaluators_num, inq)
# sql_insert = 'insert into movies_table(name) values("ew");'
try:
print('正在将 {name} 数据写入数据库...'.format(name=name))
sql_cursor.execute(sql_insert)
except sqlite3.Error as sqlEins:
print('插入数据出错\n', sqlEins)
return
sql_conn.commit()
print('\n数据库写入完成!')
sql_conn.close()
if __name__ == '__main__':
douban = DouBanSpider()
# my_page = douban.get_page(1)
# print(my_page)
# print(douban.find_info(my_page))
douban.save_data()
# print(douban.start_spider())
从数据库中读取展示到网页
#coding=utf-8
import sqlite3
import pygal
from flask import Flask
import sys
'''
pip3 install pygal
pip3 install flask
'''
app = Flask(__name__)
def get_data():
'''
查询数据库
:return: 列表中的元组
'''
try:
conn = sqlite3.connect('test.db')
except Exception as e:
print(e)
sys.exit()
cursor = conn.cursor()
sql = 'select * from movies_table order by evaluators_num DESC LIMIT 20'
cursor.execute(sql)
alldata = cursor.fetchall()
# print(alldata)
cursor.close()
conn.close()
return alldata
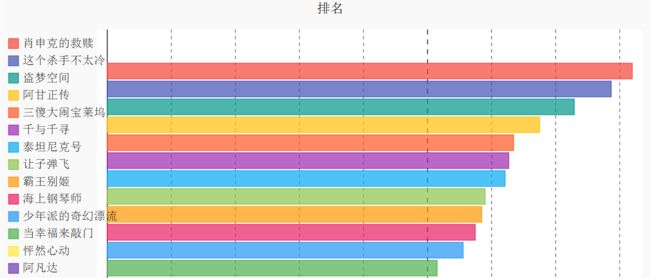
@app.route('/moviestop')
def show_graphs(data=get_data()):
title = '显示排名靠前的电影评论人数'
line_chart = pygal.HorizontalBar()
line_chart.title = '排名'
if data:
for rec in data:
# print(rec[0], rec[4])
line_chart.add(str(rec[0]), rec[4])
html = '''
%s
%s
''' % (title, line_chart.render().decode('utf-8'))
# line_chart.render()为'bytes'类型
return html
if __name__ == '__main__':
app.run(host='127.0.0.1')
备注:参考了http://www.jianshu.com/p/67b8aac4f93e 的文章,感谢。