浅谈数据挖掘(概论)
前言:学习资料的来源均出自,《图解机器学习》-杉山将,中国工信出版集团。《数据挖掘导论》-戴红,清华大学出版书,数据挖掘算法原理与实现。
笔者自述:不知道什么时候就开始有想学习数据挖掘这一块的知识,但是却从来都没有过开始。直到几天前,突然鬼使神差的去了图书馆,找了基本数据挖掘方面的书籍。当读完导论的时候,发现自己已经不能自给,深深的爱上了这个领域的东西。由于已经好久没接触计算机方面的知识了,现在又是一次挑战,我相信我可以的,希望广大走在奋斗道路上的朋友一同加油。我们扬帆起航,驶向远方。当然还有另外一个原因,那就是,因为本人今年大四,可能继续攻读研究生,但是不想把时间浪费在大四这一年无所事事的生活中,于是下定决心去找一份实习,虽然发了很多简历,但是基本上都是被拒了,所以坚定了我想好好学习一门技术的原因。
今天只是一个开始,数据挖掘这个领域的知识很多,以后我会不定时的发布自己的学习进程,与君共勉,我们一同加油,这么做的目的不是想怎么怎么样,只是想大家能很好的监督我。我们一起前进。我们都不是神的孩子,我们都是有梦的孩子。
今天我们来谈谈,数据挖掘的入门,数据挖掘这门技术很深奥,我们以后会慢慢给出。
一、数据挖掘的简单介绍
首先明确一个概念,数据挖掘不是简单的数据处理,他会用到数据库知识,机器学习知识,统计学知识等等。就好比你想追一个你不太熟悉的女孩子,你想知道,她喜欢什么样子的食物,喜欢什么类型的电影、音乐,什么样子的性格等等,那么你又不好意思直接询问,于是,你就打开她的朋友圈,微博,qq等一系列的社交工具。从这里边选取有用的信息进行使用,来判别她是什么类型的姑娘,平时喜欢做一些什么,所以学好数据挖掘,可以使我们能迅速了解一个姑娘,找到女朋友,结束这么多年的单身状态。所以这也是我学习数据挖掘的一个原因。
二、机器学习
机器学习(Machine Learning,ML)是模拟人类的学习方法来解决计算机获取知识问题的方法。我看了很多本关于机器学习的数据,发现里边对于机器学习的分类大体一致,我们这里采用《图解机器学习》里的分类,机器学习按照数据种类的不同,可以分为以下三类,监督学习,非监督学习,强化学习。
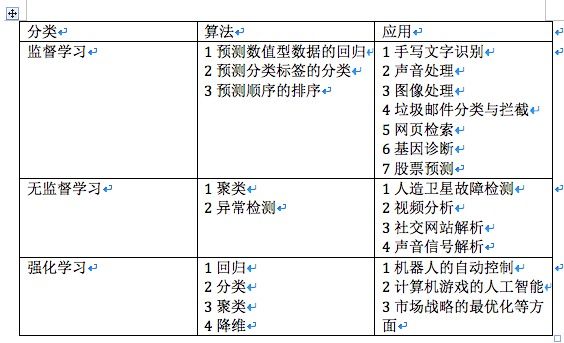
表格中的技术和应用我给自己定下的目标就是都进行训练。
接下来就是几种算法的形象化解释和理解
回归:把实函数在样本点附近加以近似的有监督的函数近似问题。
分类:指对于指定的模式进行识别的有监督的模式识别问题。
异常检测:输入样本点中包含异常数据的问题。
聚类:与分类问题相同,也是模式识别问题。
降维:从高纬度的数据中提取关键信息,将其转换为易于计算的低维度问题进而求解的方法。
学习模型而是分为以下三种,线性模型,核模型,层级模型。
三、数据挖掘的过程
数据挖掘的过程说的简单一点就是,从一堆数据中,通过一些算法,限定的条件,找到你需要的数据的过程,那么,数据来自什么地方,面对大量的数据它们存贮在什么地方,他们的数据类型是什么样子的,使用什么样的算法才是最准确的,才能得到我们想要的结果呢,又怎么进行数据模型的检测呢,那当所有的一些都完事了,这个模型又有什么应用呢?所有的一些,你是不是很迫不及待的想要去了解了呢?下面画一个流程示意图:
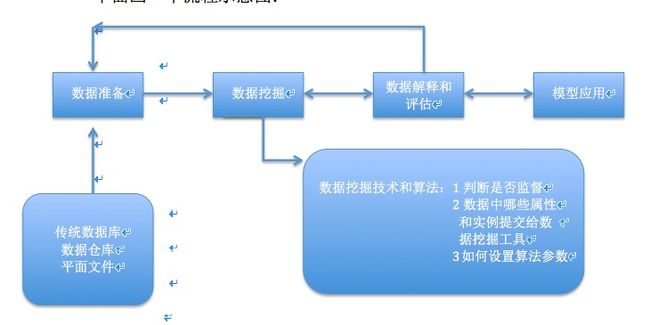
数据挖掘技术的选择至关重要:以下十点需参考,
1判断这个特定问题是否需要监督,是否需要进行关联分析。
2不同的数据挖掘技术对数据集中的属性之间的相关程度有不同的适应性。
3不同的数据挖掘技术对数据类型本身很敏感,明确输入属性是分类的,还是数值的,还是混合的,输出的类型是分类的还是数值的。
4针对数据本身,还应该了解数据的分布,比如统计技术则事先假设数据是正太分布的。这种假设是否与实际相等,是在采取统计技术前考虑。
5针对数据本身,还应该了解属性对于分类的预测能力。
6对于数据集中存在噪声数据和缺失数据的考虑。
7如果学习是有指导的,判断有一个输出属性还是多个输出属性。
8对所学的知识的解释能力往往也在选择某种技术建模时需要考虑到的内容。
9在选择挖掘技术时是否有时间上的考虑。
10选择机器学习技术还是统计技术的一些考虑。
综上所述,可以进行多选择不同的算法,来得出最好的数据结果。
四、数据挖掘的发展
数据挖掘的发展主要是分为四大类,其中包括:web挖掘,空间数据挖掘,流数据挖掘,数据挖掘与可视化技术,在这里边我认为最重要的技术就是流挖掘技术。之后的学习会有详细的学习笔记。
1 web数据挖掘
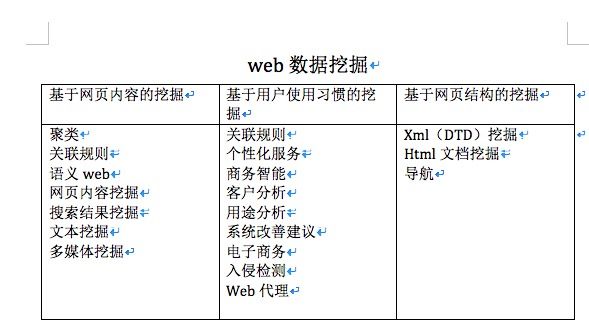
以上的具体应用会在后边的学习中给出。
我们了解了web在那几个方面进行数据挖掘,那么接下来就是我们挖掘的数据从何而来呢?
数据源
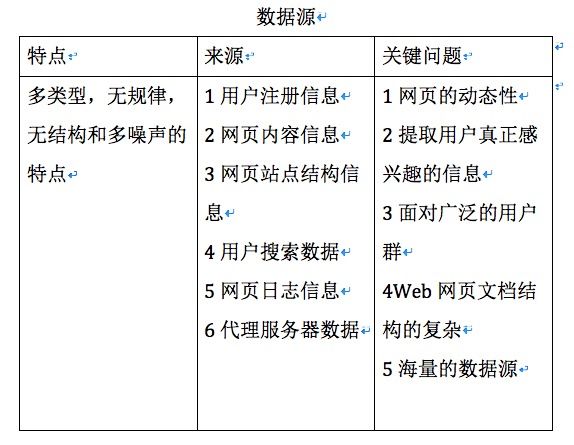
接下来我们说完了数据源,但是海量数据中,总有你想获得数据,那么多量的数据我们可以称为知识,那么知识本身是不是也应该有一定的分类呢?下面是对于知识的分类结构
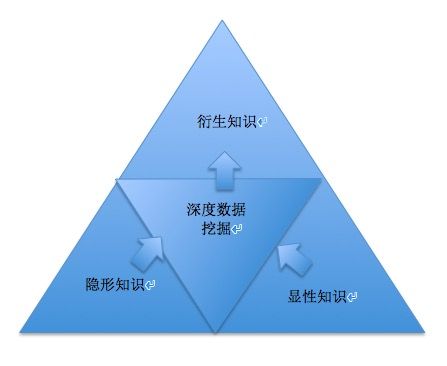
隐形知识:非结构化的形式,例如:留言,社区,日志,博文。
显性知识:结构化特性,例如:标签,评分和用户资料。
衍生知识:搜索,聚类和文本挖掘。
以上就是web数据挖掘的浅谈,深入的理解和例子,还要进一步学习。
2空间数据挖掘
空间数据是人们借以认识自然和改造自然的重要数据,空间数据库中包含空间数据和非空间数据
空间数据的特点:
(1)数据源十分丰富,数据量非常大,数据类型多,存取方法复杂。
(2)涉及领域十分广泛,凡与空间位置相关的数据,都可进行挖掘。
(3)挖掘方法和算法非常多,大多数算法比较复杂,难度大。
(4)知识的表达方式多样,对知识的理解和评判依赖人对客观世界的认知程度。
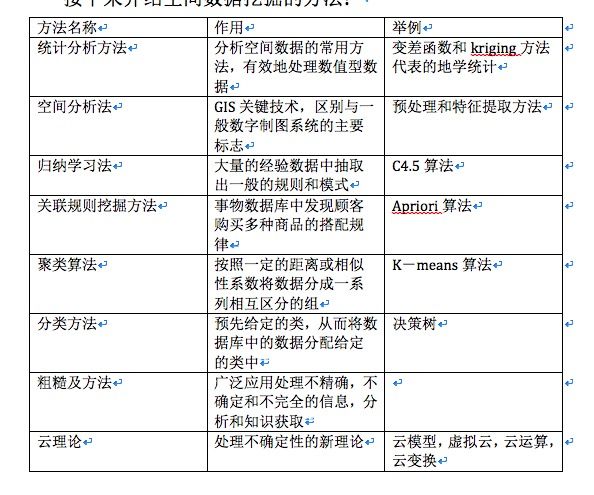
接下来介绍空间数据挖掘的方法:
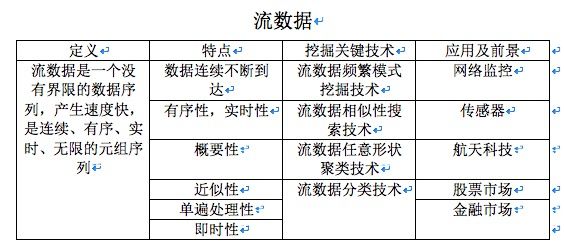
3流数据挖掘
传统的数据管理系统,只能用于处理永久的数据和进行瞬时的查询。
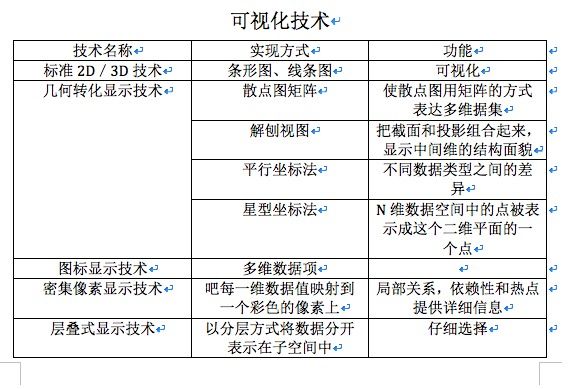
4数据挖掘与可视化技术
可视化将数据、程序、复杂系统的结构及动态行为用图形,图像,动画等可视化的形式表示。本质上:将抽象数据到可视结构的映射。
以上的知识内容只是浅谈数据挖掘,那么浅谈系列还会持续更新。读者有什么意见,可以直接给我留言,并且想跟我一起干掉数据挖掘这门技术的,我们可以一起讨论。