之前因为学习上的一些需要,也写了一两个爬虫,都是爬单页面的,或者只是简单的循环页面的。在因为论文的事情弄的焦头烂额的时候,忽然想学学scrapy换个头脑,然后就花了一天的时间看看scrapy的官方文档,算是对其有个大概的了解,但是当真正开始完全的写一个爬虫的时候还是感受到:买家秀和买家秀的区别了。
其实这个爬虫在网上都可以搜到很多:爬妹子图网站的所有图片。之前也有写过一个,但是只爬了第一页的图片。昨天想着:我要全部!!!废话不多说,先上代码。
# -*- coding: utf-8 -*-
import scrapy
from tupian.items import TupianItem
from scrapy.spiders import CrawlSpider
class MeizituSpider(CrawlSpider):
name = "meizitu"
allowed_domains = ["meizitu.com"]
start_urls = ['http://www.meizitu.com/a/list_1_1.html']
def parse(self, response):
items=[]
print(response.url)
infos = response.xpath("//ul[@class='wp-list clearfix']/li/div/div/a")
for info in infos:
item=TupianItem()
page_link = info.xpath('@href')[0].extract()
print(page_link)
item['list_url'] = response.url
item['page_link']= page_link
items.append(item)
for item in items:
yield scrapy.Request(url=item['page_link'],meta={'item_1': item},callback=self.parse_page)
for i in range(2,92):
all_pages = 'http://www.meizitu.com/a/list_1_%s.html' % i
yield scrapy.Request(url=all_pages, callback=self.parse)
def parse_page(self,response):
items = response.meta['item_1']
infos= response.xpath('//div[@class="postContent"]/div/p/img')
print(len(infos))
for info in infos:
item=TupianItem()
image_names =info.xpath('@alt')[0].extract()
images_urls= info.xpath('@src')[0].extract()
item['pic'] = image_names
item['images_urls'] = images_urls
item['list_url'] = items['list_url']
item['page_link'] = items['page_link']
print(item)
yield item
因为这次爬的是多层页面的数据,就涉及到数据的传递,我一直没有搞明白到底是怎么来传递的,自己琢磨了一天,抓狂的不要不要的。
嘴勤能问出金马驹的,我在上认识的一位老师@向右奔跑 所建的微信群里吼了一嗓子,霹雳一声震天响,来了一位程司机,带我起飞,带我嘿嘿嘿。为我特意写了一次这个爬虫,一直折腾到一点多。再次感谢感谢。
一点点分析:
import scrapy
from tupian.items import TupianItem
from scrapy.spiders import CrawlSpider
class MeizituSpider(CrawlSpider):
name = "meizitu"
allowed_domains = ["meizitu.com"] #这行的意义:不是这个域名类的网址都不爬。不然就要在parse的时候加上一个 don't filter=True
start_urls = ['http://www.meizitu.com/a/list_1_1.html'] #显而易见:起始页面
关键的时刻来了:多层页面怎么传递数据?
首先要理清思路:

在我们要解析的第一页里,有30个如箭头所示的子链接,每一个子链接下面又有7-8张这样的图片,这才是我们想要的。要怎么把弄出来?
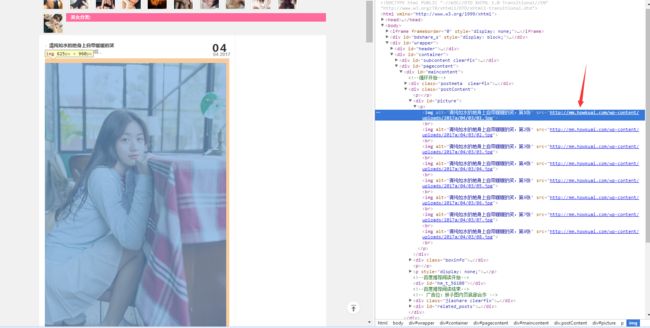
我们先理清楚:
(1)http://www.meizitu.com/a/list_1_1.html 这样的页面总共有92个
(2)每个上面的网址又包含30个的子链接 (最后一页不满30个,无所谓)
(3)每个子链接下面又有8张我们想要的图片
所以总数就是总数就是: 92308
首先:我们把每个页面下的30个链接给解析出来
def parse(self, response):
items=[] #首先实例化一个空列表用来传递数据
print(response.url) # 看一下我们解析其实网页出来的数据
infos = response.xpath("//ul[@class='wp-list clearfix']/li/div/div/a") #找出子链接的总节点,返回的是一个列表
for info in infos:#对列表进行循环
item=TupianItem()
page_link = info.xpath('@href')[0].extract() #取出子链接
print(page_link)
item['list_url'] = response.url # 这一个要不要都可以,只是为了显示出逻辑关系
item['page_link']= page_link #将子链接的值添加到item对应的字典里
items.append(item) #最后将所有的子链接的网址添加到最开始创建的快递盒子里
for item in items:
yield scrapy.Request(url=item['page_link'],meta={'item_1': item},callback=self.parse_page) # 现在来拆开快递, 调用self.parse_page函数来解析出每个子链接里面的8张图片,注意子链接是“page_link"。
重点是数据怎么传递的,为了这点,我花了一天的时间还没明白。
meta是一个内置的参数,类型是字典,meta={'item_1': item} 这个的意思就是创建以‘item_1’为key,以item为value的字典。因为是在循环里,所以每次赋值一个item的时候,就调用一次具体解析出8张图片的函数。因为我们的items有两个key,我们要的是item['page_link']这个。
这步想明白就简单了,因为总共有92个网页,通过观察有以下的变化模式:
for i in range(2,92):
all_pages = 'http://www.meizitu.com/a/list_1_%s.html' % i
yield scrapy.Request(url=all_pages, callback=self.parse)
最后一步就是构造解析8张图片的函数了
def parse_page(self,response):
items = response.meta['item_1']# 我对这句的理解是,跟上面的函数一样,只不过这次的起始页面换成了meta里的item
infos= response.xpath('//div[@class="postContent"]/div/p/img') #同样,解析出每个图片和名字的节点
print(len(infos))
for info in infos:
item=TupianItem()
image_names =info.xpath('@alt')[0].extract()#取出标题
images_urls= info.xpath('@src')[0].extract()#取出图片
item['pic'] = image_names #实例化
item['images_urls'] = images_urls #实例化
item['list_url'] = items['list_url'] #实例化
item['page_link'] = items['page_link'] #实例化
print(item)
yield item
pipline
import pymysql #数据库我不懂,照着网上的教程写了一下。这里吹不出来 ~~。。~~
def dbHandle():
conn = pymysql.connect(
host = "localhost",
user = "名字",
passwd = "密码",
charset = "utf8",
use_unicode = False
)
return conn
class TupianPipeline(object):
def process_item(self, item, spider):
dbObject = dbHandle()
cursor = dbObject.cursor()
sql = "insert into meizitu.t_meizitu(list_url,page_link,images_urls,pic) value (%s,%s,%s,%s)"
try:
cursor.execute(sql, (item['list_url'], item['page_link'], item['images_urls'], item['pic']))
cursor.connection.commit()
except BaseException as e:
print("错误在这里>>>>", e, "<<<<<<错误在这里")
dbObject.rollback()
return item
item
import scrapy
class TupianItem(scrapy.Item):
images_urls = scrapy.Field()
pic = scrapy.Field()
image = scrapy.Field()
page_link = scrapy.Field()
list_url = scrapy.Field()
跟单页面的爬虫相比,最大的不同就是在数据传递的方面,要想清楚,你要传什么参数给下一个解析函数。传递的方法其实已经固定:定义一个空列表,将所要传递的内容当成字典传递下去,而在下一个解析函数里,首先就是解析从上个函数传递下来的内容。
感谢程老师,@Mr_Cxy