Java基础知识干货1传送门->http://www.jianshu.com/p/78fdfacf1868
内部类
-
常规内部类
 常规内部类的组成
常规内部类的组成
- 只有内部类可以声明为 private,常规类只可以被声明为 public和protected
- 内部类可以访问外部类私有域的成员变量
- 内部类不允许有静态方法和变量
- 静态内部类
- 静态内部类不允许访问外围类对象
- 静态内部类可以有静态方法和静态变量
- 声明在接口中的内部类自动成为static和public类
Java异常层次
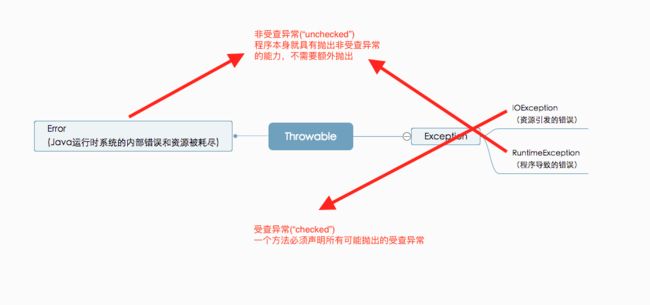
超类和子类的异常
- 如果在子类中覆盖了超类的一个方法,子类方法中声明的受查异常不能比超类中声明的异常更通用(应该抛出更具体的异常)
- 如果超类方法没有抛出任何受查异常,子类也不能抛出
建议同时捕获多个异常
catch(FileNotFoundException | UnkownHostException e) {
}
可以在catch字句中再抛出一个异常,这样做的目的是改变异常的类型
下列代码表明执行sevlet的代码可能不想知道发生错误的具体类型,但是希望明确知道servlet是否有问题。
try {
//access the database
}
catch(SQLException e) {
//这样做可以让用户抛出多个异常,而又不会丢失原始异常的细节
Throwable se = new ServletException("db error");
se.init(e);
throw se;
}
泛型的声明及调用
- 泛型类: 位于类名的后面
public class Pair {
...
}
- 泛型方法: 位于修饰符的后面,返回类型的前面
public static T getMiddle(T...a) {
...
}
在调用的泛型方法的时候,可以指定泛型具体参数,也可以不指定泛型具体参数.
- 在不指定泛型的情况下,泛型变量的类型为该方法的几种类型的同一个父类的最小级,直到Object.
//Integer和Float最小父类是Number
Number num = Test.getMiddle(1,1.2);
//Integer和String最下父类是Object
Object o = Test.getMiddle(1,"aaa");
- 在指定泛型的情况下,会发生编译错误
int a = Test.getMiddle(1,1.2);
泛型类型变量的限定
下例将T限制为实现了Comparable接口的类。
一个类型变量或通配符可以有多个限定
T extends Comparable & Serializable
public static T min(T[] a) {
...
}
运行时类型查询只适用于原始数据类型
由于类型擦出机制的存在,虚拟机中的对象总有一个特定的非泛型类型,因此所有的类型查询只产生原始类型
if(a instanceof Pair) //error
if(a instanceof) Pair) //error
getClass()方法总是返回原始类型
Pair a1 = ...;
Pair a2 = ...;
if(a1.getClass() == a2.getClass()) //true
不能创建参数化类型的数组
Pair[] table = new Pair[10]; //error
因为类型擦除机制使得table能够存放任意类型的对象,所以必须使用 ArrayList 对象。
泛型类中的静态方法和静态变量不可以使用泛型类所声明的泛型类型参数
public class Singleton {
private static T singleInstance; //error
public static T getSingleInstance() { //error
...
}
}
因为泛型类中的泛型参数的实例化是在定义对象的时候制定的,而静态变量和静态方法不需要对象来调用,所以是错误的。
注意擦除后的冲突
public class Pair {
public boolean equals(T ob) {
return first.equals(ob);
}
}
类型擦除后,类中存在两个 boolean equals(Object o) 方法,引起冲突,补救措施->rename
要想支持擦除的转化,就需要强行限制一个类或类型变量不能同时成为两个接口类型的子类,且这两个接口是同一接口的不同参数化
class Emploee implments Comparable {...}
class Manager extends Emploee implments Comparable {...} //error
队列(queue)
队尾添加元素,头部删除元素,并且可以查找队列中元素的个数
规则: 先进先出(FIFO)
实现方式: 循环数组,链表
两种实现方式的比较: 循环数组比链表更高效,但容量也有限,删除(或插入)中间元素时效率很差(因为需要一个一个进行移位操作)
public interface Queue {
void add(E e);
E remove();
int size();
}
Collection接口
在Java类库中,集合类的基本接口是Collection接口
public interface Collection {
boolean add(E e);
int size();
boolean isEmpty();
boolean contains(Object e);
Iterator iterator();
boolean remove(Object e);
boolean containsAll(Collection c);
boolean addAll(Collection c);
boolean removeAll(Collection c);
boolean retainAll(Collection c);
void clear();
boolean equals(Object o);
int hasCode();
}
迭代器
Iterator接口包含4个方法
public interface Iterator {
E next();
boolean hasNext();
//删除上次访问对象
void remove();
default void forEachRemaining(Consumer action);
}
通过反复调用next方法,可以逐个访问集合中的每个元素,如果到达了集合的末尾,next()方法将抛出 NoSuchElementException. 因此需在调next()方法之前调用hasNext();
如果想要查看集合中的所有元素,就请求一个迭代器
Collection collection = new ArrayList<>();
Iterator iterator = collection.iterator();
while(iterator.hasNext()) {
...
}
ListIterator可以实现双向遍历
集合框架中的接口
List是一个有序集合,元素会增加到容器的特定位置。
List的访问方式:
- 使用迭代器访问(必须顺序访问)
- 使用整数索引来访问
Java具体集合
链表

Vector: Vector之所以没在图中体现是因为这是Java集合中的遗留类,但是Vector所有方法都是同步的,我们平时使用单线程应用时,应该优先选择使用ArrayList.
ArrayList: 使用数组实现,从中间插入/删除元素很困难,但是按索引访问效率高。
LinkedList: 按索引访问效率很差,需要一个一个向下面遍历知道找到要访问的元素。
使用ListIterator向LinkedList中添加元素:
Java语言中的所有链表都是双向链表,链表是一个有序集合,每个对象的位置十分重要,由于迭代器是描述集合中位置的,只有通过迭代器对有序集合添加元素才更有意义,但Iterator接口中没有add(),其子接口ListIterator中包含add().
ListIterator iter = staff.listIterator();
//add()在迭代器位置之前添加一个元素
iter.next();
iter.add("tom");
如果多次调用add(),将依次把各元素添加至当前迭代器位置之前。
散列集
散列表不在意元素的顺序,但其可以实现快速的查找所需要的对象。
在Java中,散列表使用链表数组实现,要想要查找表中对象的位置,就要先计算他的散列码,然后与桶(bucket)的总数取余。

桶满的情况下,需要将新对象逐个与链表中的对象进行比较,查看这个对象是否已经存在(Java SE8中,桶满是会从链表变为平衡二叉树).
如果想控制散列表的运行性能,就要指定一个初始的桶数,通常将桶数设置在预计元素的75%~150%。
当然,并不是总能预先知道需要存的元素的个数,如果散列表太满,就需要进行再散列(rehashed),即创建一个桶数更多的表,并将所有元素插入到新表中,然后丢弃原来的表,何时丢弃由装填因子(load factor)决定,默认为0.75
树集
TreeSet类(使用红黑树实现)与散列集十分类似,不过它比散列集有所改进,它是一个有序集合,可以以任意的顺序将元素插入到集合中,在对集合进行遍历时,每个值将自动的按照排序后的顺序出现。
队列
双端队列: Java SE6引入了Deque接口,并由ArrayDeque和LinkedList类实现,这两个类都提供双端队列,双端队列即可以在头部和尾部同时添加或删除元素。
优先级队列(priority queue): 可以按照任意的顺序插入,却总是按照排序的顺序进行检索(使用堆(heap)来实现)
映射
Java类库为映射提供了两个通用的实现:HashMap和TreeMap,这两个类都实现了Map接口
- HashMap: 使用散列表实现,可以快速的查找键/值
- LinkedHashMap: 迭代遍历时,按插入次序遍历,迭代时也可以按照LRU(最近最少使用算法,长时间未使用的在前)次序迭代,迭代访问比HashMap快,因为它使用链表维护内部次序。
- WeakHashMap: 允许释放映射所指的对象
- ConcurrentHashMap: 线程安全的Map
- IdentityHashMap: 使用==代替equals()对键进行比较
线程安全的容器(简记为“喂,SHE”)
Vector: 效率低,但是比ArrayList多了个同步化机制,在web应用中特别是前台页面,往往效率优先,故不常使用。
Stack:
hashtable: 比hashMap多了个线程安全
enumeration:
枚举类型(不能被继承)
枚举是一组含有有限个具名值的集合,使用关键字enum声明枚举类型
enum shrubbery {GROUND,CRAWLING,HANGING}
除了不能继承一个enum外,基本上可以将enum看做一个常规的类,甚至可以有main()方法
public enum EnumTest{
WOLF("This is a wolf"),
TIGET("This is a tiger"),
SNAKE("This is a snake");
//必须在实例之后定义方法和变量
private String desc;
public String getDesc() {
return desc;
}
//构造函数声明为private
private EnumTest(String desc) {
this.desc = desc;
}
}
遍历
for(EnumTest item : EnumTest.values()) {
System.out.println(item + item.getDesc());
}
枚举中的values():
我们原本声明的枚举类Explore
enum Explore{
HERE,THERE
}
经过编译后变为
final class Explore extends java.lang.Enun{
public static final Explore HERE;
public static final Explore THERE;
//自动添加
public static final Explorep[] values();
//自动添加
public static final Explore valueOf(java.lang.String);
static{};
}
任务的定义
线程可以驱动任务,而任务的实现必须实现Runnable接口并编写run()方法。
任务的run()方法通常会有某种形式的循环,使得任务一直运行下去直到不再需要。
在run()方法中对静态方法Thread.yield()的调用是对线程调度器的一种建议,建议它切换至另一个任务执行。
Thread类
将Runnable对象转变为工作任务的传统方式是把它提交给一个Thread构造器。
public class BasicThread {
public static void main(String[] args) {
Thread t = new Thread(new LiftOff());
t.start();
}
}
使用Executor
Executor在客户端和任务执行之间提供了一个间接层,与客户端直接执行任务不同,这个中介对象将执行任务。Executor允许你管理异步任务的执行,而无需显式的管理线程的声明周期
ExecutorService exec = Executors.newCachedThreadPool();
exec.execute(new LiftOff());
//防止新任务被提交给exec
exec.shutdown();
- newCachedThreadPool(): 运行时为每个线程分派一个线程。
- newFixedThreadPool(): 一次性执行代价高昂的线程分配。
- newSingleThreadExecutor(): 一次只运行一个线程,多个需要排队.
从任务中产生返回值
Runnable是执行工作中的独立任务,不产生任何返回值,如果希望任务完成时能够返回一个值,那么可以实现Callable接口。
public TaskWithResult implements Callable {
private int id;
public TaskWithResult(int id) {
this.id = id;
}
public String call() {
return "result is " + id;
}
}
调用
ExecutorService exec = Executors.newCachedThreadPool();
ArrayList> array = new ArrayList<>();
for(int i = 0;i < 5;i++) {
//必须通过submit()来调用,调用之后返回Future对象
array.add(exec.submit());
}
for(Future fu : array) {
//使用get()获取结果,获取结果前可以使用isDone()来检查是否完成
System.out.println(fu.get());
}
休眠
try {
TimeUnit.MILLSECONDS.sleep(100);
} catch (InterruptedException e) {
System.err.println("interrupted");
}
优先级
public void run() {
//在run()方法开头设置优先级
Thread.currentThread().setPriority(10);
}
一般调整优先级时,只是用MAX_PRIORITY,NORM_PRIORITY,MIN_PRIORITY这三个级别.
后台线程(daemon)
后台线程不属于程序中不可或缺的一部分,当所有的非后台程序全部执行完毕时,程序也就终止了,同时会杀死进程中的所有后台线程,反过来说,只要有任何非后台线程在运行,程序就不会终止。
Thread t = new Thread(new LiftOff());
t.setDaemon(true);
t.start();
可以通过调用isDaemon()来判断一个线程是否是一个后台线程,如果是一个后台线程,那么它创建的所有后台线程也都是后台线程。
通过编写定制的ThreadFactory()可以定制由Executor创建的线程的属性.
public class DaemonThreadFactory implements ThreadFactory {
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
return t;
}
}
调用
ExecutorService exec = Exectors.newCachedThreadPool(new DaemonThreadFactory());
另外,后台线程在不执行finally语句的情况下就会终止run()方法。