HashMap作为开发中最常用的集合之一,在使用的时候我们是否思考过HashMap是怎样存储和查找数据从而保证时间复杂度在N(1)。我分享下对HashMap的一些认识,大家一同探讨,共同学习。
一、数据模型
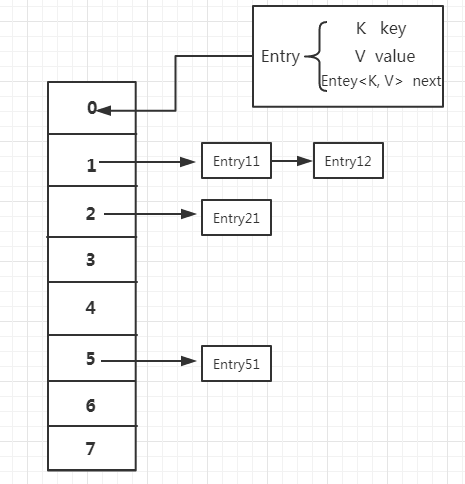
HashMap以key作为索引键,value作为目标值。基于hashing,我们通过使用get(key)来获取value值,通过put(key, value)来存储对象到HashMap中。当我们给put()方法传递键和值时,程序会先对键调用hashCode()方法,计算出的值用于找到bucket位置来储存Entry对象。这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。一个Entry里面包含K key、V value和一个指向下一个Entry next。
二、冲突
由于HashMap的Entry是分散存储在一个数组当中,这个数组就是HashMap的主干,分散的原理是根据对key进行hashCode()方法来计算存储位置。但是这个数组的长度是固定的。当插入的Entry越来越多时,再完美的Hash函数也难免会出现index冲突的情况,也就是说两个Entry的key值经过hashCode()方法计算的值是相同的,或者根据hashCode值计算出的index是相同的。处理冲突的方式有多种,HashMap采用的是拉链法,也就是在利用链表来解决。如上图。
当两个Entry的key值经过hashCode()计算出相同的位置时,在HashMap的主干数组中存储的是一个链表,将所有相同位置的Entry存储在这个链表中。每一个Entry对象通过Next指针指向下一个Entry节点。当新put进来的Entry映射到冲突的数组位置时,插入到对应的链表即可,这个新Entry节点插入链表时,采用的是“头插法”,这个是因为HashMap的发明者认为,后插入的Entry被查找的可能性更大。
三、get、put原理
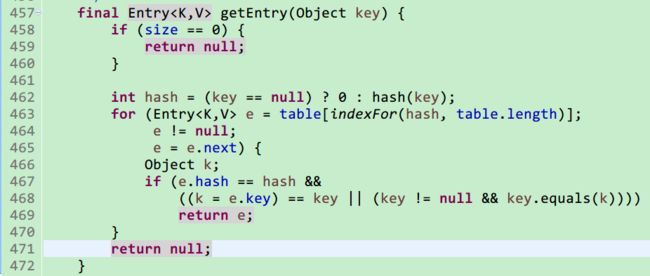
当调用HashMap的get方法时,首先会判断key是否为null,如果为null,则会返回HashMap数组中下表为0的Entry,如果存在则返回,不存在时返回Null,当key不为null时,会调用如下方法,步骤如下:
1.判断size是否为0
2.求key的hashCode值,然后根据hashCode值和当前HashMap的长度调用indexFor()求得数组下标,
3.如果同一个位置有多个Entry,逐个判断数组上的链表中是否包含该key值,会先判断key的hashCode值,然后会判断equals是否相等。这里需要明白一点,hashCode值相等的两个对象不一定是同一个对象,但是hashCode不相等的对象肯定不是同一个对象。
后续介绍indexFor()方法内部实现。
从这里也可以知道为什么将自定义类型作为HashMap的key时,需要实现其HashCode()和equals()的原因。
下图为put时的代码,一步步说明:

1.对于null值还是特殊处理,处理流程和getForNullKey大致相同,这里不做过多说明
2.计算key的HashCode值,计算key在数组中的下标
3.判断key是否存在当前HashMap中,如果存在,则更新用新值更新旧值,返回旧值
4.modCount++,此值在多线程环境下迭代输出时有用,本次不做说明
5.添加新的Entry
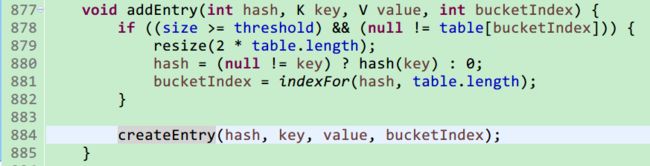
接着看addEntry方法内部流程:
1.在添加之前会判断HashMap的容量是否达到临界值,临界值threshold是根据负载因子(默认0.75,创建时自定义)和容量(初始默认长度16,可创建时自定义)算出来的,如果超过临界值需要自动扩充resize()
2.添加新Entry,createEntry()内部为添加Entry到数组下标为bucketIndex,添加完成后size++
四、HashMap长度和扩充
在使用的时候HashMap的长度便是put进的数量,但是HashMap是有一个默认长度的,也可以理解为当前最大容纳量,为什么说是当前最大容量?因为HashMap会根据默认长度和负载因子,达到特定使用长度时会自动扩充,这样便有一个疑问?自动扩充?那么初始的默认长度是多少?以及怎么扩充?扩充之后的长度是多少,怎么计算?但是前面说过在创建HashMap的时候可以指定长度,那么这又是怎么回事?
实际上指定的只是第一次自动扩充的临界值,默认的初始长度选取大于initialCapacity的最小的2的n次幂,如果没有指定的initialCapacity的话,那么会使用默认的,这时默认初始容量为
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
之所以是16,是因为为了服务于从key映射到index的Hash算法。在发生冲突时采用的链表在查找的时候是需要一个个遍历的,所以作为计算index的Hash算法必须使得key尽量均匀分布,且易于计算,因为作为底层的集合工具,必须要保证性能。
HashMap的indexFor()采用的是取模运算,不过是用了一种更高效的方式来取代%取模——位运算,一般的取模运算表达式:index = HashCode(key) % length,这个length是指当前的HashMap长度,而HashMap采用的位运算是:index = HashCode(key) & (length - 1),比如:
假定一个key经过HashCode计算结果为3029737,二进制为10 1110 0011 1010 1110 1001
设当前HashMap的长度是默认的16,length - 1是15,二进制为 1111
将上述两个值做与运算,10 1110 0011 1010 1110 1001 & 1111 = 1001 ,十进制是9,所以index=9
这个过程的结果相当于取模运算,但是效率却高于%取模。现在假设HashMap的默认初始长度是10,length - 1 = 9,二进制为1001,
10 1110 0011 1010 1110 1001 & 1001 = 1001, 十进制是9,和之前方法结果一样,但是要是key的HashCode值为10 1110 0011 1010 1110 1111呢?
10 1110 0011 1010 1110 1111 & 1001 = 1001
要是key的HashCode是10 1110 0011 1010 1110 1101呢?
10 1110 0011 1010 1110 1101 & 1001 = 1001
所以可以看出,当长度不是2的次幂的时候计算结果Index会发生更多的碰撞,这样便不符合Hash算法均匀分布的原则。所以采用长度为2的次幂,只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
前面在说put的时候说到了会首先判断是否达到扩种临界值,如果达到临界值会进行resize(),
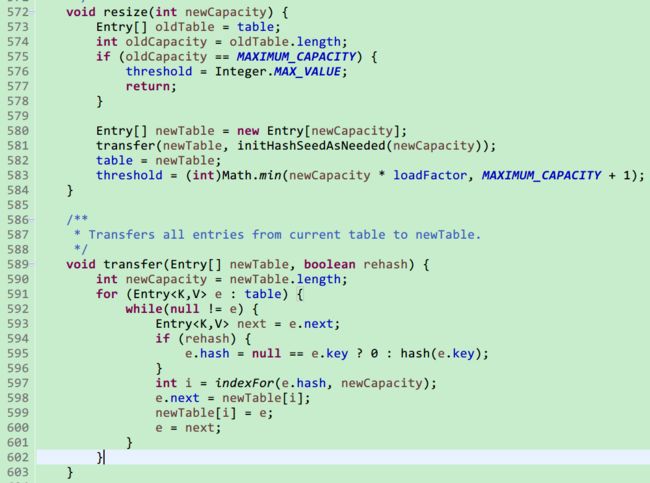
1.如果原来的容量已经达到HashMap最大值,那么调整临界值为最大值,返回
2.创建新的Entry[],将旧HashMap中的值转移到新的HashMap中,将当前的HashMap指向新的HashMap,
3.更新临界值
然后继续看transfer()方法,主要的操作就是遍历当前Entry[] 将所有bucket中的Entry根据新的长度计算下标,放入合适的位置,一步步说明:
1.遍历Entry[]数组,将bucket中的当前Entry e和下一个Entry next取出(如果没有下一个则是null,下次while循环会退出)
2.重新计算Entry e对应新数组的下标i
3.将next置为newTable[i]实际为null,等同于让当前Entry e和next断开连接
4.将当前Entry e放入newTable[i],将当前Entry e 指向下一个Entry next
5.如此循环。
前方高能预警:在转移Entry的时候,链表中的Entry顺序会翻转(如果恰好原来在一个bucket中的多个Entry又在同一个bucket,因为头插法)!!!!
五,并发下的HashMap
前面说过当添加的时候会首先判断是否达到临界值,如果达到了,需要进行扩充并且转移的reHash过程,下面来说下并发情况下有可能出现的情况。并发下对于读是没有影响的,但是如果写没有做并发处理会出现一些数据的脏写,对于HashMap会出现什么情况?
因为在reHash的过程中会将bucket中的Entry转移到新的Entry[]中,如果原本在同一个bucket中的Entry在新的Entry[]中又在同一个bucket中,首先一步步看,如果同时有两个线程一前一后检测到需要扩充,线程一执行到593行被挂起,但是线程二却完成了这个过程,这时bucket上的Entry[]已被转移并且反转,那么会出现这样的情况:
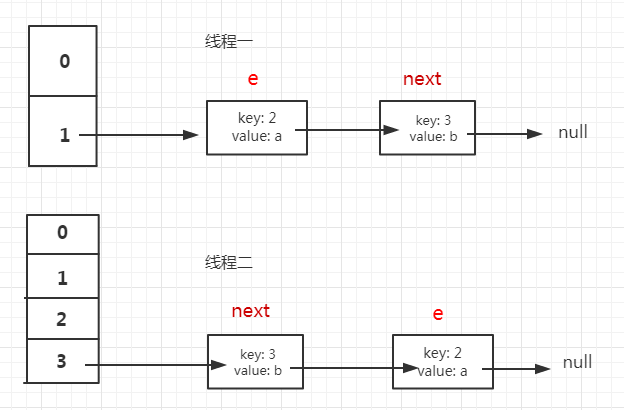
线程一此时e:指向key:2,next指向key: 3,而线程二已经完成了这个过程,使得链表的顺序反转,key:2 的next指向null,key:3的next指向key:2,线程一获得系统资源,继续执行,将e放到了新的Entry[]中,然后将e = next(next已取出),进行下一个Entry的转移,读取e为key:3,next为key:2,这样就又回到了之前已转移过的节点,至此,便形成了一个环形链表。
六,总结
HashMap作为最常用的基础数据结构,有着很多巧妙的设计,我们通过学习源码,可以更高效更安全的使用,也可以从中学习到一些更好的设计思想和方案。