启动 MongoDB 和 Robomongo 可视化界面。
新建爬虫项目
scrapy startproject mudao
在 scrapy.cfg 文件同级目录中新建一个 main.py, 内容如下:
#-*- coding:utf-8 -*-
from scrapy import cmdline
cmdline.execute("scrapy crawl mudao".split())
settings.py 中增加的额外配置如下:
ITEM_PIPELINES = {
'mudao.pipelines.MudaoPipeline': 300,
}
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = 27017
MONGODB_DBNAME = 'Daomubiji'
MONGODB_DOCNAME = 'Book'
这样当 spiders.py 中用到 mongodb 的一些配置时, 导入这个配置文件, 以 seetings['key'] 的形式访问那些配置。
items.py 设置如下:
from scrapy import Item, Field
class MudaoItem(Item):
bookName = Field()
bookTitle = Field()
chapterNum = Field()
chapterName = Field()
chapterURL = Field()
总共要提取网页中的 5 个字段, 所以需要 5 个类变量。
pipelines.py 中的设置如下:
from mudao.items import MudaoItem
from scrapy.conf import settings
import pymongo
class MudaoPipeline(object):
# 初始化
def __init__(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbName = settings['MONGODB_DBNAME']
client = pymongo.MongoClient()
db = client[dbName]
self.post = db[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
bookInfo = dict(item)
self.post.insert(bookInfo)
return item
初始化只进行一次, 它设置好数据库相关的操作。得到一个对 Daomubiji 数据库中文档名为 Book 的引用。之后, 在 process_item 方法中, 每当一个 item 传递进来, 就将这个 item 字典化, 然后执行 insert 插入操作, 最后返回这个 item。
spiders.py 如下:
import scrapy
from scrapy.spider import CrawlSpider
from scrapy.http import Request
from scrapy import Selector
from mudao.items import MudaoItem
class MudaoSpider(CrawlSpider):
name = "mudao"
start_urls = ['http://www.daomubiji.com/']
def parse(self, response):
selector = Selector(response)
# 先取大
table = selector.xpath('//table')
# 共 10 个 table, 有 10 本书
for each_table in table:
bookName = each_table.xpath('tr/td[@colspan="3"]/center/h2/text()').extract_first()
content = each_table.xpath('tr/td/a/text()').extract() # 一本书中所有章节的标题
urls = each_table.xpath('tr/td/a/@href').extract() # 一本书中所有章节的 url
for i in range(len(urls)):
item = MudaoItem()
item['bookName'] = bookName
item['chapterURL'] = urls[i]
try:
item['bookTitle'] = content[i].split(' ')[0]
item['chapterNum'] = content[i].split(' ')[1]
except Exception as e:
continue
try:
item['chapterName'] = content[i].split(' ')[2]
except Exception as e:
item['chapterName'] = content[i].split(' ')[1][-3:]
yield item
在 Pycharm 中运行 main.py, 抓取完成后在可视化工具中查看, 结果如下:
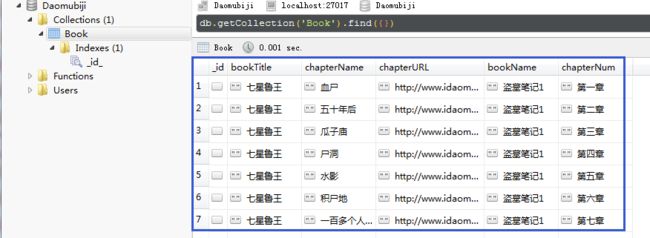
result
try ... except 是为了避免解析章节标题时, 有些章节标题未给出的问题。