环境准备:
1. java开发环境
2. jsoup.jar
通过Python进行数据爬取的教程很多,但是使用java做爬虫的教程很少今天我就使用java进行一次爬图
首先使用的工具是jsoup.jar,这是一个解析html文档的包
官方API:
https://jsoup.org/apidocs/

中文API:http://www.open-open.com/jsoup/
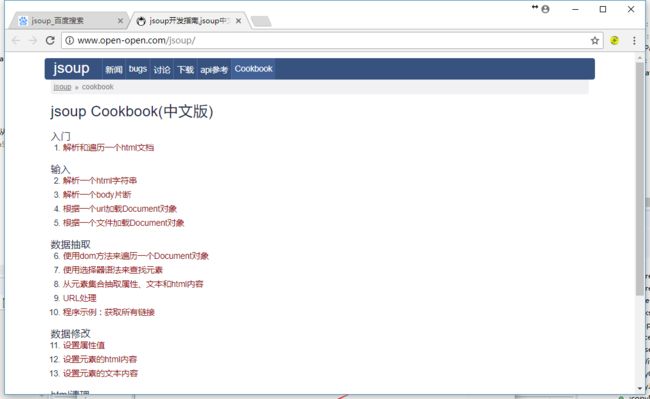
jar包网上很好下载,就不放下载链接了。
好了可以开始爬图了
首先我找了个图片分享网站
http://jandan.net(无任何恶意)
在这个网站的子板块 有个妹子图,基本上也是抓取的微博的链接,小网站带宽不够,爬的慢,同时你一个人吧带宽占了别人也没法儿访问,尽量别人给别人找麻烦,但是看到他的图片是微博的外链 ,这就是说我们只要获取页面的html就好,对带宽要求很低。
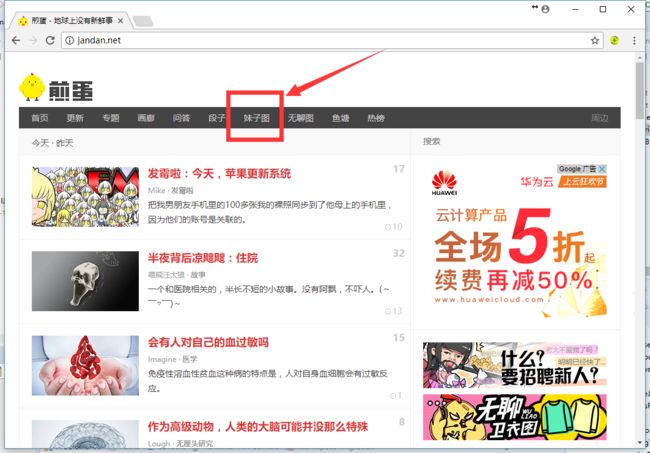
我决定就从这里入手了
点开板块:
诶诶,骚年,看这儿,眼睛看哪儿去了!==
首先看第一页网址
发现不了什么
但是翻下一页就发现了

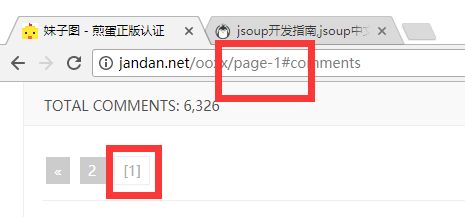
page - 254
这里的分页也显示是254页了

那么我们现在就找到规律了,page后面就是页码
我们写个1看看会不会跳到第一页
果然我们来到了第一页
那我们开始写代码
先来两个常量
static int num =100;//需要爬多少页
private static final String URL = "http://jandan.net/ooxx/page-";
写完是不是就发现啥思路也没有啊,所以现在就开始分析页面结构了
为什么要分析页面结构?
熟悉html的人应该知道,img标签里面的src就是图片的地址了,只要获取到图片的src就可以得到图片,比如 打开百度的页面,f12看看控制台,这个src就是图片的下载地址

下面开始分析html

html结构我就不说了,如上图
我们这次采用的是一级一级的搜索下去的方法
如上图,很清楚的看到每张图片是一个li,都装在ol里面学过css3选择器应该怎么选择:ol li
,从大到小是吧
我们先获取到这个html再说
//
public static List getdataByPage(int pageNow) throws IOException{
System.err.println(URL + pageNow);//打印输出每次的页码
Connection conn = Jsoup.connect(URL + pageNow)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:47.0) Gecko/20100101 Firefox/47.")
.timeout(5000)
.method(Connection.Method.GET);//模拟浏览器去访问
Document doc = conn.get();//获取document对象
Element body = doc.body();//获取body对象
List resultList = new ArrayList();//创建一个集合,存爬取到的图片链接
-------未完------
}
创建了个方法,返回的是个集合 ,getdata内容如下:
public class getdata {
private String url;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
Url存储的是爬取到的图片的链接,传入了个参数,那个就是页码,请无视那句
Conn里面其实是模拟浏览器,让对方识别出你的信息,传入url,返回的是window对象。
使用conn.get(),从conn获取到Document对象。
学过JavaScript的对Document应该不陌生,科普下
每个载入浏览器的 HTML 文档都会成为Document 对象。
Document 对象使我们可以从脚本中对 HTML 页面中的所有元素进行访问。
Document 对象是 Window 对象的一部分,可通过 window.document 属性对其进行访问
这样获取到了Document,那么我们可以继续向下缩小范围
Element body = doc.body();//获取body对象
这样我们吧Body从Document中取出来了。
body是个Element 类型的,这是什么,我也不知道,api是这样说的:
A HTML element consists of a tag name, attributes, and child nodes (including text nodes and other elements). From an Element, you can extract data, traverse the node graph, and manipulate the HTML.
翻译下就是
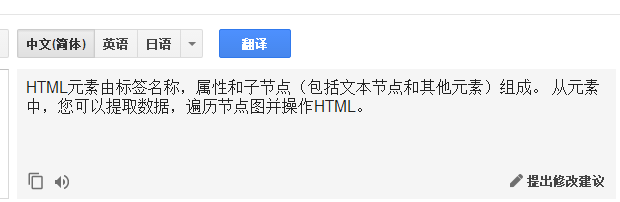
就这意思,就是我们可以从里面提取出节点。
看一眼网页源码,怎么继续向下缩小范围呢?
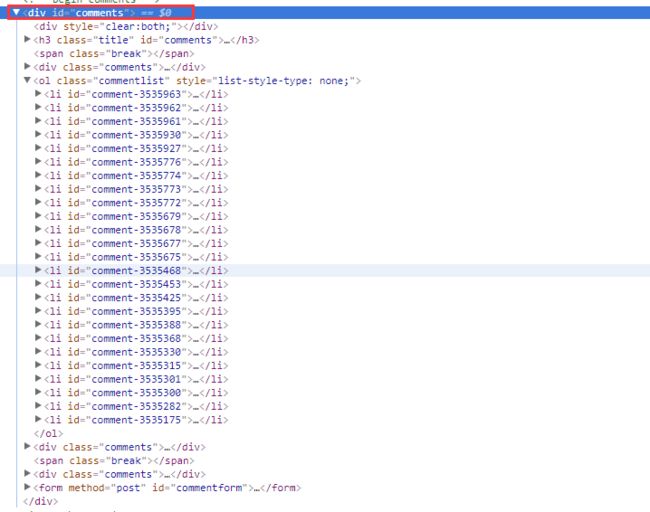
看这里有个div装着我们的内容,那么我们就向下深入吧。
Element articleListDiv = body.getElementById("comments");
获取到上图红框那个div对象。getElementById ,是不是很熟悉,对了就和js一样,哈哈,这下简单吧。
好了我们现在就剩上面的内容了,怎么继续下去呢。
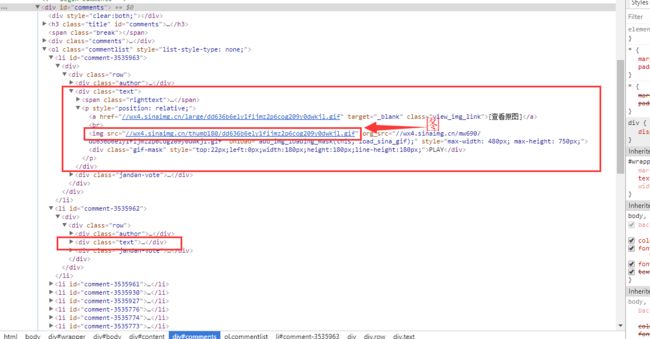
继续观察,我们发现每个li里面都有个class是text的div,text里面就是图了,我们还发现了一个查看原图的a标签,也在text里面,里面地址获取应该是高清大图,所以我们放弃img,转而投向a标签
Elements text = articleListDiv.getElementsByClass("text");

从上面我们获取到的div继续向下,但是这里有个问题,Element 能存一个对象,但是class不是唯一的,上面截图就有两个,咋办?一个对象是存不的,这时候就要Elements ,加个s就是复数了嘛,你可以理解是个数组,我也懒得看api了,感兴趣的自己去看吧。
总之Elements存储了多个对象。
继续向下,有了上面的经验,就直接点这里面有个查看原图的a标签,就是说,可以直接链接到大图。
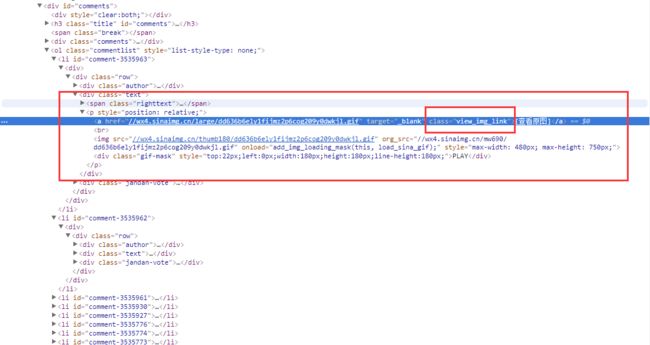
直接找到这个a标签,用class获取。
代码如下
Elements imd = articleListDiv.getElementsByClass("view_img_link");
我们现在思考下,现在是什么情况,我们获取到了一堆class叫 text 的div,然后我们又从这堆div里面获取了一堆class叫view_img_link的a标签,其实你从Elements 里面去获取任何数据都是要用Elements 接收的,因为原本就不止一个,获取出来也可能是多个。
接下来直接for遍历数组
for(int a = 0;a
说明:
他的链接这样,显然不是我们想要的
 image.png
image.png
是这样的 获取的是
//wx4.sinaimg.cn/large/dd636b6ely1fijmz2p6cog209y0dwkjl.gif
那么只能
String str2 = t.substring(2, t.length());字符串截取。
结果获取到的
wx4.sinaimg.cn/large/dd636b6ely1fijmz2p6cog209y0dwkjl.gif
地址就这样获取了,想获取多少页 你就写个其他类用for调用这个
类
获取到链接了我们要把图片存下来,由于存图片就是普通的io,就不讲解了
代码:
static int imageNumber = 0;
public void downloadPicture(ArrayList urlList,String ur) {
URL url = null;
for (String urlString : urlList) {
try {
url = new URL(urlString);
DataInputStream dataInputStream = new DataInputStream(url.openStream());
String a = urlString.substring(urlString.length()-3,urlString.length());
System.out.println("正在处理:"+(imageNumber+1) + "."+a);
imageNumber++;
String imageName = imageNumber + "."+a;
FileOutputStream fileOutputStream = new FileOutputStream(new File(ur+imageName));
byte[] buffer = new byte[102400];
int length;
while ((length = dataInputStream.read(buffer)) > 0) {
fileOutputStream.write(buffer, 0, length);
}
dataInputStream.close();
fileOutputStream.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
注释:
//ur是本地的路径,存到什么地方
//ArrayList是地址的集合
给大家看看我的运行效果吧!
 image.png
image.png
设定路径点击开始
获取所有html文件
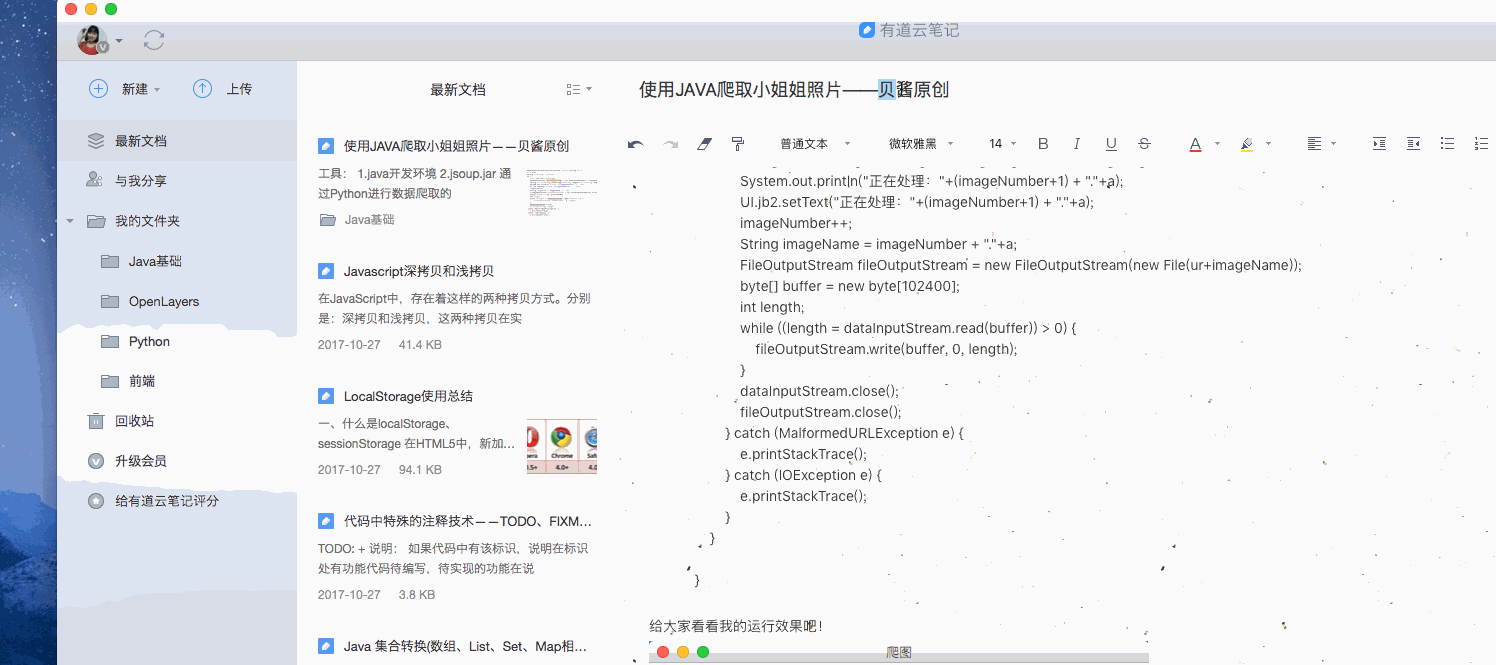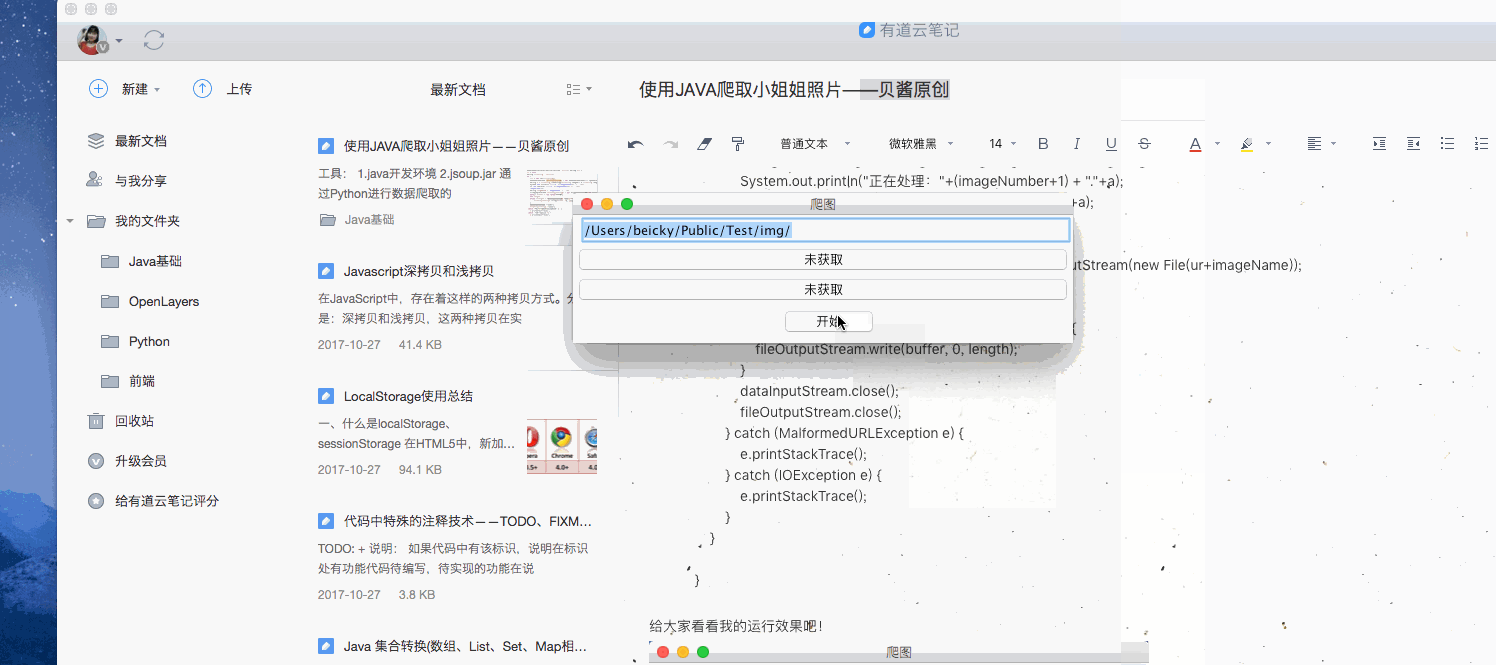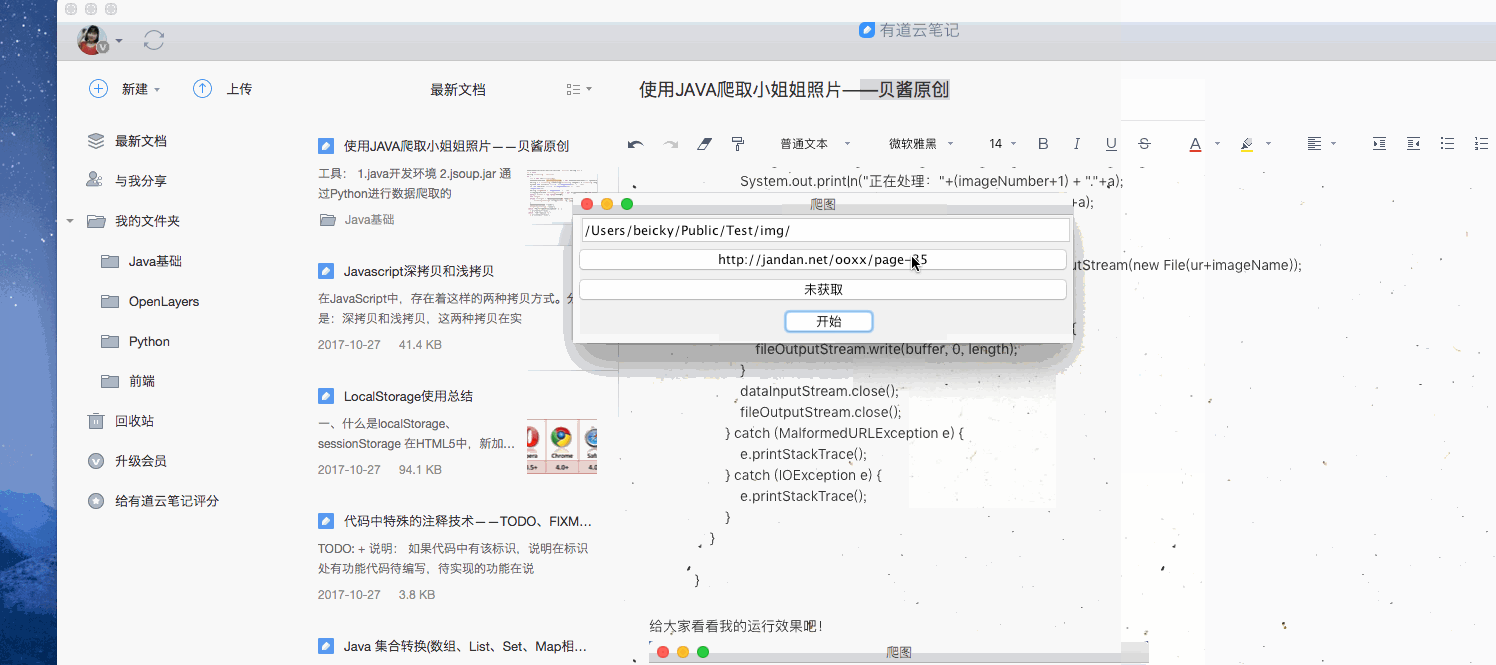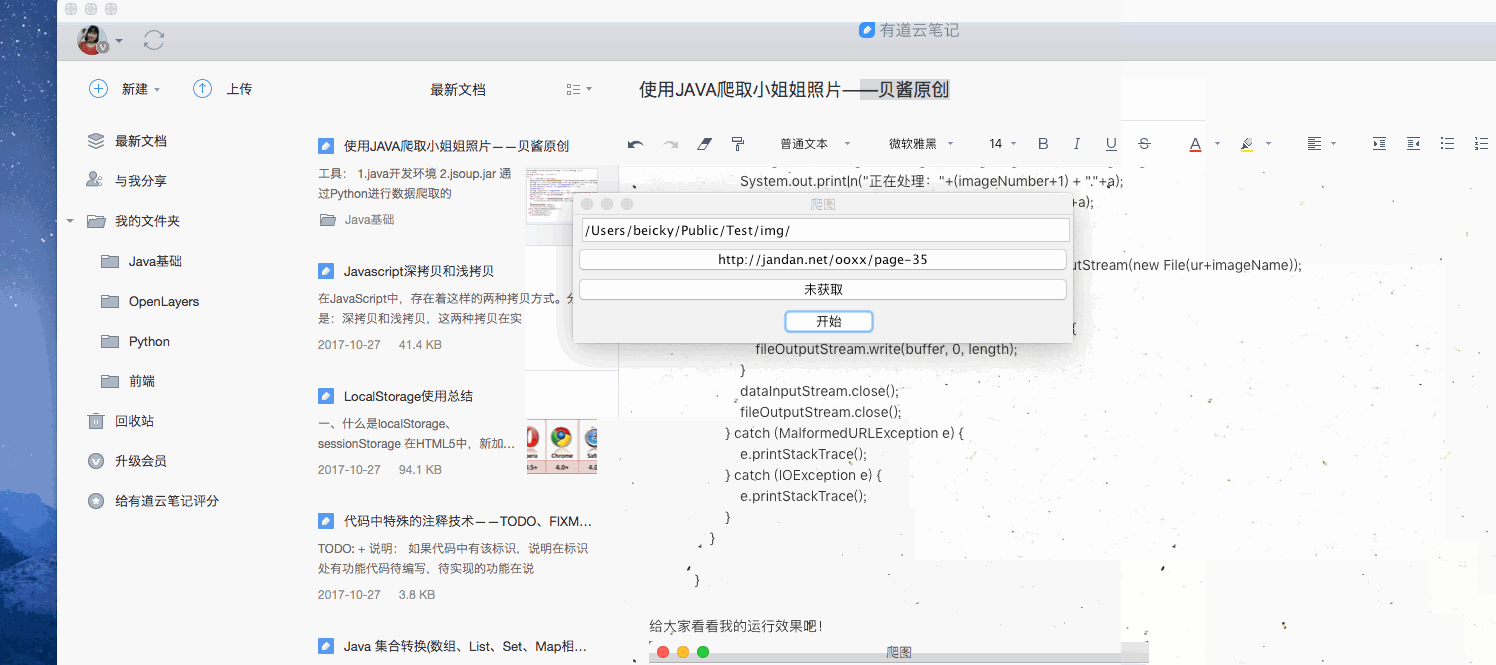 image.png
image.png
获取完毕,开始爬图
image
我写了界面你要是喜欢也可以写界面。
附件:
public class main2 {
static int num =100;//需要爬多少页
private static final String URL = "http://jandan.net/ooxx/page-";
public static List getdataByPage(int pageNow) throws IOException{
System.err.println(URL + pageNow);//打印输出每次的页码
Connection conn = Jsoup.connect(URL + pageNow)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:47.0) Gecko/20100101 Firefox/47.")
.timeout(5000)
.method(Connection.Method.GET);//模拟浏览器数据
Document doc = conn.get();//获取document对象
Element body = doc.body();//获取body对象
List resultList = new ArrayList();//创建一个集合,存爬取到的图片链接
Element articleListDiv = body.getElementById("comments");
Elements text = articleListDiv.getElementsByClass("text");
Elements imd = articleListDiv.getElementsByClass("view_img_link");
for(int a = 0;a