
Winternitz 方法:时间换取空间
上述的小窍门可以将公钥集合的大小减半,并以相同量级缩减签名的大小。这样做很棒,但称不上什么创新之举。密钥和签名仍然长达数千个位元。
如果我们能再加大力度缩减这些数字,那就更完美了。
我们采纳的最后优化手段,是由 Robert Winternitz 基于上述 Merkle 方法所提出的更进一步升级。在实际使用中,这个方法缩减了 4~8 倍的签名和公钥大小——代价是增加了签名和验证的时间。
Winternitz 的想法源自一项技术:时空权衡(time-space tradeoff)。这类解决方案使得空间需求减小,代价是增加计算时间(反之亦然)。以下几个思考能帮助我i们更好的理解 Winternitz 方法:
如果我们今天不要签名消息的每一位元(0 或 1),而是将它们视为更大的消息编码,那会怎么样呢?比如我们每 4 个位元签名一次,或是每八个位元(1 字节)签名一次?
在最初的 Lamport 方法中,我们有两列字符串作为签名密钥(和公钥)的一部分。一列是签署 0 位元用的,另一列签署 1 位元。
现在假设我们想直接对字节签名,而不是每个位元做签名。最直接的做法是将密钥(和公钥)列表从原来的两个增加到 256 个——合成一张大表,涵盖消息中每一个可能的字节。这样签名者就能从一张巨大的密钥表中选取合适的值,每次针对整个字节作签名。
不幸的是,这个主意烂透了。虽然它将签名的大小减少了8倍,付出代价却是将公钥和密钥大小增加256倍。如果这份巨大的密钥表能够用于多次签名那也就算了——但它不能。当密钥表发生重用时,这种“签整个字节版本”的 Lamport 方法也会遇到和原始 Lamport 方法一样的限制。
上面描述的种种问题,最终引出了 Winternitz 方法。
存储和分发 256 个随机密钥列成本非常高昂,如果我们只在需要签名的时候,以编程的手段生成需要的密钥呢?
Winternitz 的想法是,先替初始密钥生成一列随机种子 sk0 = (sk10, …, sk2560) 。接着他提出用哈希函数 H() 对初始密钥的每个元素进行运算得出下一列密钥:sk1 = (sk11, …, sk2561) = [ H(sk10), …, H(sk2560) ],而不是直接随机生成其他列。以此类推,可以继续使用哈希函数求得下一列 sk2。
这么做的好处是我们只需要储存一列密钥,当需要签名时再使用哈希运算生成其他密钥即可。
但公钥部分怎么办呢?这就是 Winternitz 聪明的地方!
具体来说,Winternitz 提出可以对最后一列密钥再次进行哈希散列运算,生成一列公钥: pk 。(在实际应用中,我们只需要 255 列密钥,因为最后一列密钥我们可以直接视为公钥。)这个方法的优雅之处在于,任何一个给定的密钥值都能通过公钥检查;只要持续进行哈希散列运算,然后查看是否得到最终公钥即可。
完整的密钥生成过程如下:

注意:要对字节进行签名,我们只需要 255 个密钥列,而不是 256 个。因为最后一个密钥列等同于公钥。
要对消息的第一个字节进行签名,我们需要从合适的列中选取一个值。举例来说,如果是字节 “0” ,我们将从 sk0 中输出一个值作为我们的签名;如果是字节 “20” ,我们将从 sk20 中输出一个值作为我们的签名。对于最后一个字节 “255” ,我们虽然没有对应的密钥列,但也不要紧!我们可以输出空字串或是输出 pk 中的元素。
要注意,实际上我们不需要保存每一个密钥列。通过计算推演,我们能从初始列得到所需密钥。验证者只需要拿好公钥并直接进行适当次数(视消息字节数情况而定)的哈希运算,就能够验证计算结果是否等同于正确的公钥元素。
如同前面章节讨论的 Merkle 优化方法,到目前为止所描述的 Winternitz 方法也有着明显的漏洞。因为密钥列彼此关联(即 sk1 = H(sk0)),任何人看到字节“0”及其签名,都能够轻易的将消息的字节改为 “1”,然后更新签名匹配篡改(同理可类推)。事实上,无论什么字节攻击者都能够添加到消息中。如果没有检查机制,这会导致非常严重的伪造攻击隐患。
解决这个问题的办法正如前面所提到的,如果要防止攻击者修改签名,签名者必须计算原始消息字节的校验和,并对校验和也进行签名。校验和的设计使得攻击者添加任何字节,都会使校验和失效。这里不做过多讨论,详细请参阅这里。
毫无疑问,校验和正确与否是至关重要的;只要有任何一点纰漏,都会为你带来很不好的影响。如果在生产环境中部署这样的签名,会造成严重的后果。
拿下面这个有点粗糙的图说明,对一条 4 字节的消息使用 Winternitz 签名方法:
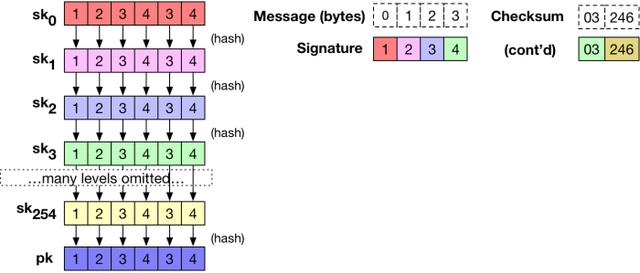
注意:示例中的消息由字节 byte 组成而不是 bit 。虽然我很确定正确地计算了校验和,但因为是手算的,有时候可能会有点小纰漏。
基于哈希函数的签名究竟有什么优势?
通篇讨论中,我们主要在讲基于哈希散列的签名如何运作的,而没有谈到为什么选择它。现在就让我们说明一下这种结构的签名特点是什么。
早期支持散列签名的观点认为,这种方法非常快速而且简单,因为这种方法只需要评估合适的哈希函数,并进行一些数据拷贝即可。纯粹从计算成本角度考虑,哈希散列签名绝对有能力和 ECDSA 、RSA 等一较高下,同时对于轻量级设备非常友好。当然,这种效率在很大程度上是以牺牲带宽为代价的。
不过(最近)关于哈希散列签名的兴起有着更复杂的原因:所有的公钥加密即将被破解。
更具体地说:即将问世的量子计算机,几乎会对所有目前使用的签名方法的安全性造成巨大的冲击,包含 RSA、ECDSA 等等。因为 Shor 算法(以及它的变体)让我们能在多项式时间内,解决离散对数和因式分解问题的方法,这使得绝大多数签名方法不再安全可靠。
大部分哈希散列签名不容易受到 Shor 算法影响。当然,我们不是说哈希散列签名能够完全抵抗量子计算攻击;对哈希运算最有效的量子攻击称作 Grover 算法,它会大大降低哈希运算的安全性 。不过这种程度的安全性影响,远小于 Shor 算法带来的影响(破解时间层级差别在平方到立方之间),因此可以简单通过增加哈希函数的运算内容和输出大小,来保障签名的安全性。像是 SHA3 系列哈希函数开发目的很明确,它能处理更大的输入,并有更好的能力对抗量子计算攻击。
至少从理论上来讲,哈希散列签名有趣之处在于它留给我们一线机会,抵御未来的量子计算攻击——或许就只能挣扎一下,谁知道呢。
未来展望
提醒一下,目前我们谈论的哈希散列签名都是“古董级”的,上述所有的哈希散列签名方法都发明于 1970 年或是早于 1980 年,这似乎不适用于今时今日。
我写完这篇文章初稿后,有许多人要我多讲讲这个领域近几年的发展。我无法给出详尽的列表,不过我能够稍微描述近几年出现的一些点子(感谢 Zooko 和 Claudio Orlandi)。
无状态签名。上述所有方法共通的一个局限在于,它们要求签名者在签名之间保持状态。对于一次性签名我们可以很直观的了解:我们必须避免重复使用任何密钥;而在 Merkle 多次签名中,我们必须记住正在使用的叶节点公钥,避免重复使用。更糟的是,Merkle 方法要求签名者先构建所有可能用上的密钥对,所以签名的数量是有限的。
在 1980 年,Oded Goldreich 指出有一种手段能够建立无需保持状态的签名 。想法如下:不预先生成所有密钥,而是生成一个简短的一次性公钥的“验证树”。每一个密钥的都可以在树的底层签署额外的一次性公钥,并以此类推。如果使用单个种子生成所有私钥,则表示完整的 Merkle 树不需要在密钥生成时存在,而可以在生成新密钥时按需求构建。每个签名都包含签名和公钥的“验证链”;从根节点开始,一直到叶节点真正用于签名的密钥对。
这项技术让我们能在非常“深”的 Merkle 树构建大量(指数级)的密钥。这允许我们构造非常多的一次性公钥,只需要我们随机地(或伪随机地)选择签名密钥,则发生密钥重用的可能性极低。当然,这是直觉想法。有关这个想法的更多优化和具体示例,请参考 Bernstein 等人的 SPHINCS 提案;SPHINCS-256 实例提供大小约为 41KB 的签名。
Picnic:后量子零知识签名(post-quantum zero-knowledge based signatures)。Picnic 是完全不同的想法,它基于一项全新的非交互式零知识证明系统(non-interactive zero-knowledge proof system) 技术,称为 ZKBoo。ZKBoo 是一种新的 ZK 证明系统,它基于一种称为“头脑中的 MPC”的技术,让证明者使用多方计算来进行自证。这已经过于复杂,无法详细解释;但最终的结果是,人们可以继续使用哈希函数来验证复杂的语句。
简而言之,Picnic 和 ZK 证明系统提供除了哈希函数签名之外的第二种思考方向。这些签名的成本仍然很高 ——高达几百千字节,但是技术演进可以大大缩减签名的量级。
结语:老套的安全提醒
如果你稍微回想一下本文,我们费了番功夫描述一些哈希函数的安全特性。这可不只是简单展示而已!你可以看到,哈希散列签名的安全性,完全取决于我们所选择的哈希函数。
(再暗示一下,哈希散列签名不安全的地方,就是攻击者已经在设法攻破的哈希函数)
大多数讨论哈希散列签名的基础的文章,通常会在哈希函数的抗原像攻击上提出安全疑虑。以 Lamport 签名为例,我们能够很直观的理解。给定一个公钥,如果攻击者能够计算出哈希运算的输入,那她就能够轻易伪造一个有效签名。这种攻击使得签名不再安全。
不过,这是攻击者只看到了公钥,却还未看到任何一个有效签名的情况。在下面情况中,攻击者能够获得更多讯息。假设她现在有了公钥和一部分的密钥 pk01 = H(sk01) 和 sk01。如果攻击者能够找到公钥 pk01 的次原像,虽然她还不能对不同的消息进行签名伪造,但实际上她已经生成了一个新的签名。对于签名安全要求特别特别严格的场景(SUF-CMA),这就可以被视为一次有效的攻击了。因此 SUF-CMA 在抗 次原像攻击上有很高的标准。
最后一个问题出现在哈希散列签名方案的大多数实际应用中。你会注意到上面的描述假定我们正在签署 256 位消息。但在实际应用中,许多消息大于 256 位。因此,大多数人使用哈希函数 H() 前,会先散列消息 D = H(M),然后再对结果值 D 进行签名,而不是直接对消息签名。
不过这会导致最后这里要提到的攻击。因为这个做法的不可伪造能力,取决于该哈希函数的抗碰撞能力。攻击者能够找到两个不同的消息 M1 ≠ M2 ,而 H(M1) = H(M2),这就表示她找到了对两条不同消息都有效的签名。这导致了 EUF-CMA 安全性的微小缺陷。
原文链接:https://blog.cryptographyengineering.com/2018/04/07/hash-based-signatures-an-illustrated-primer/
作者:Matthew Green
翻译&校对:Ian Liu & 阿剑
以太中文网经授权转载