k近临法的的是三个基本要素:k值的选择,距离度量及分类决策规则。
k近邻算法和模型
什么是k近临算法?即是:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最近临的k个实例,这k个实例的多数属于某个类,就把该输入实例归为这个类。
k近邻模型对应于基于训练数据集对特征空间的一个划分。k近邻算法中,当训练集、距离度量、k值及分类决策规则确定后,其结果唯一确定。
我理解的就是物以类聚,人以群分。根据已有的人,将新来的人按照不同属性特征来归个类。。。

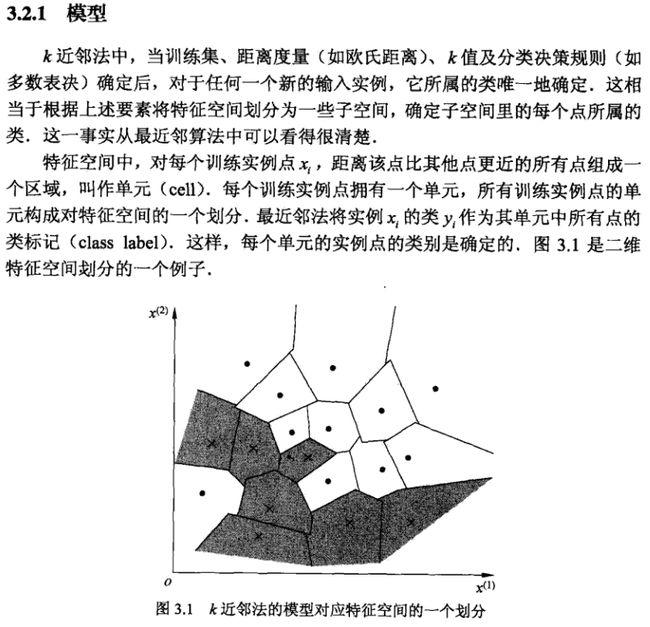
度量实例点的相似程度
用特征空间中的两个实例点的距离来度量两个实例点的相似程度。度量手段如下,最常用的是使用欧式距离。
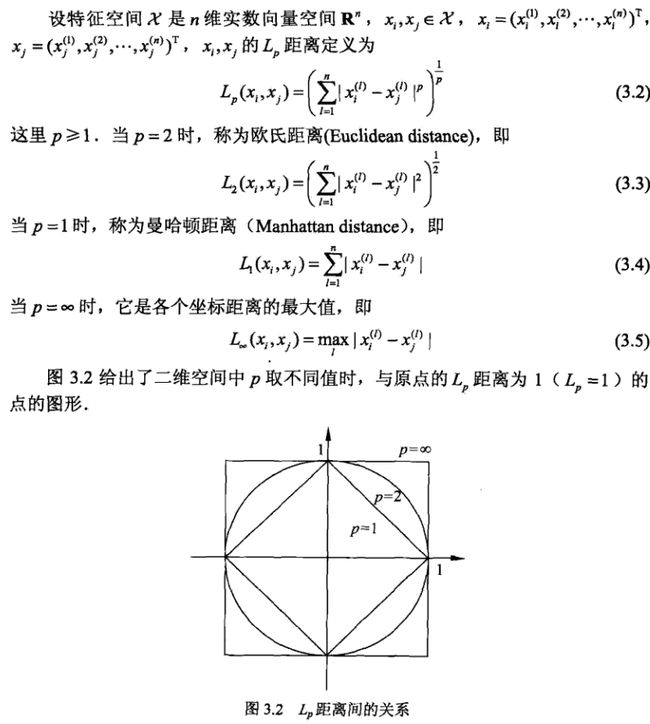
math.pow(),pow() 方法返回 x^y(x的y次方的值。
In [13]:math.pow(3,3)
Out[13]: 27.0
In [14]:math.pow(100,-2)
Out[14]: 0.0001
#课本P39例3.1
In [1]:import math
...:from itertools import combinations
In [5]: def L(x, y, p=2):
...: if len(x) == len(y) and len(x) > 1:
...: sum = 0
...: for i in range(len(x)):
...: sum += math.pow(abs(x[i] - y[i]), p)
...: return math.pow(sum, 1/p)
...: else:
...: return 0
In [6]: x1 = [1, 1]
...: x2 = [5, 1]
...: x3 = [4, 4]
In [7]: for i in range(1, 5):
...: r = { '1-{}'.format(c):L(x1, c, p=i) for c in [x2, x3]}
...: print(min(zip(r.values(), r.keys())))
(4.0, '1-[5, 1]')
(4.0, '1-[5, 1]')
(3.7797631496846193, '1-[4, 4]')
(3.5676213450081633, '1-[4, 4]')
k近临算法一般流程:
收集数据: 可以使用任何方法
准备数据: 距离计算所需要的数值, 最后是结构化的数据格式。
分析数据: 可以使用任何方法
训练算法: k近临算法不需要训练数据
测试算法: 计算错误率
使用算法: 首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理
如何选取合适的k值?
1、如果选择较小的K值。“学 习” 的近似误差( approximation error)会减小, 但“学习” 的估计误差(estimation error) 会增大,预测的结果会对近临的实例点非常敏感。话句话说,K值的减小就意味着整体模型变得复杂, 容易发生过 拟合.
2、如果选择较大的K值。可以减少学习的估计误差, 但缺点是学习的近似误差会增大.K值的增大 就意味着整体的模型变得简单。
3、在应用中,k值一般取一个比较小的数值。通常采用交叉验证法来选取最优的k值。
分类决规则?
k近临法中的分类决策规则往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类决定输入实例的类。

k近临构造kd树
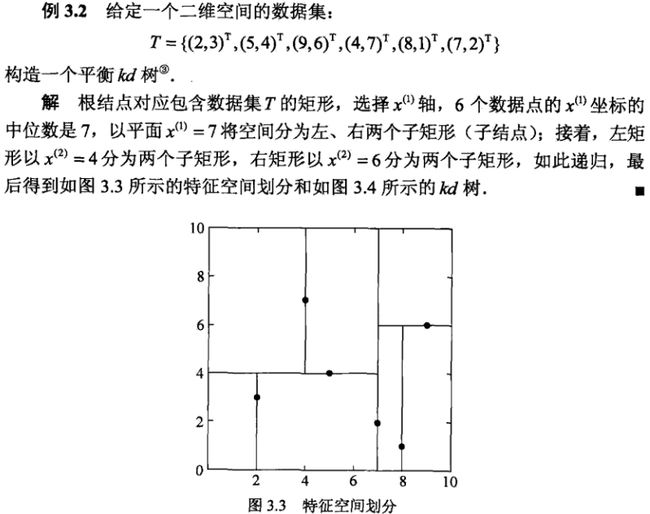
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是二叉树,表示对k维空间的一个划分。
构造kd树的方法如下:构造根节点,使根节点对应于k维空间中包含所有实例点的超矩形区域,通过递归方法(哪种递归方法,书上有所,太多文字了),不断地对k维空间进行切分,生成子节点。
书中例子如下。看不懂的话可以参见完结篇|一文搞懂k近邻(k-NN)算法(二),这个写的比较详细。

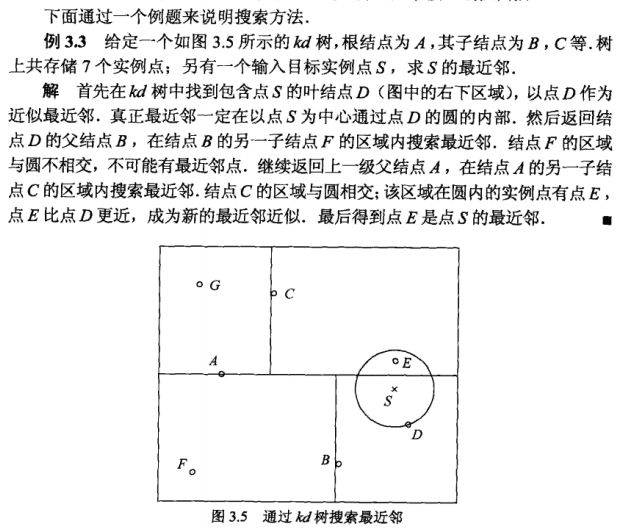
k近临搜索kd树
k近临搜索也是递归搜索,具体算法可以参见书本。
kd树更适合于训练实例数远大于空间维数时的k近邻搜索。当空间维数接近训练实例数时,它的效率会迅速下降,几乎接近线性扫描。具体可参见完结篇|一文搞懂k近邻(k-NN)算法(二)
关于k近邻的详细实现过程建议参考《机器学习实战》的第2章-k近邻算法。另外参见李航《统计学习方法》K近邻学习算法实现
调用scikitlearn的k近邻算法包
#导入相关机器学习包
In [10]: import numpy as np
...: import pandas as pd
...: from sklearn.datasets import load_iris
...: from sklearn.model_selection import train_test_split
#利用鸢尾花数据集进行测试
In [11]: iris = load_iris()
...: df = pd.DataFrame(iris.data, columns=iris.feature_names)
...: df['label'] = iris.target
...: df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
In [12]: data = np.array(df.iloc[:100, [0, 1, -1]])
...: X, y = data[:,:-1], data[:,-1]
...: X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#导入机器学习包,并对训练数据进行拟合
In [13]: from sklearn.neighbors import KNeighborsClassifier
In [14]: clf_sk = KNeighborsClassifier()
...: clf_sk.fit(X_train, y_train)
...:
Out[14]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
#对测试集进行预测
In [15]: clf_sk.score(X_test, y_test)
Out[15]: 1.0
参考链接:
一文搞懂k近邻(k-NN)算法(一)
完结篇|一文搞懂k近邻(k-NN)算法(二)
【量化课堂】一只兔子帮你理解 kNN
【量化课堂】kd 树算法之详细篇
wzyonggege/statistical-learning-method