AI 助手必须完成两项任务:理解用户和给出正确的响应。Rasa Stack 通过自然语言理解组件 Rasa NLU 和对话管理组件 Rasa Core 解决了这两项任务。Rasa NLU 高级版总共分为 3 部分:
- 第一部分:意图分类—如何更好地理解用户
- 第二部分:实体提取—为每个实体选择正确的提取器
- 第三部分:超参数—如何选择和优化它们
本文为 Rasa NLU 高级版的第一部分:意图分类—如何更好地理解用户。本文主要帮助你理解,在项目中使用哪个意图分类组件和如何解决常见的问题。
本文的目录结构:
- 意图:用户说的是什么
- 常见问题
- 总结
1. 意图:用户说的是什么
Rasa 使用意图的概念来描述如何对用户消息进行分类,Rasa NLU 会将用户消息分类到一个意图或多个意图上,你可以选择以下两个组件:
- 预训练嵌入组件(
Intent_classifier_sklearn) - 有监督嵌入组件(
Intent_classifier_tensorflow_embedding)
1.1 预训练嵌入:意图分类器 Sklearn
Sklearn 分类器是通过 spaCy 库来加载预训练语言模型,然后将用户消息中的每个单词表示为单词嵌入。词嵌入是词的向量表示,这意味着每个词都将转换为密集的数字向量。词嵌入对词的语义和句法方面进行捕捉,这意味着相似的单词应该由相似的向量表示,你可以从word2vec论文中了解更多信息。
词嵌入是针对他们所使用的语言。因此,你必须根据所使用的语言选择不同的模型。请参阅此可用的SpaCy语言模型概述。如果需要,还可以使用其他词嵌入,例如Facebook的fastText embeddings。为此,请按照spaCy指南将嵌入内容转换为兼容的spaCy模型,然后使用将链接的模型链接到您选择的语言(例如 en)python -m spacy link 。
Rasa NLU 获取消息中所有词嵌入的平均值,然后执行网格搜索以找到用于支持向量分类器的最佳参数,该向量将平均嵌入分类为不同的意图。网格搜索训练具有不同参数配置的多个支持向量分类器,然后根据测试结果选择最佳配置。
什么时候应该使用此组件:
当你使用预训练的词嵌入时,你可以从训练更强大和有意义的词嵌入的最新研究进展中受益。由于已经对嵌入进行了训练,因此 SVM 只需要很少的训练就可以做出不错的意图预测,这使得此分类器非常适合你启动上下文 AI 助手项目时使用。即使你只有少量训练数据,你也可以获得可靠的分类结果。由于训练不是从头开始,因此训练也会很快,这使得你可以缩短迭代时间。
不幸的是,并非所有语言都支持良好的词嵌入,因为大多数公开数据集都是用英语进行训练的。而且,它们也不涵盖特定领域的词,例如产品名称或首字母缩写词等。在这种情况下,最好使用有监督嵌入分类器来训练你自己的词嵌入。
1.2 有监督嵌入:意图分类器 TensorFlow Embedding
意图分类器 intent_classifier_tensorflow_embedding 由 Rasa 受Facebook starspace 论文的启发而开发的。它没有使用预训练嵌入并在此基础上训练分类器,而是从头开始训练词嵌入。它通常与 intent_featurizer_count_vectors 组件一起使用,该组件计算训练数据中不同单词在消息中出现的频率,并将其作为意图分类器的输入。在下图中,你可以看到句子的计数向量会有所不同。比如:My bot is the best bot and My bot is great,在 My bot is the best bot 语句中 bot 在句子中出现了两次。除了使用单词标记计数外,你也可以通过使用 ngram 计数将 intent_featurizer_count_vectors 组件的 analyzer 属性更改为 char。这使得意图分类对错别字更为稳健,但也增加了训练时间。

此外,为意图标签创建另一个计数向量。与预训练词嵌入的分类器相比,tensorflow 嵌入分类器还支持具有多意图消息(例如:如果用户说:嗨,天气怎么样?,消息可能会有打招呼和询问天气两个意图),这意味着计数向量不一定是 one-hot 编码。分类器为特征向量和意图向量学习单独的嵌入。两种嵌入都具有相同的维度,这使得可以使用余弦相似度来测量嵌入特征和嵌入意图标签之间的矢量距离。在训练期间,用户消息和关联的意图标签之间的余弦相似度被最大化。
什么时候应该使用此组件:
由于该分类器从头开始训练词嵌入,因此与使用预训练嵌入分类器相比,它需要更多的训练数据。但是,由于它是根据你的训练数据进行训练的,因此可以适应你的特定领域的消息,因为没有丢失词嵌入。同样,它本质上是独立于语言的,并且不依赖于特定语言的词嵌入。该分类器的另一个重要功能是支持多意图的消息。通常,这使得它是一个十分灵活的分类器,适用于高级用户场景。
请注意,在某些语言(例如中文)中,无法使用 Rasa NLU 的默认方法:通过使用空格作为分隔符将句子拆分为单词。在这种情况下,你必须使用其他分词器组件(例如 Rasa 为中文提供了 jieba 分词器)。
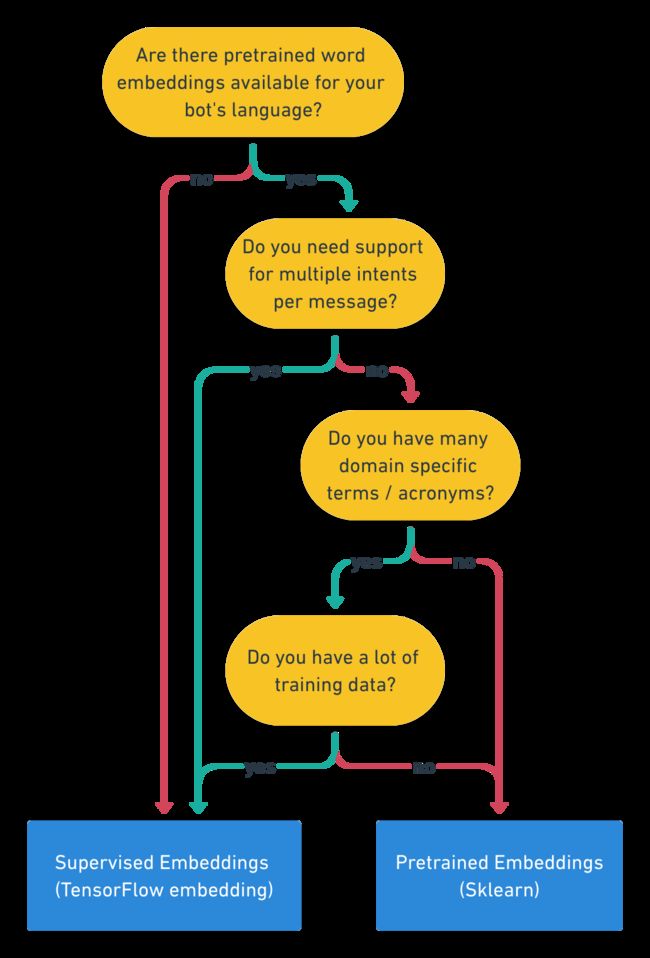
如果你仍然不确定哪个组件最适合你的上下文 AI 助手,请使用下面的流程图快速掌握经验。
2. 常见问题
2.1 训练数据不够
当机器人实际被用户使用时,你将有大量的训练数据可以从对话数据选择。但是,尤其是刚开始时,一个普遍的问题你是几乎没有训练数据,并且意图分类的准确性较低。解决此问题的常用方法是使用 Rodrigo Pimentel 开发的数据生成工具 chatito。从预定义的词块中生成句子可以快速为你提供大量数据集。避免过多使用数据生成工具,因为你的模型可能会过拟合,过度适合你生成的句子结构,我们强烈建议你使用真实用户的数据。获取更多训练数据的另一种方法是众包,例如:使用Amazon Mechanical Turk(mturk)。根据我们的经验Rasa Core的交互式学习功能对于获取新的 Core 和 NLU 训练数据也非常有帮助。
2.2 未登录词
不可避免地,你的训练模型会出现没有词嵌入的词,例如:通过打错字或使用你没有想到的词。如果你使用的是预训练词嵌入,除了尝试在较大的语料库上训练的语言模型外,你不能做其他更多事。如果你使用 intent_classifier_tensorflow_embedding 分类器从头开始训练嵌入,你有两个选择:要么包含更多训练数据,要么添加示例,其中包括 OOV_token(未登录词标记)。您可以通过配置 intent_classifier_tensorflow_embedding 组件的 OOV_token 参数(例如:设置为
2.3 相似意图
当意图非常相似时,很难区分它们。听起来很明显,但在创建意图时常常被遗忘。想象一下,用户提供其姓名或给你一个日期的时候,直觉上你可能会创建一个意图 provide_name 和意图 provide_date 。但是,从 NLU 角度来看,这些消息除了它们的实体外非常相似。因此,最好创建一个将 provide_name 和 provide_date 结合起来的意图。然后,你可以在 Rasa Core 故事中选择不同的故事路径,具体取决于 Rasa NLU 提取的实体。
2.4 数据失衡
你应该始终尽量保持在每种意图的示例数量保持大致的平衡。但是,有时候有些意图超出其他意图的训练示例。通常,越多的数据越有助于获得更好的准确性,但严重的数据失衡会导致分类器出现偏差,进而对准确性产生负面影响。Rasa NLU 高级版第三部分将介绍超参数优化,它可以帮助你缓解负面影响,但是到目前为止,最好的解决方案还是重新建立平衡的数据集。
3. 总结
本文主要介绍了 Rasa NLU 高级版第一部分:意图识别。无论你是刚刚开始上下文AI助手项目,需要快速的训练时间,还是想从头开始训练词嵌入,你都可以通过 Rasa NLU 完全自定义。
作者:关于我
备注:转载请注明出处。
如发现错误,欢迎留言指正。