PXC简介
PXC是Percona XtraDB Cluster的缩写,是 Percona 公司出品的免费MySQL集群产品。PXC的作用是通过mysql自带的Galera集群技术,将不同的mysql实例连接起来,实现多主集群。在PXC集群中每个mysql节点都是可读可写的,也就是主从概念中的主节点,不存在只读的节点。
PXC实际上是基于Galera的面向OLTP的多主同步复制插件,PXC主要用于解决MySQL集群中数据同步强一性问题。PXC可以集群任何mysql的衍生版本,例如MariaDB和Percona Server。由于Percona Server的性能最接近于mysql企业版,性能相对于标准版的mysql有显著的提升,并且对mysql基本兼容。所以在搭建PXC集群时,通常建议基于Percona Server进行搭建。
关于数据库集群方案的选择可以参考:
- 浅谈数据库集群方案
PXC的特点
- 同步复制,事务在所有集群节点要么全部提交完成,要么全部失败
- 多主复制,不存在主从角色的划分,可以在任意一个节点进行读/写操作
- 数据同步的强一致性,所有节点的数据是实时一致的
- PXC集群节点越多,数据同步的速度就越慢,所以PXC集群的规模不能太大
- PXC集群数据同步的速度取决于配置最低的节点,所以PXC集群中所有节点的硬件配置尽量保持一致
- PXC集群只支持InnoDB引擎,所以只有InnoDB引擎的数据才会被同步
安装PXC并组建集群
环境准备
环境版本说明:
- VMware Workstation Pro 15.5
- Percona XtraDB Cluster 5.7
- CentOS 8
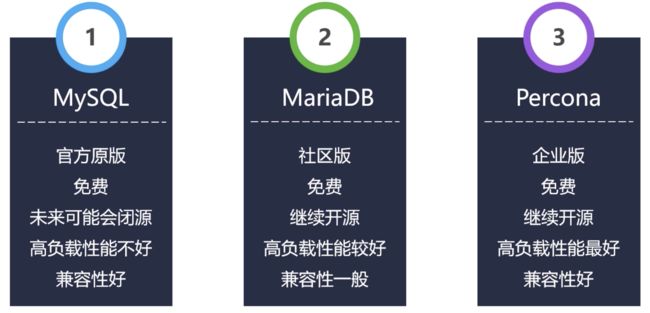
MySQL有几个常见的衍生版,Percona Server就是其一。这里选择Percona Server是因为它是最接近于企业版的MySQL。各衍生版的对比图如下:
本文的PXC集群设计如图:

- Tips:实际上最小的PXC集群是两个节点的,但课程中设计为三个节点。这是因为PXC集群为了防止脑裂,在一半以上的节点因意外宕机无法访问时,PXC集群就会自动停止运行。所以如果设计为两个节点,其中一个节点挂掉了就满足半数以上节点无法访问,那么集群就会停止运行,而另一个节点也就无法使用了。这样的容灾性太差,所以这里设计为至少三个节点,以提高PXC集群的可用性。
根据该图,我们需要创建三个虚拟机来搭建一个三节点的PXC集群:

节点说明:
| Node | Host | IP |
|---|---|---|
| Node1 | PXC-Node1 | 192.168.190.132 |
| Node2 | PXC-Node2 | 192.168.190.133 |
| Node3 | PXC-Node3 | 192.168.190.134 |
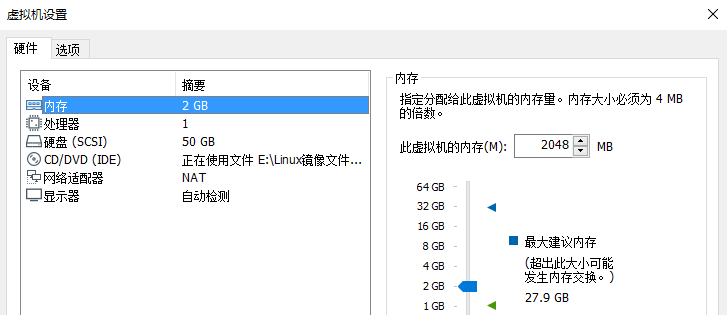
每个虚拟机的配置如下图:
关于 PXC 集群是以牺牲性能来保证数据的强一致性问题。PXC 集群中的节点越多就意味着数据同步的时间就越长,那么应该用几台数据库服务器来做集群最合适,相对来说算是能达到一个性能上最优的结果呢 ?
通常来说不超过15台节点组成一个PXC集群,性能上很好,多了就不行。然后这个PXC集群作为一个分片,MyCat上多设置几个分片,就能应对数据切分和并发访问了
系统准备
有些 CentOS 版本默认捆绑了mariadb-libs,在安装PXC之前需要先将其卸载:
[root@PXC-Node1 ~]# yum -y remove mari*
PXC集群要使用四个端口:
| 端口 | 描述 |
|---|---|
| 3306 | MySQL服务端口 |
| 4444 | 请求全量同步(SST)端口 |
| 4567 | 数据库节点之间的通信端口 |
| 4568 | 请求增量同步(IST)端口 |
所以如果系统启用了防火墙则需要开放这些端口:
[root@PXC-Node1 ~]# firewall-cmd --zone=public --add-port=3306/tcp --permanent
[root@PXC-Node1 ~]# firewall-cmd --zone=public --add-port=4444/tcp --permanent
[root@PXC-Node1 ~]# firewall-cmd --zone=public --add-port=4567/tcp --permanent
[root@PXC-Node1 ~]# firewall-cmd --zone=public --add-port=4568/tcp --permanent
[root@PXC-Node1 ~]# firewall-cmd --reload
安装PXC
先上官方文档:
- Installing Percona XtraDB Cluster
PXC有两种较为简单的安装方式,一是到官网下载rpm包到系统本地进行安装,二是使用官方提供的yum仓库进行在线安装。本文演示的是本地安装这种方式,首先打开如下网址:
- https://www.percona.com/downloads/Percona-XtraDB-Cluster-LATEST/
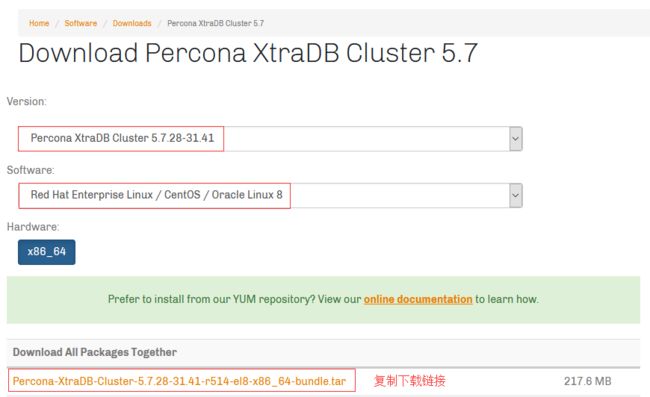
选择相应的版本后,复制下载链接:
然后到CentOS上使用wget命令进行下载,如下示例:
[root@PXC-Node1 ~]# cd /usr/local/src
[root@PXC-Node1 /usr/local/src]# wget https://www.percona.com/downloads/Percona-XtraDB-Cluster-LATEST/Percona-XtraDB-Cluster-5.7.28-31.41/binary/redhat/8/x86_64/Percona-XtraDB-Cluster-5.7.28-31.41-r514-el8-x86_64-bundle.tar
创建存放rpm文件的目录,并将下载好的PXC安装包解压缩到新建的目录中:
[root@PXC-Node1 /usr/local/src]# mkdir pxc-rpms
[root@PXC-Node1 /usr/local/src]# tar -xvf Percona-XtraDB-Cluster-5.7.28-31.41-r514-el8-x86_64-bundle.tar -C pxc-rpms
[root@PXC-Node1 /usr/local/src]# ls pxc-rpms
Percona-XtraDB-Cluster-57-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-57-debuginfo-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-57-debugsource-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-client-57-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-client-57-debuginfo-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-devel-57-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-full-57-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-garbd-57-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-garbd-57-debuginfo-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-server-57-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-server-57-debuginfo-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-shared-57-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-shared-57-debuginfo-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-test-57-5.7.28-31.41.1.el8.x86_64.rpm
Percona-XtraDB-Cluster-test-57-debuginfo-5.7.28-31.41.1.el8.x86_64.rpm
另外,PXC的安装需要依赖于qpress和percona-xtrabackup-24,可以在percona提供的仓库中获取到相应的rpm包下载链接。然后进入pxc-rpms目录下载这两个组件的rpm包,如下:
[root@PXC-Node1 /usr/local/src]# cd pxc-rpms
[root@PXC-Node1 /usr/local/src/pxc-rpms]# wget https://repo.percona.com/release/8/RPMS/x86_64/qpress-11-1.el8.x86_64.rpm
[root@PXC-Node1 /usr/local/src/pxc-rpms]# wget https://repo.percona.com/release/8/RPMS/x86_64/percona-xtrabackup-24-2.4.18-1.el8.x86_64.rpm
完成以上步骤后,现在就可以通过yum命令以本地形式安装PXC了:
[root@PXC-Node1 /usr/local/src/pxc-rpms]# yum localinstall -y *.rpm
成功安装后,系统中就会有mysql的相关命令。如下,能正常查看到版本信息代表已安装成功:
[root@PXC-Node1 /usr/local/src/pxc-rpms]# mysql --version
mysql Ver 14.14 Distrib 5.7.28-31, for Linux (x86_64) using 7.0
[root@PXC-Node1 /usr/local/src/pxc-rpms]#
配置PXC集群
安装后需要进行一些配置才能启动集群,PXC的配置文件默认位于/etc/percona-xtradb-cluster.conf.d/目录下,/etc/my.cnf文件只是对其引用:
[root@PXC-Node1 ~]# cd /etc/percona-xtradb-cluster.conf.d/
[root@PXC-Node1 /etc/percona-xtradb-cluster.conf.d]# ll
总用量 12
-rw-r--r-- 1 root root 381 12月 13 17:19 mysqld.cnf # mysql相关配置
-rw-r--r-- 1 root root 440 12月 13 17:19 mysqld_safe.cnf # mysqld_safe相关配置
-rw-r--r-- 1 root root 1066 12月 13 17:19 wsrep.cnf # PXC集群的相关配置
在mysqld.cnf文件中添加一些字符集等基本配置:
[root@PXC-Node1 /etc/percona-xtradb-cluster.conf.d]# vim mysqld.cnf
[mysqld]
...
# 设置字符集
character_set_server=utf8
# 设置监听的ip
bind-address=0.0.0.0
# 跳过DNS解析
skip-name-resolve
然后是配置PXC集群,修改wsrep.cnf文件中的如下配置项:
[root@PXC-Node1 /etc/percona-xtradb-cluster.conf.d]# vim wsrep.cnf
[mysqld]
# PXC集群中MySQL实例的唯一ID,不能重复,且必须是数字
server-id=1
# Galera库文件的路径
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
# PXC集群的名称
wsrep_cluster_name=pxc-cluster
# 集群中所有节点的ip
wsrep_cluster_address=gcomm://192.168.190.132,192.168.190.133,192.168.190.134
# 当前节点的名称
wsrep_node_name=pxc-node-01
# 当前节点的IP
wsrep_node_address=192.168.190.132
# 同步方法(mysqldump、 rsync、 xtrabackup)
wsrep_sst_method=xtrabackup-v2
# 同步时使用的帐户密码
wsrep_sst_auth=admin:Abc_123456
# 采用严格的同步模式
pxc_strict_mode=ENFORCING
# 基于ROW复制(安全可靠)
binlog_format=ROW
# 默认引擎
default_storage_engine=InnoDB
# 主键自增长不锁表
innodb_autoinc_lock_mode=2
启动PXC集群
到此为止,我们在PXC-Node1这台虚拟机上完成了PXC的安装及配置。然后到其他两个节点上完成同样的步骤即可,这里就不再重复了。
当所有的节点都准备完成后,使用如下命令启动PXC集群。注意这条的命令是用于启动首节点的,初次启动集群时首节点可以是这三个节点中的任意一个,这里我采用PXC-Node1作为首节点。故在该虚拟机下执行这条命令:
[root@PXC-Node1 ~]# systemctl start [email protected]
而其他节点只需要正常启动MySQL服务即可,启动之后会根据wsrep.cnf文件中的配置自动加入集群中:
[root@PXC-Node2 ~]# systemctl start mysqld
禁用Percona Server的开机自启动:
[root@localhost ~]# systemctl disable mysqld
Removed /etc/systemd/system/multi-user.target.wants/mysqld.service.
Removed /etc/systemd/system/mysql.service.
[root@localhost ~]#
- Tips:之所以要禁用开机自启,是因为在PXC集群中,当一个节点宕机重启后,它会随机与一个PXC节点进行数据同步。如果该节点宕机时间过长,那么需要同步的数据量就会比较大。当发生大量数据同步时,PXC集群会限制其他的写入操作,直到数据全部同步成功。所以长时间宕机之后,正确的做法是不要马上启动节点,而是先从其他节点拷贝数据文件到该节点中,然后再进行启动。这样需要同步的数据就会少很多,不会引起长时间的限速。
创建数据库账户
接着修改root账户的默认密码。我们可以在mysql的日志文件中找到初始的默认密码。下图红框标注的就是默认密码:

- Tips:默认密码只有在首次启动MySQL服务后才会生成
复制默认密码,然后使用mysql_secure_installation命令修改root账户的密码:
[root@localhost ~]# mysql_secure_installation
为了安全起见,root账户一般是不允许远程登录的,所以我们需要单独创建一个用于远程访问的数据库账户。这个账户也是用于PXC集群同步数据的账户,与wsrep.cnf文件中的wsrep_sst_auth配置项所对应:
[root@localhost ~]# mysql -uroot -p
mysql> create user 'admin'@'%' identified by 'Abc_123456';
mysql> grant all privileges on *.* to 'admin'@'%';
mysql> flush privileges;
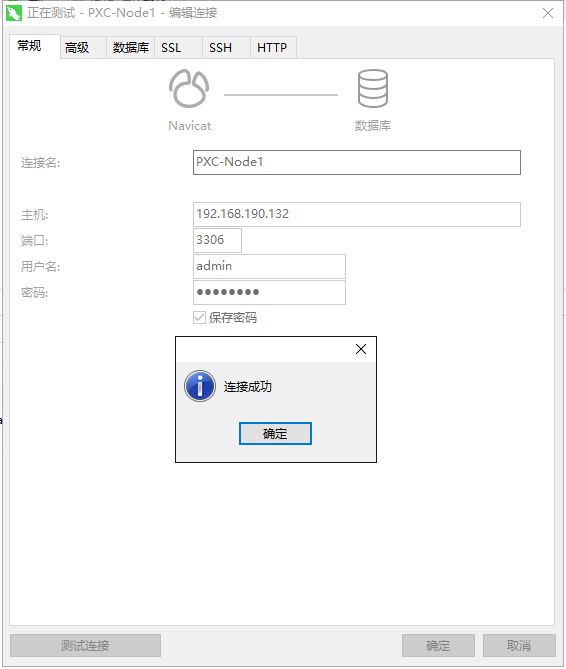
创建完账户后,使用客户端工具进行远程连接测试看看是否能正常连接成功:
到此为止,我们就算是完成PXC集群的搭建了。现在应该是已经可以看到PXC集群的同步效果的,因为上面修改root密码以及新建账户的操作都会被同步到其他两个节点上。也就是说,此时其他两个节点的root账户密码已经是修改后的密码,并且也会有一个admin账户。关于这一点可以自行验证一下。
除此之外,我们也可以使用如下语句来确认集群的状态信息:
show status like 'wsrep_cluster%';
执行结果:
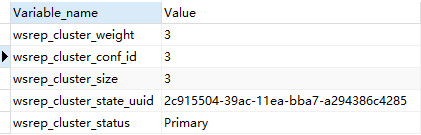
变量说明:
-
wsrep_cluster_weight:该节点在集群中的权重值 -
wsrep_cluster_conf_id:集群节点关系改变的次数(每次增加/删除都会+1) -
wsrep_cluster_size:集群中的节点个数 -
wsrep_cluster_state_uuid:集群当前状态的UUID,这是集群当前状态及其所经历的更改序列的唯一标识符。也用于比较两个或多个节点是否处于同一集群,若两个节点的该变量值一致就代表处于一个集群,如果该值不一致则表示不处于同一集群 -
wsrep_cluster_status:集群的目前状态
验证集群的数据同步
1、验证创建数据库是否能同步
在节点1中创建一个test库:
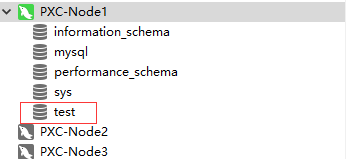
创建完成后,点击其他节点也应能看到test这个库:
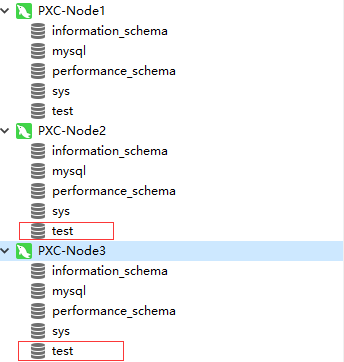
2、验证创建数据表是否能同步
在节点1中的test库里创建一张student表:
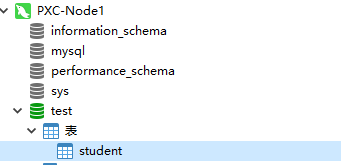
创建完成后,在其他节点也应能看到这张student表:

3、验证表数据是否能同步
往节点1中的student表里插入一条数据:
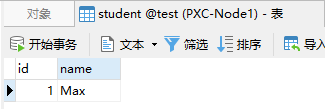
此时其他节点中也应能看到这条数据:
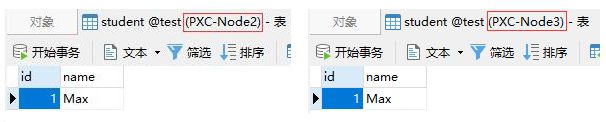
集群的状态参数说明
集群的状态参数可以通过SQL语句进行查询的,如下:
show status like '%wsrep%';
由于查询出来的状态参数变量非常的多,这里针对一些常用的进行说明。PXC集群参数可以分为以下几类:
- 队列相关
-
wsrep_local_send_queue:发送队列的长度 -
wsrep_local_send_queue_max:发送队列的最大长度 -
wsrep_local_send_queue_min:发送队列的最小长度 -
wsrep_local_send_queue_avg:发送队列的平均长度 -
wsrep_local_recv_queue:接收队列的长度 -
wsrep_local_recv_queue_max:接收队列的最大长度 -
wsrep_local_recv_queue_min:接收队列的最小长度 -
wsrep_local_recv_queue_avg:接收队列的平均长度
-
- 复制相关
-
wsrep_replicated:同步数据到其他节点的次数 -
wsrep_replicated_bytes:同步到其他节点的数据总量,单位字节 -
wsrep_received:接收到其他节点同步请求的次数 -
wsrep_received_bytes:接收到其他节点的同步数据总量,单位字节 -
wsrep_last_applied:同步应用次数 -
wsrep_last_committed:事务提交次数
-
- 流控相关
-
wsrep_flow_control_paused_ns:流控暂停状态下花费的总时间(纳秒) -
wsrep_flow_control_paused:流控暂停时间的占比(0 ~ 1) -
wsrep_flow_control_sent:发送的流控暂停事件的数量,即当前节点触发流控的次数 -
wsrep_flow_control_recv:接收的流控暂停事件的数量 -
wsrep_flow_control_interval:流控的下限和上限。上限是队列中允许的最大请求数。如果队列达到上限,则拒绝新的请求,即触发流控。当处理现有请求时,队列会减少,一旦到达下限,将再次允许新的请求,即解除流控 -
wsrep_flow_control_status:流控的开关状态(开启:ON,关闭:OFF)
-
- 事务相关
-
wsrep_cert_deps_distance:事务执行的并发数 -
wsrep_apply_oooe:接收队列中事务的占比 -
wsrep_apply_oool:接收队列中事务乱序执行的频率 -
wsrep_apply_window:接收队列中事务的平均数量 -
wsrep_commit_oooe:发送队列中事务的占比 -
wsrep_commit_oool:无任何意义(不存在本地乱序提交) -
wsrep_commit_window:发送队列中事务的平均数量
-
- 状态相关
-
wsrep_local_state_comment:节点的当前状态 -
wsrep_cluster_status:集群的当前状态 -
wsrep_connected:节点是否连接到集群 -
wsrep_ready集群是否正常工作 -
wsrep_cluster_size:集群中的节点个数 -
wsrep_desync_count:延时节点的数量 -
wsrep_incoming_addresses:集群中所有节点的IP地址
-
PXC节点状态图:

-
OPEN:节点启动成功 -
PRIMARY:节点成功加入集群 -
JOINER:与其他节点同步数据 -
JOINED:与其他节点同步数据成功 -
SYNCED:与集群同步完成,可以对外提供服务 -
DONER:接收其他节点的全量数据同步,处于不可用
PXC集群状态图:
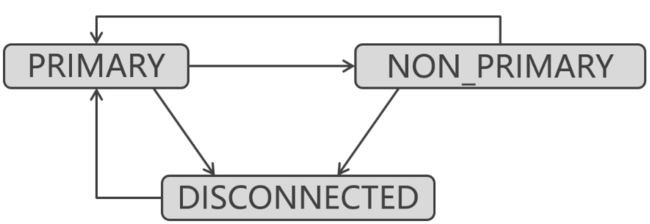
-
PRIMARY:正常状态 -
NON_PRIMARY:集群发生脑裂 -
DISCONNECTED:集群处于无法连接状态
官方文档:
- Index of wsrep status variables
- Galera Status Variables
关于PXC节点的上线与下线
1、PXC节点的安全下线姿势
节点是怎么启动的,就使用对应的命令去关闭即可
- 首节点示例:
- 启动首节点用的命令是:
systemctl start [email protected] - 那么对应的关闭命令就是:
systemctl stop [email protected]
- 启动首节点用的命令是:
- 其他节点示例:
- 启动其他节点的命令是:
systemctl start mysqld - 那么对应的关闭命令就是:
systemctl stop mysqld
- 启动其他节点的命令是:
2、如果所有PXC节点都是安全下线的,那么在启动集群时,就需要先启动最后下线的节点
初次启动集群时可以将任意一个节点作为首节点启动。但如果是一个已经启动过的集群,那么当该集群下线再上线时,就需要将最后下线的节点作为首节点来启动。其实关于某个节点是否能作为首节点启动,可以通过查看 grastate.dat 文件得知:
[root@PXC-Node1 ~]# cat /var/lib/mysql/grastate.dat
# GALERA saved state
version: 2.1
uuid: 2c915504-39ac-11ea-bba7-a294386c4285
seqno: -1
safe_to_bootstrap: 0
[root@PXC-Node1 ~]#
- 说明:
safe_to_bootstrap的值为0时表示不能作为首节点启动,为1时表示可以作为首节点启动。PXC集群中最后一个下线的节点就会将safe_to_bootstrap的值改为1,下次启动集群时就需要将该节点作为首节点启动。这是因为最后一个下线的节点数据是最新的。将其作为首节点启动,然后让其他节点与该节点进行数据同步,这样才能保证集群中的数据是最新的。否则,可能会导致集群中的数据是某个时间点之前的旧数据。
3、如果PXC节点都是意外退出的,而且不是在同一时间退出的情况
在本文开头提到过,PXC集群中一半以上的节点因意外宕机而无法访问时,PXC集群就会停止运行。但如果这些PXC节点是以安全下线的方式退出,则不会引发集群自动停止运行的问题,只会缩小集群的规模。只有意外下线一半以上节点时集群才会自动停止,意外下线的情况包括:
- 宕机、挂起、关机、重启、断电、断网等等,反正就是没有使用相应的停止命令安全下线节点都属于意外下线
只要PXC集群中的节点不是同时意外退出的,那么当集群还剩一个节点时,该节点就会自动将grastate.dat文件中的safe_to_bootstrap值改为1。所以在重启集群时,也是先启动最后一个退出的节点。
4、如果PXC节点都是同时意外退出的,则需要修改grastate.dat文件
当集群中所有节点都是在同一时间因意外情况而退出,那么此时所有节点的safe_to_bootstrap都为0,因为没有一个节点来得及去修改safe_to_bootstrap的值。当所有节点的safe_to_bootstrap均为0时,PXC集群是无法启动的。
在这种情况下我们就只能手动选择一个节点,将safe_to_bootstrap修改为1,然后将该节点作为首节点进行启动:
[root@PXC-Node1 ~]# vim /var/lib/mysql/grastate.dat
...
safe_to_bootstrap: 1
[root@PXC-Node1 ~]# systemctl start [email protected]
接着再依次启动其他节点即可:
[root@PXC-Node2 ~]# systemctl start mysqld
5、如果集群中还有可运行的节点,那么其他下线的节点只需要按普通节点上线即可
[root@PXC-Node2 ~]# systemctl start mysqld