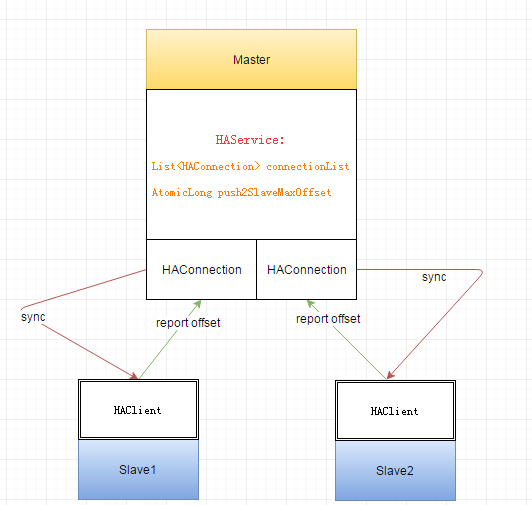
说一下rmq master 同步消息slave 的整个流程,与kafka的高水位同步机制有点类似,但简化了很多处理:
①master 会为每一个slave 建立一个长连接通道,所有的slave 与master 高可用同步相关的信息 均通过该通道传输。
②slave根据与master长连接的心跳时间,向master 发送当前pagecache中最大的物理位移(report offset),即以report offset 作为心跳包。
③Master 收到slave 的report offset后,根据slave的report offset(currentReportedOffset) 向slave同步(sync) 一定量业务消息字节。
④Slave接受到Master的同步业务消息字节以后,把业务消息字节写入pagecache中,然后在将当前已写入pagecache的最大物理位移立刻响应(report offset)给Master。
⑤Master 根据收到集群中的Slave 同步的Report offset(currentReportedOffset) 消息,判断自己当前push2SlaveMaxOffset(该字段的含义就是所有slave向Master 同步的currentReportedOffset中的最大值)是否比currentReportedOffset大,如果大于,则不做任何处理,如果小于,则将currentReportedOffset的值覆盖push2SlaveMaxOffset。
⑥对于同步写消息的producer 来说,只要push2SlaveMaxOffset值不小于producer端请求的消息落盘位置,直接ack 响应producer成功。换言之,只要集群中有一个slave已经把消息写入缓存的位置与master的最新刷盘位置一样,那么消息的高可用部分就是成功的。
这里注意一下的是,步骤②中的master读取report offset 以及步骤③的同步业务消息字节是并发执行的,分别由ReadSocketService 和WriteSocketService 委托完成,共享slaveAckOffset变量协作完成;即当ReadSocketService 读取到slave的report offset 时,会更新slaveAckOffset;而WriteSocketService 则根据最新slaveAckOffset在向slave同步业务消息字节。唤醒producer也是并发执行的,由ReadSocketService 根据GroupTransferService类完成。然后在循环执行2-5中的每一个步骤
延伸一下:
倘若broker在 brokerRole=SYNC_MASTER,flushDiskType=SYNC_FLUSH也即全同步配置,并且producer也是同步发送消息以及broker已经ack producer,那么在什么情况下会丢消息?
首先,slave集群中,只有一个slave把master最新的消息同步到pagecache中;此时,如果master挂掉了,并且磁盘受损了,并且slave在这时候刚好也宕机了;综上所述,消息就会丢失。
接下来就从源码上分析rmq如何实现上述的高可用流程,分析之前,我们先看看高可用几个关键类:
public class HAService {
private final List connectionList = new LinkedList<>();
private final AcceptSocketService acceptSocketService;
private final AtomicLong push2SlaveMaxOffset = new AtomicLong(0);
}
public class HAConnection {
private WriteSocketService writeSocketService;
private ReadSocketService readSocketService;
}
class HAClient extends ServiceThread {
private SocketChannel socketChannel;
private long currentReportedOffset = 0;
}
总结一下各个类:
HAService 代表Master 端 的高可用业务抽象,它主要负责维持slave端发起的连接管理(List
HAConnection 代表一个slave与master的连接抽象,通过ReadSocketService 读取由slave端发过来的report offset 消息以及通过WriteSocketService 把消息同步给slave端。
HAClient 代表一个slave客户端的通讯抽象类,slave所有接受消息同步与report offset均由该业务抽象完成。
接下来我们主要从六个步骤分析整个高可用流程::
1、master端接收slave端连接
2、slave从pagecache中读取最大的消息物理位移,向master发起report offset
3、master委托ReadSocketService读取slave report offset
4、master根据report offset向slave同步一定量业务消息字节
5、slave接受master 业务消息字节后的处理
6、唤醒同步阻塞高可用步骤的producer 发送消息请求
1、master端接收slave端连接。
1、HAService .start()
public void start() throws Exception {
this.acceptSocketService.beginAccept();
this.acceptSocketService.start();
this.groupTransferService.start();
this.haClient.start();
}
HAService.start() 在broker启动时调用,具体的broker启动流程我们先不管,以后再专门分析。
我们看看start方法中直接委托acceptSocketService先接收连接请求:
1.1、acceptSocketService.beginAccept()
public void beginAccept() throws Exception {
this.serverSocketChannel = ServerSocketChannel.open();
this.selector = RemotingUtil.openSelector();
this.serverSocketChannel.socket().setReuseAddress(true);
this.serverSocketChannel.socket().bind(this.socketAddressListen);
this.serverSocketChannel.configureBlocking(false);
//注册连接监听事件
this.serverSocketChannel.register(this.selector, SelectionKey.OP_ACCEPT);
}
上述代码片段是典型的nio初始化用法,初始化ServerSocketChannel并注册监听连接事件。
1.2、acceptSocketService.start()
由于acceptSocketService是一个线程类,所以我们直接看run()方法(Master服务端)
@Override
public void run() {
while (!this.isStopped()) {
try {
//多路复用,select所有生效事件(读、写、连接)
this.selector.select(1000);
Set selected = this.selector.selectedKeys();
if (selected != null) {
//遍历的连接请求
for (SelectionKey k : selected) {
if ((k.readyOps() & SelectionKey.OP_ACCEPT) != 0) {
SocketChannel sc = ((ServerSocketChannel) k.channel()).accept();
if (sc != null) {
try {
//为每一个slave 建立连接处理委托类
HAConnection conn = new HAConnection(HAService.this, sc);
//启动同步任务
conn.start();
HAService.this.addConnection(conn);
} catch (Exception e) {
log.error("new HAConnection exception", e);
sc.close();
}
}
}
...
}
selected.clear();
}
}
...
}
}
通过多路复用,获取所有有效事件 Set,遍历事件;因为acceptSocketService只监听连接事件,所以遍历的所有事件中,均是 SelectionKey.OP_ACCEPT连接事件。换言之,每一个slave发起的连接,master都会为之建立一个HAConnection 实例。然后启动同步任务HAConnection.start()
1.3、this.haClient.start();
slave客户端发起连接,由于HAClient也是一个线程类,所以直接看run();
@Override
public void run() {
while (!this.isStopped()) {
try {
//connectMaster is true ,该broker 为 slaver,在connect 注册了读事件
if (this.connectMaster()) {
...//省略处理流程
} else {
//等待五秒
this.waitForRunning(1000 * 5);
}
}
...
}
..
}
从run()方法中,我们可以看出,对于HAClient,也是在一个循环体里,先判断this.connectMaster()是否连接Master成功,否则就等待5秒。我们接着看this.connectMaster()是如何连接Master的:
private boolean connectMaster() throws ClosedChannelException {
if (null == socketChannel) {
String addr = this.masterAddress.get();
//如果addr 不等于null,说明该broker是slave ,因此需要直连master broker 。
if (addr != null) {
SocketAddress socketAddress = RemotingUtil.string2SocketAddress(addr);
if (socketAddress != null) {
//连接为同步
this.socketChannel = RemotingUtil.connect(socketAddress);
if (this.socketChannel != null) {
//注册读事件
this.socketChannel.register(this.selector, SelectionKey.OP_READ);
}
}
}
//获取当前已同步的最大offset
this.currentReportedOffset = HAService.this.defaultMessageStore.getMaxPhyOffset();
this.lastWriteTimestamp = System.currentTimeMillis();
}
return this.socketChannel != null;
}
连接master的逻辑也比较简单,首先是同步等待连接Master的结果,然后注册监听处理所有的读事件,这里说一下为什么不监听可写事件?应为一般情况下,tcp的send buffer 发送缓冲区都是非满状态的,所以,直接调用int len = socketChannel.write(ByteBuffer),都可以写成功的;那什么时候需要注册写事件呢,就是发送消息太频繁,导致send buffer满了,然后len=0的情况下,我们就可以注册写事件了。
建立连接分析完。
2、slave从pagecache中读取最大的消息物理位移,向master发起report offset
因为master与slave建立连接以后,必定先由slave以心跳包的形式向master发送当前已写入pagecache中的最大 业务消息物理位移 (report offset),当然,slave的每次与master通讯均会归零心跳超时时间:
@Override
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
if (this.connectMaster()) {
//是否 到达导出当前本slaver已同步的最大offset 给 master;
if (this.isTimeToReportOffset()) {
boolean result = this.reportSlaveMaxOffset(this.currentReportedOffset);
//如果发送失败
//则释放连接master的资源,等待下一次重连成功,循环以上操作
if (!result) {
this.closeMaster();
}
}
...
}
}
...
}
}
我们接着进入
this.reportSlaveMaxOffset(this.currentReportedOffset)
this.currentReportedOffset的值在this.connectMaster(),第一次与master建立连接是初始化,其值为:
this.currentReportedOffset = HAService.this.defaultMessageStore.getMaxPhyOffset(),即slave pagecache中最大的业务消息物理位移
private boolean reportSlaveMaxOffset(final long maxOffset) {
this.reportOffset.position(0);
this.reportOffset.limit(8);
this.reportOffset.putLong(maxOffset);
this.reportOffset.position(0);
this.reportOffset.limit(8);
for (int i = 0; i < 3 && this.reportOffset.hasRemaining(); i++) {
try {
this.socketChannel.write(this.reportOffset);
} catch (IOException e) {
log.error(this.getServiceName()
+ "reportSlaveMaxOffset this.socketChannel.write exception", e);
return false;
}
}
return !this.reportOffset.hasRemaining();
}
report offset 的逻辑比较简单,往reportOffset 缓冲里填充八字节的maxOffset,然后同步写入tcp缓冲区中,写完以后直接返回。换句话说,write()返回之时,数据不一定会发送到对端去(master方),write()仅仅是把应用层buffer的数据拷贝进socket的内核发送buffer中,发送是TCP层的事情,和write其实没有太大关系。
3、master委托ReadSocketService读取slave report offset
之前说到,每一个slave 与master建立连接时,master都会为slave建立一个与之对应的HAConnection实例,然后在委托HAConnection内部类的WriteSocketService以及ReadSocketService与slave的进行高可用相关的通讯以及业务逻辑处理,这两个内部类均是一个线程类,他们在HAConnection创建时,通过
new HAConnection(HAService.this, sc):
public HAConnection(final HAService haService, final SocketChannel socketChannel) throws IOException {
this.haService = haService;
this.socketChannel = socketChannel;
this.clientAddr = this.socketChannel.socket().getRemoteSocketAddress().toString();
this.socketChannel.configureBlocking(false);
this.socketChannel.socket().setSoLinger(false, -1);
this.socketChannel.socket().setTcpNoDelay(true);
this.socketChannel.socket().setReceiveBufferSize(1024 * 64);
this.socketChannel.socket().setSendBufferSize(1024 * 64);
this.writeSocketService = new WriteSocketService(this.socketChannel);
this.readSocketService = new ReadSocketService(this.socketChannel);
this.haService.getConnectionCount().incrementAndGet();
}
创建的实例。
委托HAConnection.start()启动的。
其中,ReadSocketService的责任主要是读取由slave发送的report offset消息,我们直接进入run()方法:
@Override
public void run() {
HAConnection.log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
//多路复用,选择所有有效事件
this.selector.select(1000);
//处理读事件
boolean ok = this.processReadEvent();
if (!ok) {
HAConnection.log.error("processReadEvent error");
break;
}
//判断心跳是否超时
long interval = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now() - this.lastReadTimestamp;
if (interval > HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaHousekeepingInterval()) {
log.warn("ha housekeeping, found this connection[" + HAConnection.this.clientAddr + "] expired, " + interval);
break;
}
} catch (Exception e) {
HAConnection.log.error(this.getServiceName() + " service has exception.", e);
break;
}
}
...
}
run()方法中主要做了三件事。
第一,多路复用选择,获取由slave发送的report offset字节;
第二,根据读取的report offset,处理读事件this.processReadEvent();
第三,判断心跳是否超时;如果processReadEvent()出现异常或者心跳超时,均断开与对应slave的连接,以及释放所有相对应的资源。
我们重点看一下处理读事件的逻辑:
this.processReadEvent()
//slave 每次report 的offset 消息的大小为8 bytes,
private boolean processReadEvent() {
int readSizeZeroTimes = 0;
//这里表示byteBufferRead满
if (!this.byteBufferRead.hasRemaining()) {
//reset byteBufferRead : position=0, limit = capacity
this.byteBufferRead.flip();
this.processPostion = 0;
}
while (this.byteBufferRead.hasRemaining()) {
try {
int readSize = this.socketChannel.read(this.byteBufferRead);
if (readSize > 0) {
readSizeZeroTimes = 0;
this.lastReadTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();
//slave 每次report 的offset 消息的大小为8 bytes,解决拆包问题
if ((this.byteBufferRead.position() - this.processPostion) >= 8) {
//这里的意思即为读最新一条完整的消息;this.byteBufferRead.position() % 8 这里的意思是最新一条消息是否读取完整
//如果为0 则表示是一条完整的消息;如果存在余数,则余数表示这条消息已读的字节数;
//解决粘包问题
int pos = this.byteBufferRead.position() - (this.byteBufferRead.position() % 8);
//pos :start read index
long readOffset = this.byteBufferRead.getLong(pos - 8);
this.processPostion = pos;
//更新slave的响应offset
HAConnection.this.slaveAckOffset = readOffset;
if (HAConnection.this.slaveRequestOffset < 0) {
HAConnection.this.slaveRequestOffset = readOffset;
log.info("slave[" + HAConnection.this.clientAddr + "] request offset " + readOffset);
}
//
HAConnection.this.haService.notifyTransferSome(HAConnection.this.slaveAckOffset);
}
} else if (readSize == 0) {
if (++readSizeZeroTimes >= 3) {
break;
}
} else {
log.error("read socket[" + HAConnection.this.clientAddr + "] < 0");
return false;
}
} catch (IOException e) {
log.error("processReadEvent exception", e);
return false;
}
}
return true;
}
总结一下,先通过this.socketChannel.read(this.byteBufferRead)从网络中读取slave发送的report offset的字节内容;
接着通过(this.byteBufferRead.position() - this.processPostion) >= 8确保byteBufferRead缓存中至少存在一次report offset的字节内容;
然后在通过int pos = this.byteBufferRead.position() - (this.byteBufferRead.position() % 8)确保每次只读8字节,即report offset的实际值,同时根据读取回来的readOffset更新至WriteSocketService以及ReadSocketService的共享变量slaveRequestOffset中,WriteSocketService是根据该值在决定下一次同步给slave的业务消息字节;
最后在委托HAConnection.this.haService.notifyTransferSome(HAConnection.this.slaveAckOffset)唤醒同步阻塞在高可用等待的producer 发送 消息的请求。最后在分析这个实现。
这里需要注意的一点是,为了防止cpu空轮转,读3次以后还不能读到一条完整的消息后,就让该处理线程睡眠指定时间。
到这里,已近分析master如何读取slave 的report offset字节内容。
4、master根据report offset向slave同步一定量业务消息字节
根据上一步的分析,WriteSocketService是一个线程类,所以我们直接分析run():
@Override
public void run() {
while (!this.isStopped()) {
try {
this.selector.select(1000);
//step1,如果slave 所请求的需要最新同步的offset 为-1 ,表明slave没有report当前已同步最大的逻辑位移,继续新一轮循环
if (-1 == HAConnection.this.slaveRequestOffset) {
Thread.sleep(10);
continue;
}
//这里的做法是如果当前没有需要同步的业务消息字节,则没过五秒发送一次心跳包,心跳包的内容则是一个空内容的消息头msgHeader(12byte),消息头仅包括由master维护的,对应slave的已同步最大字节位移;否则, 才会同步业务消息
if (this.lastWriteOver) {
long interval =
HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now() - this.lastWriteTimestamp;
//发送心跳包
if (interval > HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig()
.getHaSendHeartbeatInterval()) {
// Build Header
this.byteBufferHeader.position(0);
//headerSize = 8 + 4
this.byteBufferHeader.limit(headerSize);
//需要slave同步的offset
this.byteBufferHeader.putLong(this.nextTransferFromWhere);
//同步的消息长度
this.byteBufferHeader.putInt(0);
this.byteBufferHeader.flip();
//传输数据
this.lastWriteOver = this.transferData();
if (!this.lastWriteOver)
continue;
}
} else { //代码走到这里表明上一条消息还没有传输完,继续传输
this.lastWriteOver = this.transferData();
if (!this.lastWriteOver)
continue;
}
//step3,这里获取nextTransferFromWhere 所在的MappedFile 的从nextTransferFromWhere到MappedFile尾部的小消息字节获取,里面就是业务消息的字节内容
SelectMappedBufferResult selectResult =
HAConnection.this.haService.getDefaultMessageStore().getCommitLogData(this.nextTransferFromWhere);
if (selectResult != null) {
int size = selectResult.getSize();
//保证每次只同步32k
if (size > HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaTransferBatchSize()) {
size = HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaTransferBatchSize();
}
long thisOffset = this.nextTransferFromWhere;
this.nextTransferFromWhere += size;
selectResult.getByteBuffer().limit(size);
//赋值业务消息字节,也是同步给slave的业务消息字节
this.selectMappedBufferResult = selectResult;
// Build Header
this.byteBufferHeader.position(0);
this.byteBufferHeader.limit(headerSize);
//同步的开始物理偏移量位置
this.byteBufferHeader.putLong(thisOffset);
//同步的消息长度
this.byteBufferHeader.putInt(size);
this.byteBufferHeader.flip();
//step4,向slave传输数据
this.lastWriteOver = this.transferData();
} else {
//代码走到这里, 说明WriteSocketService同步线程已近同步最新的业务消息字节,
//因此,等待100毫秒,防止cpu空轮转
HAConnection.this.haService.getWaitNotifyObject().allWaitForRunning(100);
}
} catch (Exception e) {
HAConnection.log.error(this.getServiceName() + " service has exception.", e);
break;
}
}
...
}
这里先说明:
一次完整的业务消息字节同步分两次发送:msgHeader(12byte) + msgBody。第一次发送消息头,消息头由 8字节(masterPhyOffset) + 4字节(bodySize)组成。masterPhyOffset表示master已经同步给slave的字节数,bodySize表示这次发送真正的业务消息字节大小。msgBody就是业务消息的字节内容了。这是比较常用的解决粘包拆包的方法
总结一下run流程:
step1,先判断-1 == HAConnection.this.slaveRequestOffset,如果slaveRequestOffset为-1,则说明到目前为止,还没有收到slave第一次report offset,因为master需要根据第一次slaveRequestOffset值,来决定同步slave业务消息字节的位置;因此,WriteSocketService继续休眠。
如果slaveRequestOffset不为-1,则表明slave已经向master发出第一次report offset。
step2,判断master 与slave的通讯是否超过指定的心跳时间,如果是,WriteSocketService会以发送一条心跳消息给slave,心跳包的内容是一个msgHeader(12byte) 。否则,才会进行完整的业务消息字节同步。这里通过lastWriteOver标志位来判断一次完整的消息字节同步。
step3,同步完整的业务消息字节;首先,会根据this.nextTransferFromWhere获取SelectMappedBufferResultselectResult = HAConnection.this.haService.getDefaultMessageStore().getCommitLogData(this.nextTransferFromWhere),即从pagecache中获取具体的业务消息字节内容;然后填充byteBufferHeader消息头。
step4,this.transferData(),向slave传输数据。
我们分析一下
this.transferData()实现。
private boolean transferData() throws Exception {
int writeSizeZeroTimes = 0;
// Write Header,同步写
while (this.byteBufferHeader.hasRemaining()) {
int writeSize = this.socketChannel.write(this.byteBufferHeader);
if (writeSize > 0) {
writeSizeZeroTimes = 0;
//更新最后一次 写时间
this.lastWriteTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();
} else if (writeSize == 0) {
if (++writeSizeZeroTimes >= 3) {
break;
}
} else {
throw new Exception("ha master write header error < 0");
}
}
if (null == this.selectMappedBufferResult) {
return !this.byteBufferHeader.hasRemaining();
}
writeSizeZeroTimes = 0;
// Write Body
if (!this.byteBufferHeader.hasRemaining()) {
while (this.selectMappedBufferResult.getByteBuffer().hasRemaining()) {
int writeSize = this.socketChannel.write(this.selectMappedBufferResult.getByteBuffer());
if (writeSize > 0) {
writeSizeZeroTimes = 0;
this.lastWriteTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();
} else if (writeSize == 0) {
if (++writeSizeZeroTimes >= 3) {
break;
}
} else {
throw new Exception("ha master write body error < 0");
}
}
}
boolean result = !this.byteBufferHeader.hasRemaining() && !this.selectMappedBufferResult.getByteBuffer().hasRemaining();
if (!this.selectMappedBufferResult.getByteBuffer().hasRemaining()) {
this.selectMappedBufferResult.release();
this.selectMappedBufferResult = null;
}
return result;
}
总结一下就是先写消息头,在写消息体。不管是写头部信息,还是消息体信息,均做以下容错处理,就是往tcp层的send buffer写内容时,如果有连续三次都无法写进至少1个字节,则认为写入失败,需断开master与slave的连接,等待重新连接处理。因为出现这种情况的源头是send buffer无法正常往对端发送消息,导致send buffer 满了。
5、slave接受master 业务消息字节后的处理
我们继续回到 HAClient 的 run()方法
@Override
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
//connectMaster is true ,该broker 为 slaver,在connect 注册了读事件
if (this.connectMaster()) {
...
//处理读事件
boolean ok = this.processReadEvent();
//处理不成功,释放连接master的相公资源
if (!ok) {
this.closeMaster();
}
if (!reportSlaveMaxOffsetPlus()) {
continue;
}
...
} else {
//等待五秒
this.waitForRunning(1000 * 5);
}
} catch (Exception e) {
log.warn(this.getServiceName() + " service has exception. ", e);
this.waitForRunning(1000 * 5);
}
}
log.info(this.getServiceName() + " service end");
}
继续跟进this.processReadEvent(),该方法为具体的去读master同步业务消息字节逻辑
private boolean processReadEvent() {
int readSizeZeroTimes = 0;
//初始化byteBufferRead 的大小为4m;
//
while (this.byteBufferRead.hasRemaining()) {
try {
//读取master通过消息,并填充至byteBufferRead缓冲
int readSize = this.socketChannel.read(this.byteBufferRead);
if (readSize > 0) {
lastWriteTimestamp = HAService.this.defaultMessageStore.getSystemClock().now();
readSizeZeroTimes = 0;
//处理读取逻辑
boolean result = this.dispatchReadRequest();
if (!result) {
log.error("HAClient, dispatchReadRequest error");
return false;
}
} else if (readSize == 0) {
//连续读取三次空字节后,认为master暂时无同步内容,直接返回
if (++readSizeZeroTimes >= 3) {
break;
}
} else {
// TODO ERROR
log.info("HAClient, processReadEvent read socket < 0");
return false;
}
} catch (IOException e) {
log.info("HAClient, processReadEvent read socket exception", e);
return false;
}
}
return true;
}
上述逻辑处理中,处理任何异常,均认为需要断开master与slave的连接。
我们直接分析this.dispatchReadRequest()
private boolean dispatchReadRequest() {
final int msgHeaderSize = 8 + 4; // phyoffset + size
int readSocketPos = this.byteBufferRead.position();
//手工处理拆包粘包问题
while (true) {
// 假设byteBufferRead.position = 0,dispatchPostion=0;
//dispatchPostion 记录每一个master写过来的每条消息的总大小
//例如一条master commit msg 的大小为 8(phyoffset) + 4(size) + bodySize
//而readSocketPos = 8(phyoffset) + 4(size) + bodySize + 2
// 则读完消息以后dispatchPostion的位置为8(phyoffset) + 4(size) + bodySize
// byteBufferRead.position = 8(phyoffset) + 4(size) + bodySize + 2
int diff = this.byteBufferRead.position() - this.dispatchPostion;
if (diff >= msgHeaderSize) {
// 8 bytes length for master physical offset
long masterPhyOffset = this.byteBufferRead.getLong(this.dispatchPostion);
// 4 bytes body size length
int bodySize = this.byteBufferRead.getInt(this.dispatchPostion + 8);
// slave physical offset
long slavePhyOffset = HAService.this.defaultMessageStore.getMaxPhyOffset();
if (slavePhyOffset != 0) {
//如果master 发送该slave已同步的masterPhyOffset != currentSlaveOffset 的话,直接返回false
if (slavePhyOffset != masterPhyOffset) {
log.error("master pushed offset not equal the max phy offset in slave, SLAVE: "
+ slavePhyOffset + " MASTER: " + masterPhyOffset);
return false;
}
}
//读取完整的body消息
if (diff >= (msgHeaderSize + bodySize)) {
byte[] bodyData = new byte[bodySize];
//byteBufferRead : position -> this.dispatchPostion + msgHeaderSize
this.byteBufferRead.position(this.dispatchPostion + msgHeaderSize);
// 读取bodyData
//after read ,byteBufferRead : position -> this.dispatchPostion + msgHeaderSize + bodySize
this.byteBufferRead.get(bodyData);
//commit 该消息,写到缓存里,定时flush
HAService.this.defaultMessageStore.appendToCommitLog(masterPhyOffset, bodyData);
this.byteBufferRead.position(readSocketPos);
//
this.dispatchPostion += msgHeaderSize + bodySize;
if (!reportSlaveMaxOffsetPlus()) {
return false;
}
continue;
}
}
//position == limit
if (!this.byteBufferRead.hasRemaining()) {
//重新分配 byteBufferRead,这里的作用就是:
//代码走到这里,说明byteBufferRead已满,但dispatchPostion 距离byteBufferRead的limit 即
//(byteBufferRead.limit - dispatchPostion)代表下一条消息所读到的字节(拆包),还没读完整
//然后将该字节重新复用到byteBufferRead;也即此时的
//byteBufferRead.position = byteBufferRead.limit - dispatchPostion;
this.reallocateByteBuffer();
}
break;
}
return true;
}
private void reallocateByteBuffer() {
int remain = READ_MAX_BUFFER_SIZE - this.dispatchPostion;
if (remain > 0) {
this.byteBufferRead.position(this.dispatchPostion);
this.byteBufferBackup.position(0);
this.byteBufferBackup.limit(READ_MAX_BUFFER_SIZE);
this.byteBufferBackup.put(this.byteBufferRead);
}
this.swapByteBuffer();
this.byteBufferRead.position(remain);
this.byteBufferRead.limit(READ_MAX_BUFFER_SIZE);
this.dispatchPostion = 0;
}
简单总结一下,先读取完整的消息头,通过消息头的masterPhyOffset字段以及size字段分别获取master已经同步的给slave的位置以及消息体的大小,接着判断masterPhyOffset以及slavePhyOffset 值是否相等,这等价于一个ack过程,确保slave最后一次写入pagecache的物理位置与master收到slave report offset的值是一致的。
然后在读取完整的消息体;使用dispatchPostion属性来记录一条完整消息的大小,用于解决粘包问题。读完一条消息体后,该消息体包含了一条完整的业务消息字节内容,然后在写入pagecache中;最后在向master report offset。
步骤四分析完。
6、唤醒同步阻塞高可用步骤的producer 发送消息请求
我们接着步骤3 中的HAConnection.this.haService.notifyTransferSome(HAConnection.this.slaveAckOffset)方法:
public void notifyTransferSome(final long offset) {
for (long value = this.push2SlaveMaxOffset.get(); offset > value; ) {
boolean ok = this.push2SlaveMaxOffset.compareAndSet(value, offset);
if (ok) {
this.groupTransferService.notifyTransferSome();
break;
} else {
value = this.push2SlaveMaxOffset.get();
}
}
}
push2SlaveMaxOffset该值就是我们一开始提到的slave集群中向master report offset的最大值,整段逻辑的意思就是当集群中某个slave已同步业务消息的物理位移 大于集群中的任何一个slave时, master就会尝试去唤醒一些阻塞在高可用流程的producer 发送消息请求。使用cms + 自旋的方式来保证并发。
我们接着进入
this.groupTransferService.notifyTransferSome()
public void notifyTransferSome() {
this.notifyTransferObject.wakeup();
}
该方法唤醒的是GroupTransferService该业务线程,他是实现producer 发送消息请求 同步等待高可用流程的一个
业务类,因此,我们可以直接看run()方法:
public void run() {
while (!this.isStopped()) {
....
this.waitForRunning(10);
this.doWaitTransfer();
...
}
}
notifyTransferObject.wakeup()主要是唤醒等待在this.waitForRunning(10)的GroupTransferService业务线程。
我们直接着分析
this.doWaitTransfer()
private void doWaitTransfer() {
if (!this.requestsRead.isEmpty()) {
for (CommitLog.GroupCommitRequest req : this.requestsRead) {
boolean transferOK = HAService.this.push2SlaveMaxOffset.get() >= req.getNextOffset();
for (int i = 0; !transferOK && i < 5; i++) {
this.notifyTransferObject.waitForRunning(1000);
transferOK = HAService.this.push2SlaveMaxOffset.get() >= req.getNextOffset();
}
if (!transferOK) {
log.warn("transfer messsage to slave timeout, " + req.getNextOffset());
}
req.wakeupCustomer(transferOK);
}
this.requestsRead.clear();
}
}
//使用countDownLatch唤醒
public void wakeupCustomer(final boolean flushOK) {
this.flushOK = flushOK;
this.countDownLatch.countDown();
}
总结一下,遍历requestsRead请求队列,该队列存放着全部的producer 发送消息请求,逐个取出请求,在通过HAService.this.push2SlaveMaxOffset.get() >= req.getNextOffset()判断来决定是否唤醒该请求;该判断的意思就是,slave集群中,只要有一个slave同步的最大物理位移 大于 该请求的写入master pagecache中的物理位移,即可唤醒该请求。而且,每一个请求最多只等待5次,每次最多等待1秒,换句话说,如果一个producer 发送消息请求 等待的界限超过了上述条件,仍然会继续唤醒该请求。
而阻塞在高可用的请求处,可以看 《rocket mq 底层存储源码分析(2)-消息内容持久化》该章节的步骤5。
最后在说一下,如果在master 向slave 同步消息字节时,有可能这些字节内容包含了完整消息的一部分,也就是slave将这些只包含部分内容的消息字节写入到pagecache中,此时,消息的【逻辑位移索引】构建业务类ReputMessageService会进行容错处理,即ReputMessageService只会为完整的消息构建逻辑位移,如果读取到一条不完整的消息时,ReputMessageService会等待,直到写入pagecache的消息完整后 ,才继续滚动构建。
以上就是rmq 高可用的具体实现。