地域信息说明
在上一个练习里可以看到身份证的地域信息是 450403. 这个编号是什么意思呢? 其实是国家规定的一个编号, 在国家统计局网站上有啦. 看看我的这个截图:
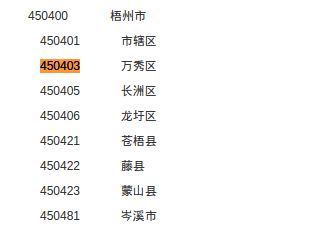
所以呢, 450403 表示是梧州市的人. :-) 网址在这里, 你可以看到完整的地址信息:地址信息
那么其实地域信息很容易得知. 只要截出身份证的前6位, 然后到这个网站一查, bingo! 我就知道你是哪里出生的人了. 但是等等... 这不很傻? 如果我要查 100个人的信息, 我要查100次?
当然不是了. 程序最大的作用之一就是解决自动化的问题. 我们可以这样做: 把所有地址信息存下来, 需要查找地域信息的时候, 在这堆地址信息里让程序自动查找即可.
网站的常识
动手之前, 我们先来了解一点网站/浏览器的常识. 网站是放在有公开域名的电脑上(通常把这个电脑叫做服务器) 的一段程序而已. 这段程序用html/css/js 和动态技术(python/php/java/c# ... ) 来编写, 最终的体现形态是 html/css/js. 当你的浏览器打开一个网站的时候, 其实是向该网站发起一个请求, 然后这个网站便将 html/css/js 一股脑扔到你的电脑.
(上述流程介绍涉及 html 和 http 网络协议的基础知识, 如果你不了解, 要先去补补课)
我们以上述的国家统计局信息为例. 它的地址是http://www.stats.gov.cn/tjsj/tjbz/xzqhdm/201703/t20170310_1471429.html , 打开之后浏览器显示是这样的:
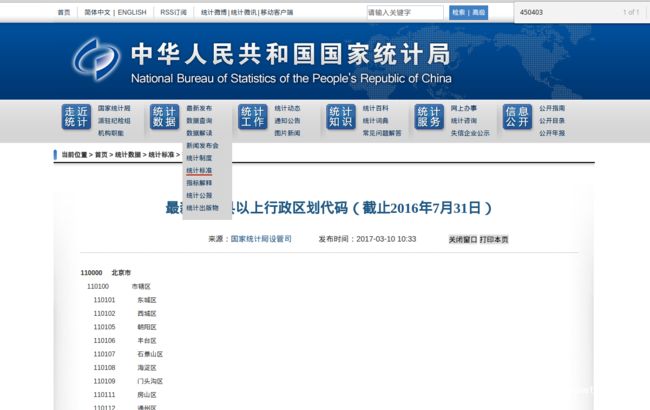
现在, 你点击鼠标右键, 选择查看网站的源码, 你会看到一大堆这样的代码:
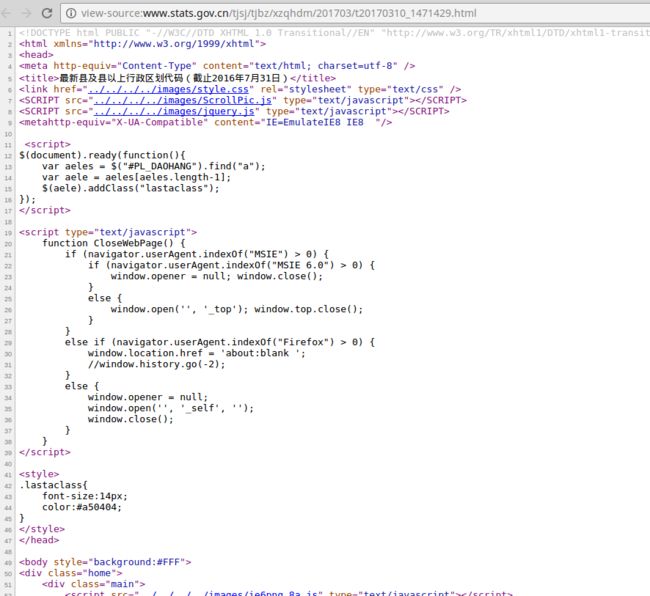
这就是服务器给你返回的真实的东西. 这个真实的东西叫做 html/css/js . 你在浏览器看这堆东西整整齐齐, 那是因为浏览器帮你做好了格式化的工作而已.
明白了这个原理之后, 分析身份证的地域可以按照这个思路进行:
1. 把国家统计局网址返回的信息都手动保存到文件里.
2. 查看html的规律, 看看地域信息隐藏在哪里. 按照截图, 肯定是编码 中文的比对形式.
3. 找到地域信息之后, 将编码对应的中文找出来, 就得到地域信息了.
动手操作
手动保存地域信息
1. 在浏览器打开国家统计局的网站, 然后选择鼠标右键, 查看源代码, 然后全选, 复制.
2. 新建1个 address.html 文件, 将第1步的信息都保存到这个文件里.
查找规律
我是chrome浏览器, 不过其他浏览器操作差不多. 都有 查看网页结构的功能. 点鼠标右键, 如下图:
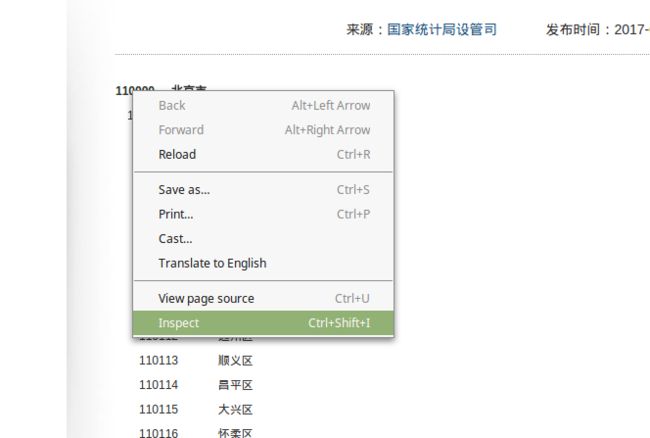
然后你会看到弹出一个窗口, 如下:
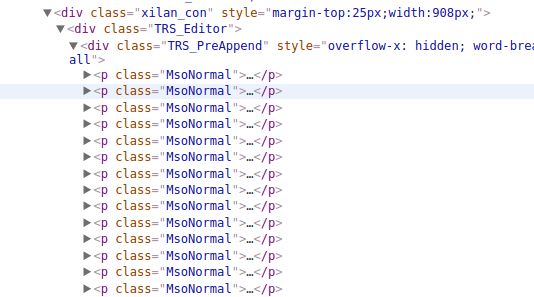
这里需要一点html/css的知识. 上图表示, 地址信息都保存在
标签里. 而 这个特定的p标签的 css样式(class) 是 MsoNormal . 依次展开p标签, 查找规律如下:
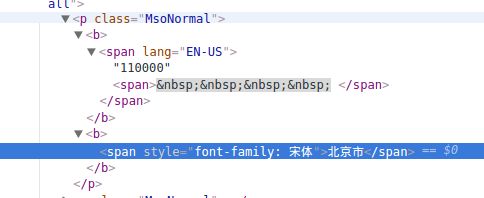

这给你什么启发呢? 慢慢地你会发现: 先找到1个class是 MsoNormal的p标签. 它下面又有3个span 子标签, 而第2个span包含编码, 第3个span包含中文. 这就是规律啦. 如果找不到, 继续试试.
使用 BeautifulSoup4
找到规律之后, 我们就要用程序来帮我们做. 任何语言都有分析字符串的正则表达式框架. 但如果你去看看正则表达式的用发, 估计会吓到初学者的你. 一大堆字符究竟是什么意思? 幸运的是你还有其他选择. 既然总说人生苦短我用python, 肯定是因为它有更方便易用的东西.
这个东东就是 BeautifulSoup4, 方便在字符串里进行格式化和查找结果的类库. 我们要先把他们装上. 打开命令行, 运行如下命令:
pip install BeautifulSoup4
然后你会看到一大坨字符. 只要你装好了Python, 能上网, 这个安装是不会出什么问题的.
先来看看基本用法:

7行: 引入包
12行: 打开刚才保存的文本. 注意这个文本和程序要在同一目录.
14行: bs4的用法, 死记硬背即可.
15行: 小试牛刀的一个用法. 你会看到控制台打印出整整齐齐的字符串. prettify 的意思就是美化输出.
如下图:
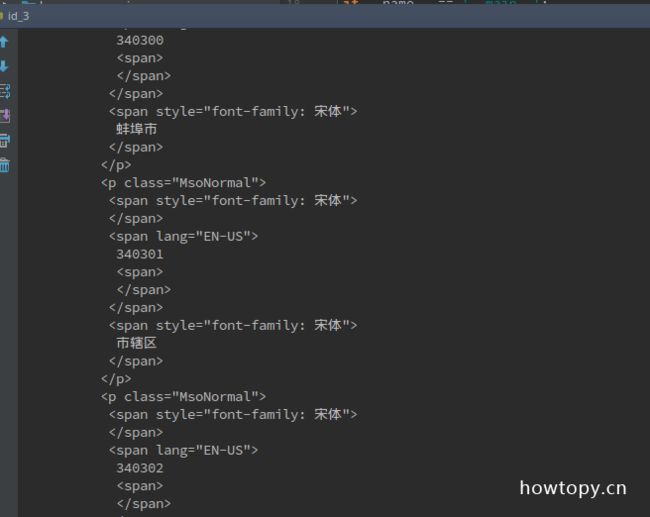
(你会发现美化输出之后, 更容易发现地域规律了. )
查找显示地域信息
用bs4查找信息很方便, 如下程序:
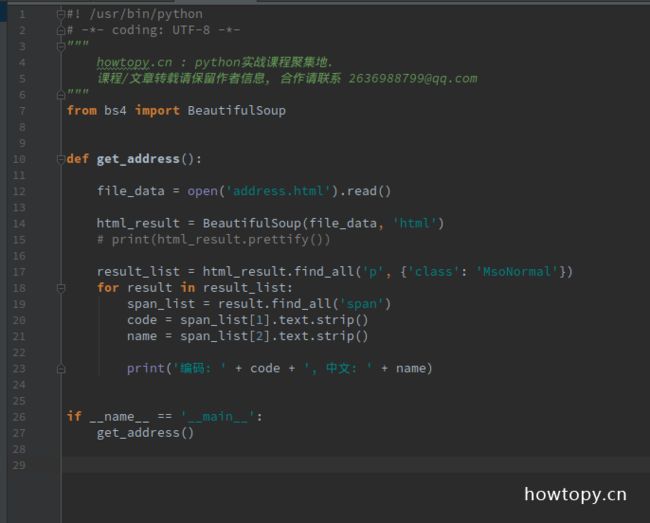
17行: find_all 意思是在字符串里查找p标签, 这个标签的特征是css类名是 MsoNormal , 最终返回所有包含此标签的list
18行: 遍历返回的list
19行: 每个p标签内部又有span标签, 所以在这里继续用find_all查找所有span标签.
20-21行: 如前分析, 第2个span包含编码, 第3个包含中文.
好吧, 我们来看看显示的结果, 如下:

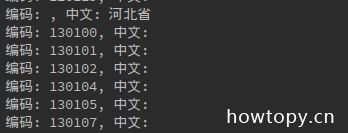

你发现了什么? 像省市是可以找出来的, 但是他们没有编码. 编码正确的, 又没有中文. 这表示: 我们之前的分析规律有问题. 要重新进行分析.
重新分析规律
过程我就不赘述了你一定要自己动手试一试. 真正的规律其实是:
1. 如果是省/直辖市, 那么p标签之下是2个b标签. b标签里又有span标签. 编码和中文藏在span里.
2. 如果是某个区, 规律如之前分析. 编码和中文分别藏在第2个和第4个span里.
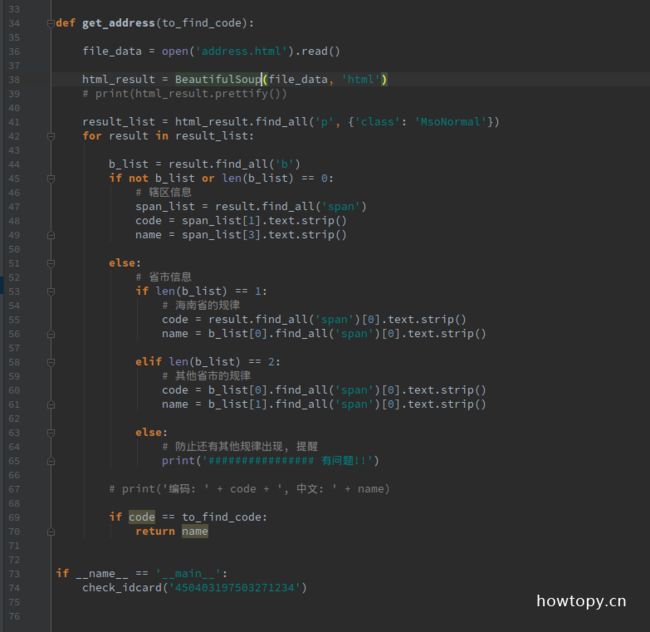
所以重新实现程序如下:

20行: 优先找b元素.
21行: 通过是否有b元素决定用那种规律来查找信息.
23-30行: 两种策略的实现.
好了, 运行程序, 然后你观察输出, 会看到....
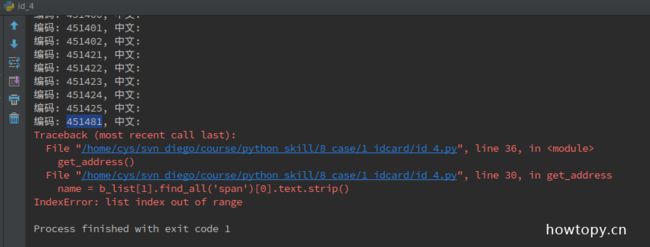
WTF .... 程序在 451481 的下一条出错了. 这说明这个规律仍然有问题. 在网站上找到 451481, 看看下一个编码是啥, 会看到:

右键查看规律, 你会看到:

在海南省这里出现了一个新的规律!! span包含编码, b标签只有1个, 包含中文. 知道这个就好办了, 修改程序如下:
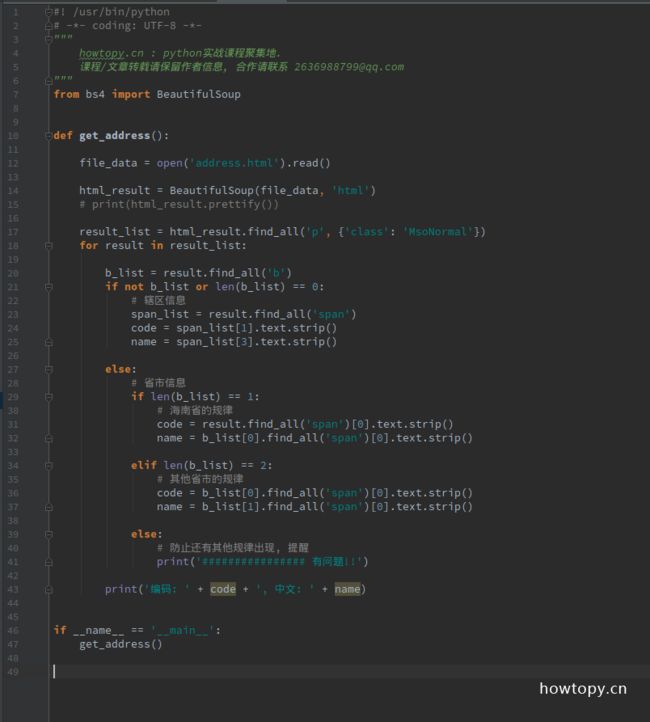
29-41行: 为海南省增加了一个特例判断. 同时在40行打印字符串, 如果还有其他规律的时候, 可以在控制台发现.
运行程序并查看结果如下:
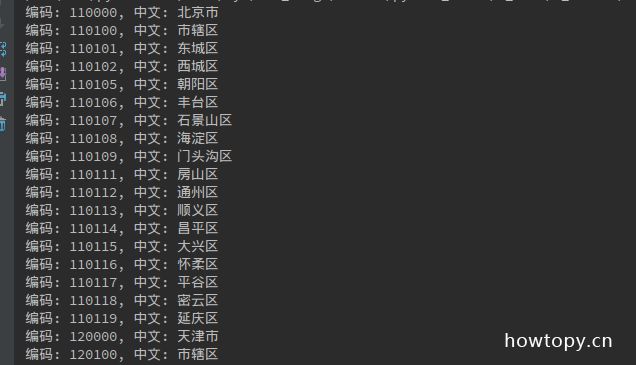
这次终于全部正确了.
检测地域信息
把上面的这段程序复制到身份证检测的程序, 对身份信息进行检测. 完整程序如下:
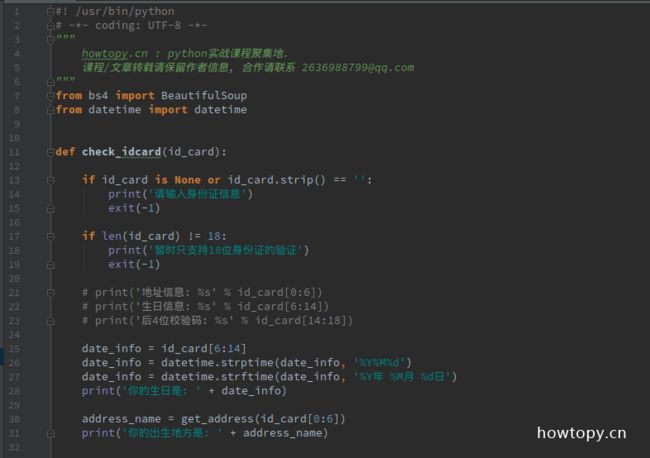
程序修改了一下. get_address 增加了一个参数. 如果找到的code和这个参数匹配, 就返回相应的名字.
运行这个程序, 应该可以看到结果如下:
结论
这个程序对你有什么启发?
编程是一个手工活, 不是一开始想好什么写什么(高大上的词叫做设计) , 结果就是什么. 而是经历 想法 -> 代码实现 -> 观察结果 -> 调整想法 -> 调整代码... 这样的循环, 最后得到正确的程序.
现在已经可以显示身份证的地域信息了. 但是并不完美. 比如中文只是显示辖区名字, 没有省市, 所以我们还要想办法实现省市的查找. 下一章我们来做这个工作.