前面几篇文章我们介绍了有关struts2的基本内容,简单理解了整个框架的运作流程。从本篇开始我们逐渐了解和使用struts2为我们提供的标签库技术,使用这些标签可以大大降低我们表现层的开发难度。根据这些标签的使用途径可以初步划分为以下三大类:
- UI标签:主要用于生成HTML标签元素
- 非UI标签:主要用获取后台数据,简单的逻辑控制等
- Ajax标签:用作js请求
对于UI标签我们又大致可以分为两类,表单标签和非表单标签。对于非UI标签我们也是可以分为两类,流程控制标签和数据访问标签。本篇文章首先来介绍流程控制标签的使用情况。
一、Struts2中OGNL表达式语言的使用
在介绍标签库技术之前,我们需要先简单了解下有关OGNL表达式语言的一些相关知识,因为在我们的标签库使用中无时不涉及到对OGNL表达式的使用。OGNL表达式和JSP中的EL很是类似,都是用于取数据的,只是OGNL配合着Struts2标签库可以实现更加强大的功能。下面我们简单了解下OGNL的使用:
每当我们在地址栏请求一个Action的时候,我们的核心拦截器会迅速创建一个ActionContext上下文,Action实例还有一个ValueStack(值栈)。这个值栈的内部结构是:
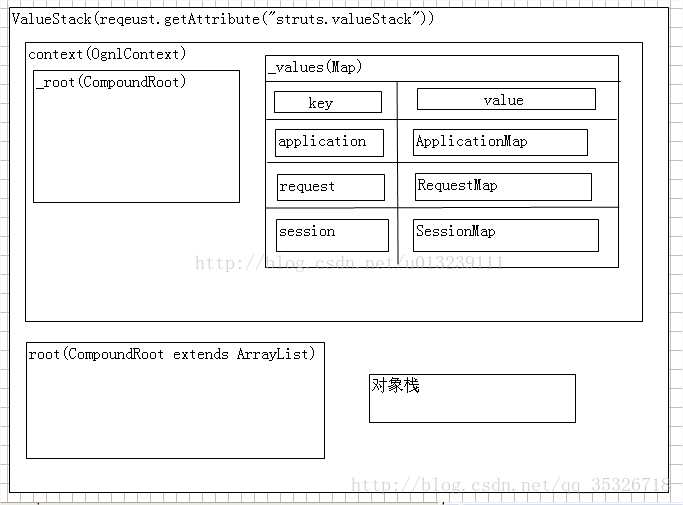
主要有两部分组成,一个context(OgnlContext),实际上就是一个map结构,一个是root(实际上是ArrayList),我们叫他根栈。在context中有两部分组成,一个是Map结构的 _values,一个是 _root(和root是一样的,这里是将root映射到context中了)。所以我们一般只需要操作这个context就可以完成对值栈的操作了。由此我们可以知道我们要使用的OGNL的上下文(ValueStack)主要有两部分组成:
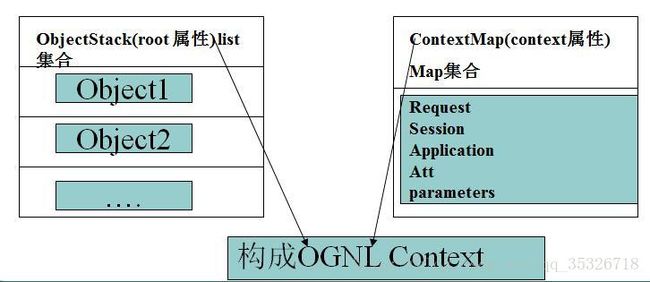
在我们框架中,ActionContext中有两个重要的属性:
public static final String VALUE_STACK = "com.opensymphony.xwork2.util.ValueStack.ValueStack";
private Map context;
所以我们一般认为ActionContext就是OGNL上下文,其中的context就是ValueStack中的contextMap,这里的VALUE_STACK 其实是一个完整的ValueStack对象,但是我们一般只操作他的root属性。由上述两者构成了OGNL的上下文。当我们使用OGNL表达式语言的时候,就会到这个上下文中查找数据。其中访问根栈中数据(root)是不需要使用#的,但是contextMap中的数据访问时是需要前缀#的,具体的下文介绍。
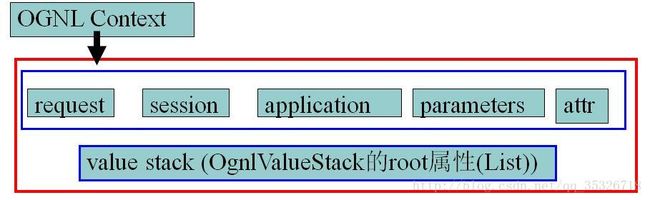
在初次加载Action实例的时候会默认将如下的一些对象添加到上述的contextMap中:
- parameters: 该 Map 中包含当前请求的请求参数
- request: 该 Map 中包含当前 request 对象中的所有属性
- session: 该 Map 中包含当前 session 对象中的所有属性
- application:该 Map 中包含当前 application 对象中的所有属性
- attr: 该 Map 按如下顺序来检索某个属性: request, session, application
有关OGNL上下文的基本结构就简单介绍到这,稍微小结一下,OGNL的上下文主要有两部分组成,一个是跟栈(root),一个是contextMap(这里面默认会添加一些对象,访问其中内容的时候是需要使用#),每个request请求会对应创建一个ValueStack,不是每个Action实例对应一个ValueStack,如果Action中redirect别的Action或者资源的时候,这个ValueStack就会被销毁,其中有关上此Action的一些信息会全部丢失。具体的ognl语法此处并没有直接介绍,这些语法将会贯穿着在介绍标签使用情况的时候详细说明。
二、基本控制标签
基本控制标签主要有8个,它们是:
- property获取属性标签
- if/else/else if逻辑判断标签
- iterator迭代标签
- append组合集合标签
- generator拆分字符串标签
- merge组合集合标签(处理方式和append不一样)
- subset获取子集合标签
- sort排序标签
1、property获取属性值标签
在使用struts标签库之前我们需要在jsp页面引入该标签库:
<%@ taglib prefix="s" uri="/struts-tags" %>
.....
该标签主要有三个属性,value属性指定需要输出的对象的属性名称,如果没有指定将取ValueStack(root)栈顶元素。default指定该标签的默认值,也就是在获取指定属性值为空的时候默认输出的值。escape属性指定是否格式化为html代码(很少使用)。下面看几个实例:
public class LoginAction extends ActionSupport {
public String execute() throws Exception{
//向context中添加一个map键值对
ActionContext.getContext().put("hello","walker");
return SUCCESS;
}
}
this is the index page

value属性中的内容就是一个ognl表达式,我们之前说过ValueStack中的context中数据的访问是需要使用#,相反如果是root中的属性则不需要使用#。我们点开debug,看到:
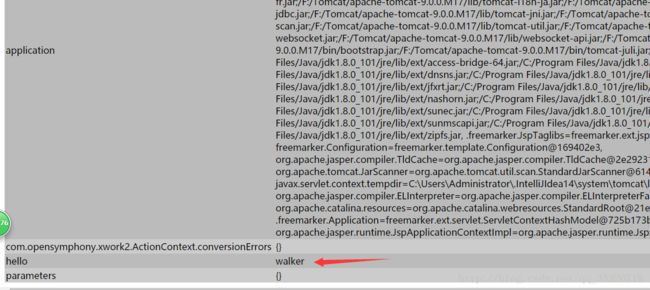
刚刚put的键值对是被存放在了context这个map中的,也看到了其中默认被添加的一些对象,如request,application,parameters等。需要记住的是访问这个context的ognl表达式需要使用 #前缀。
2、if/else if/else逻辑判断标签
这几个标签其实含义和我们Java SE中的if/else 差不多,只是用标签的形式在HTML页面使用了。if标签主要有一个test属性,这个属性的值是一个boolean类型的,该标签也就是根据这个值判断是否输出其中内容。具体看一个例子:
this is the index page
walker
基本用法还是和JavaSE差不多,只是形式不一样。至于else标签一定得和if标签组合在一起使用。至于内部源码是如何实现这个标签的,还未参透,望谅解。
3、iterator迭代标签
iterator标签主要用于对一个给定的集合实行遍历输出操作,主要包含以下几个属性:
- value:指定将要被迭代的集合,如果没有取栈顶元素
- id:指定当前正在遍历的元素的标识
- status:该属性为IteratorStatus实例,主要用于判断当前迭代的元素的属性
public class LoginAction extends ActionSupport {
public String execute() throws Exception{
ArrayList list = new ArrayList();
list.add("walker");
list.add("yam");
list.add("aaa");
list.add("bbb");
ActionContext.getContext().put("name",list);
return SUCCESS;
}
}
this is the index page
我们在Action中向context中存入一个ArrayList,jsp页面通过调用iterator标签实现遍历操作,id属性指定了当前遍历元素。结果如下:
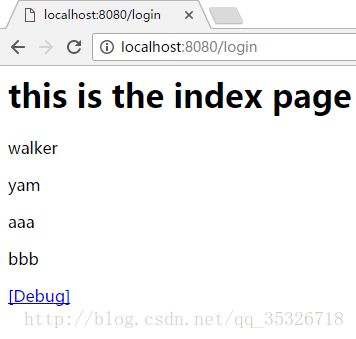
当然有人说,我如果不想遍历后台的集合而是在jsp页面自定义一个集合然后遍历输出该怎么办呢?这里就要涉及到ognl表达式的一种定义集合的语法了。看例子:
this is the index page
ognl支持使用{......},构建一个list集合,使用#{name2:value1,name2:value2}构建map集合。上述代码运行结果如下:
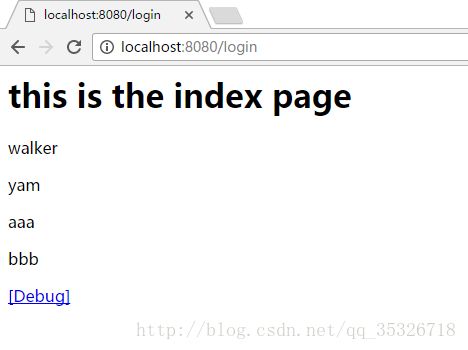
我们打开debug可以看到:

在context中保存了一个键值对n=bbb,这说明这种方式的迭代是通过将当前遍历的元素添加到context中然后通过property标签立即取出来实现的,所以这里保存了最后一个键值对,前面的都被覆盖掉了。
4、append合并集合标签
我们往往在页面上会得到两个或两个以上的集合,我们有时希望能够合并他们然后一起迭代输出。这里就需要用到我们的append标签。append标签只需要指定一个属性var即可,该属性表示拼接之后生成的新集合的名称,就版本用的是id,但是已经不推荐使用了。该标签还需要配合param标签一起使用,param标签指定的就是一个子集合,具有的value属性用于指定该子集合的内容也是个ognl表达式。例如:
this is the index page
输出结果:
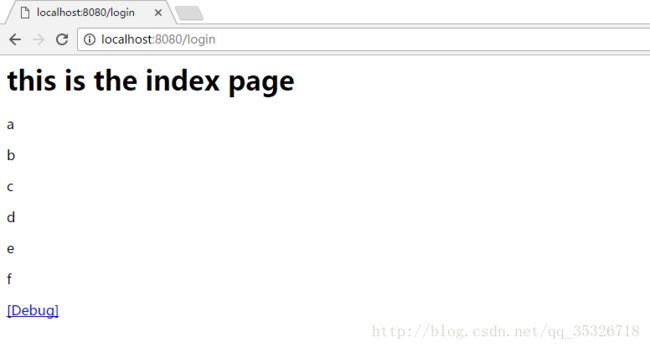
这里我们为新集合命名为mylist,我们进debug看到:

我们的新集合被存入context中,所以我们上述使用的iterator标签在遍历新集合的时候是使用#访问的,当然除了list,我们一样可以合并map,但是在遍历map的时候可以使用如下两条语句分别访问key和value。
5、generator分割字符串标签
这个标签的功能和String的split方法是类似的。用于将指定的字符串根据某种字符进行分割,返回的是一个集合。该标签提供如下几个属性:
- count:该属性指定了返回的集合中包含的元素个数,超过该值的元素将被舍弃
- separator:该属性指定了用于分割字符串的字符
- val:该属性指定了将要被分割的字符串
- var:该属性指定了保存在context中的名字,如果没有指定该属性将不会保存在context中
this is the index page
上述代码中我们使用generator标签将字符串“walker,yam,c,y,y”作为参数传入val属性中,并指定拆分结果保存到context中,然后我们遍历了这个集合结果如下:
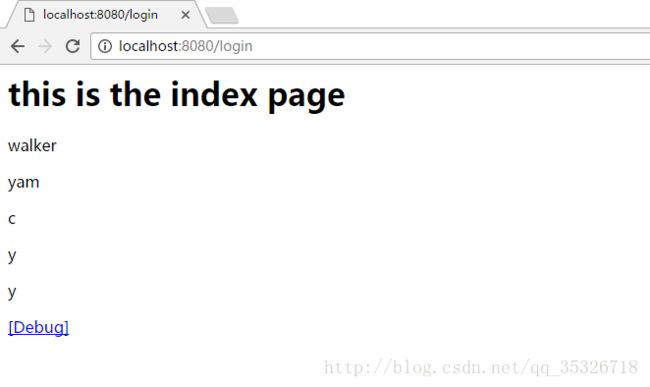
还有一个细节需要注意下,在generator标签开始的时候会将分割结果保存在root中,标签结束的时候会从root中移除。例如:
this is the index page
//标签开始
//标签结束
我们看到在使用generator标签的时候并没有指定它保存到context中,并且在使用iterator标签的时候也没有指定需要遍历的集合,自然从root栈顶获取一个元素遍历,这个集合就是generator标签开始时将结果压入的集合,亲测正确。告诉我们的是,在generator标签中结果集合是被压入栈顶的,可以不用#来访问。
6、merge标签拼接集合
之前已经介绍过了,该标签和append标签的区别在于他们拼接的方式不一样,append是将后一个集合添加到前一个的尾部,而merge不一样。我们看个例子:
this is the index page
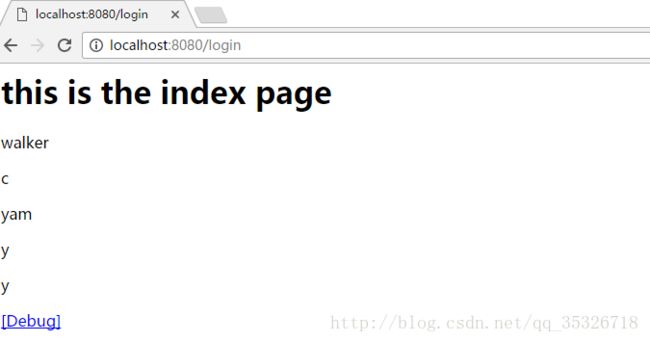
拼接方式不同,其他没什么不同。此处不再赘述。
7、subset获取子集标签
该标签主要用于对某个集合中的元素进行筛选过滤,获取子集的作用。它主要有如下属性:
- count:该属性指定了返回的集合中包含的元素个数,超过该值的元素将被舍弃
- source:指定将要被获取子集的集合
- start:指定了操作从某个索引位置开始
- decider:指定获取的方式,可以自定义
- var:如果指定该属性,会将结果保存在page范围内,和之前有所区别
和generator一样,在标签中会将结果集合保存在root栈顶,在标签尾部会从栈顶移除该集合。例如:
this is the index page
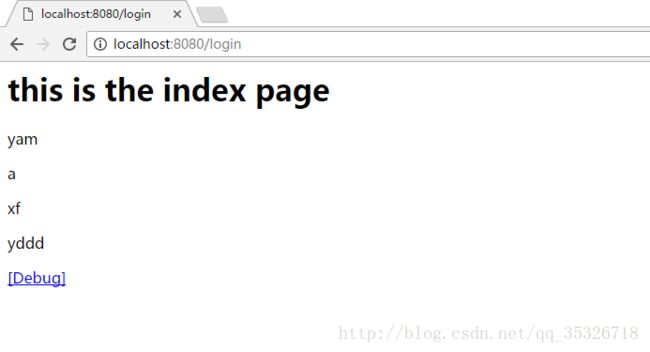
上述代码并没有提供decider,所以对其中的每一个元素并没有做任何的过滤。下面我们自定义一个decider实现我们自己的过滤集合操作。
//自定义decider继承SubsetIteratorFilter.Decider
public class MyDecider implements org.apache.struts2.util.SubsetIteratorFilter.Decider {
public boolean decide(Object el) throws Exception{
String s = (String)el;
return s.length()>3;
}
}
this is the index page
//使用bean标签创建类的实例并保存到context中
输出结果如下:
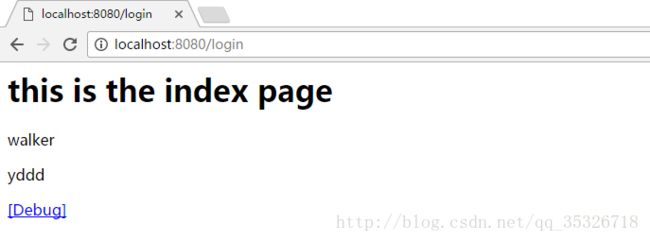
将集合中所有长度大于三的元素抽取出来,并输出。
8、sort排序标签
最后我们看看排序标签,该标签具有以下属性:
- conparator:该属性指定了排序规则
- source:原集合
- var:是否保存到page范围内中,不是放在context中,和之前的有所不同
和之前的generator,subset一样,标签的开始会将结果存放到栈顶,结束时或移除。对于排序规则,我们只需要自定义一个类继承java.util.Conparator即可。看例子:
this is the index page
//加载实例,保存到context中
输出结果如下:
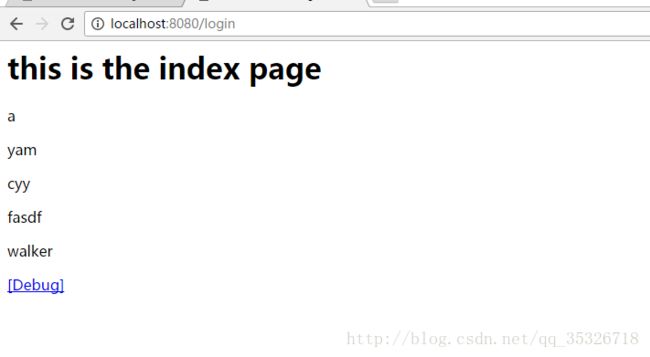
输出结果是符合我们自定义的比较规则的。
有关struts2的控制标签部分就简单介绍到这,如有错误,望不吝赐教!