Rasa 入门教程 NLU 系列包括六个部分,前面介绍了Rasa 入门教程 NLU 系列(二),本文主要介绍 Rasa 框架中的 NLU 系列中的第三部分:选择一个 pipeline。选择 NLU pipeline 可以让你自定义模型并在数据集上进行微调。
本文的目录结构:
- 短回答
- 长回答
- 类别不平衡
- 多意图
- 理解 Rasa NLU Pipeline
- 组件的生命周期
- 返回实体字典说明
- 预配置 Pipelines
- 自定义 Pipelines
1. 短回答
如果你的训练数据集少于 1000,可以使用语言模型 spaCy,使用 pretraine_embeddings_spacy 作为 pipeline:
language: "en"
pipeline: "pretrained_embeddings_spacy"
如果你的训练数据集有 1000 或更多带有标签的数据,使用 supervised_embeddings 作为 pipeline:
language: "en"
pipeline: "supervised_embeddings"
2. 长回答
最重要的两个 pipeline 是:supervised_embeddings 和 pretrained_embeddings_spacy。它们之间最大的区别是:pretrained_embeddings_spacy pipeline 是来自 GloVe 或 fastText 的预训练词向量;supervised_embeddings pipeline 不使用任何预先训练的词向量,是为了你的训练集而用的。
2.1 pretrained_embeddings_spacy
pretrained_embeddings_spacy pipeline 的优势在于,当你有一个训练示例,比如:“我想买苹果”,并且要求 Rasa 预测“买梨”的意图,那么你的模型已经知道“苹果”和“梨子”这两个词非常相似,如果你没有太多的训练数据,这将很有用。
2.2 supervised_embeddings
supervised_embeddings pipeline 的优势在于,针对你的 domain 自定义词向量。例如:在英语中单词 "balance" 与 "symmetry" 密切相关,但是与单词 "cash" 有很大不同。在银行领域,"balance" 与 "cash" 密切相关,你希望你的模型能够做到这一点。该 pipeline 不使用特定语言模型,因此它可以与任何你分好词(空格分词或自定义分词)的语言一起使用。
2.3 MITIE
你可以在 pipeline 中使用 MITIE 作为词向量的来源,请参考 MITIE。MITIE 后端对于小数据集表现良好,但如果你有数百个以上的示例,训练时间可能会花费很长时间。我们不建议你使用它,因为在将来的版本中可能不再支持 MITIE。
2.4 比较不同的 pipelines
Rasa 提供了直接比较在不同 pipelines 上数据的性能工具,详情请参考比较 NLU pipelines。
3. 类别不平衡
如果存在很大的类别不平衡,例如:你有很多针对某些意图的训练数据,但是其他意图的训练数据很少,通常情况下分类算法表现不佳。为了缓解这个问题,rasa 的 supervised_embeddings pipeline 使用了 balanced 批处理策略。
该算法确保在每一批次中或至少在尽可能多的后续批次中,代表所有类别,模仿某些类别比其他类别更频繁的事实。默认情况下是使用 balanced 平衡批处理策略。如果你想使用其他的经典批处理策略,在你的配置文件中添加该策略,比如:batch_strategy: sequence。
language: "en"
pipeline:
- name: "CountVectorsFeaturizer"
- name: "EmbeddingIntentClassifier"
batch_strategy: sequence
4. 多意图
如果你要将意图拆分为多个标签,比如用于预测多个意图或者建模分层意图结构,那么只能使用有监督的嵌入 pipeline 来执行此操作。因此,需要使用这些标识:WhitespaceTokenizer:
-
intent_split_symbol:设置分隔符字符串以拆分意图标签,默认_。
这里是关于如何在 Rasa Core 和 NLU 中使用多个意图的教程。以下是一个配置示例:
language: "en"
pipeline:
- name: "WhitespaceTokenizer"
intent_split_symbol: "_"
- name: "CountVectorsFeaturizer"
- name: "EmbeddingIntentClassifier"
5. 理解 Rasa NLU Pipeline
在 Rasa NLU 中,传入消息后是由一系列组件进行处理。这些组件在所谓的处理 pipelines 中一个接一个地执行。有用于实体提取、意图分类、响应选择、预处理等组件,如果要添加自己的组件,比如:进行拼写检查或情感分析,请参考自定义 NLU 组件部分。
每个组件都处理输入并新建输出,输出可以由 pipelines 中该组件之后的任何组件使用。有一些组件仅仅生成信息给其他组件使用,还有一些组件会生成 Output 属性,这些属性将在处理完成后返回。比如:对于 I am looking for Chinese food 这句话的输出是:
{
"text": "I am looking for Chinese food",
"entities": [
{"start": 8, "end": 15, "value": "chinese", "entity": "cuisine", "extractor": "CRFEntityExtractor", "confidence": 0.864}
],
"intent": {"confidence": 0.6485910906220309, "name": "restaurant_search"},
"intent_ranking": [
{"confidence": 0.6485910906220309, "name": "restaurant_search"},
{"confidence": 0.1416153159565678, "name": "affirm"}
]
}
这是预配置 pretrained_embeddings_spacy pipeline 中不同组件的结果组合。比如:entities 属性是由 CRFEntityExtractor 组件创建的。
6. 组件的生命周期
每个组件都可以实现基类 Component 中的几种方法,在 pipeline 中,将按照特定顺序调用这些不同的方法,让我们假设,我们将以下 pipeline 添加到我们的配置中:"pipeline": ["Component A", "Component B", "Last Component"] 。下图显示了在训练此 pipeline 中的调用顺序。
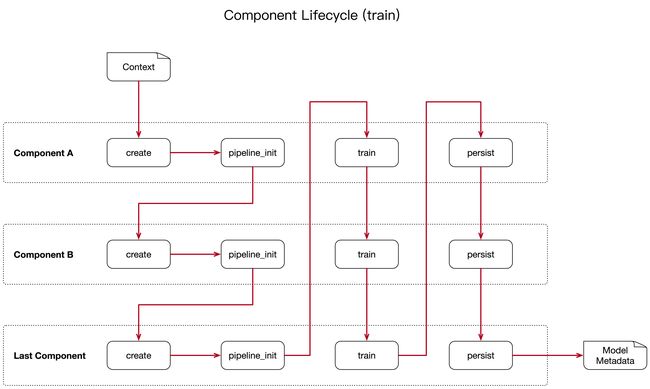
在使用 create 函数之前,会创建一个 context 上下文,此上下文用于组件之间传递信息。例如:一个组件可以计算训练数据的特征向量,将其存储在上下文中,另一个组件可以从这个上下文中检索这些特征向量用于意图分类。
使用配置填充来初始化上下文,图片中的箭头表示了调用顺序,并可视化了传递上下文的路径。当所有组件训练并持久化之后,最终的上下文字典将被用来持久化模型的元数据。
7. 返回实体字典说明
解析完后,该实体以字典形式返回。有两个字段显示 pipeline 如何影响实体的返回信息:extractor 字段告诉你哪个实体提取器提取了该特定实体,processors 字段告诉你更改了该特定实体的组件名。
使用同义词会导致 value 字段与 text 不完全匹配的情况,它将返回经过训练的同义词。
{
"text": "show me chinese restaurants",
"intent": "restaurant_search",
"entities": [
{
"start": 8,
"end": 15,
"value": "chinese",
"entity": "cuisine",
"extractor": "CRFEntityExtractor",
"confidence": 0.854,
"processors": []
}
]
}
8. 预配置 Pipelines
模板是完整组件列表的一个快捷方式,比如:以下两个配置是等价的:
language: "en"
pipeline: "pretrained_embeddings_spacy"
language: "en"
pipeline:
- name: "SpacyNLP"
- name: "SpacyTokenizer"
- name: "SpacyFeaturizer"
- name: "RegexFeaturizer"
- name: "CRFEntityExtractor"
- name: "EntitySynonymMapper"
- name: "SklearnIntentClassifier"
以上是所有自定义预配置 pipelines 模板的列表。
8.1 supervised_embeddings
在 config.yml 配置文件中定义 supervised_embeddings pipeline,来训练你的 Rasa 模型,定义方式如下:
language: "en"
pipeline: "supervised_embeddings"
该 supervised_embeddings pipeline 可以支持任何语言。默认情况下,它以空格进行分词。你可以通过添加或更改组件来自定义该 pipeline 的设置。以下是构成 supervised_embeddings pipeline 的默认配置:
language: "en"
pipeline:
- name: "WhitespaceTokenizer"
- name: "RegexFeaturizer"
- name: "CRFEntityExtractor"
- name: "EntitySynonymMapper"
- name: "CountVectorsFeaturizer"
- name: "CountVectorsFeaturizer"
analyzer: "char_wb"
min_ngram: 1
max_ngram: 4
- name: "EmbeddingIntentClassifier"
如果你的语言没有空格分隔,比如汉语,你可以将 WhitespaceTokenizer 换成你自己的分词器。我们支持许多不同的分词器,比如:Jieba 分词,或者你也可以创建自己的分词器,详见请参考Rasa 入门教程 NLU 系列(六)。
上面示例中的 pipeline 使用了两个实例 CountVectorsFeaturizer 。第一个用于单词的文本特征化,第二个基于字符 n-grams 对文本进行特征化处理,保留词边界。通过经验发现,第二个功能很强大,但我们决定也保留第一个强大的功能。
8.2 pretrained_embeddings_spacy
pretrained_embeddings_spacy pipeline 的模板如下:
language: "en"
pipeline: "pretrained_embeddings_spacy"
有关加载 spacy 语言模型更多的信息,请参考预训练词向量。配置信息如下:
language: "en"
pipeline:
- name: "SpacyNLP"
- name: "SpacyTokenizer"
- name: "SpacyFeaturizer"
- name: "RegexFeaturizer"
- name: "CRFEntityExtractor"
- name: "EntitySynonymMapper"
- name: "SklearnIntentClassifier"
8.3 MITIE
使用 MITIE pipeline,需要从语料库中训练词向量。相关介绍可以再这里查看。model 参数用来传入文件路径。
language: "en"
pipeline:
- name: "MitieNLP"
model: "data/total_word_feature_extractor.dat"
- name: "MitieTokenizer"
- name: "MitieEntityExtractor"
- name: "EntitySynonymMapper"
- name: "RegexFeaturizer"
- name: "MitieFeaturizer"
- name: "SklearnIntentClassifier"
该 pipeline 的另一个版本是使用 MITIE 的特征器和多类分类器。该版本的训练可能很慢,所以不建议用于大型数据集上。
language: "en"
pipeline:
- name: "MitieNLP"
model: "data/total_word_feature_extractor.dat"
- name: "MitieTokenizer"
- name: "MitieEntityExtractor"
- name: "EntitySynonymMapper"
- name: "RegexFeaturizer"
- name: "MitieIntentClassifier"
9. 自定义 Pipelines
你可以选择不使用模板,你可以通过列出要使用的组件名称来自定义自己的 pipeline。
pipeline:
- name: "SpacyNLP"
- name: "CRFEntityExtractor"
- name: "EntitySynonymMapper"
这将创建仅仅用于实体识别的 pipeline,不用于意图分类。因此,Rasa NLU 不会预测任何意图,你可以在Rasa 入门教程 NLU 系列(六)找到每个组件的详细信息。
如果你想要在 pipeline 中自定义组件,请参阅自定义 NLU 组件部分。
作者:关于我
备注:转载请注明出处。
如发现错误,欢迎留言指正。