问题
在学习 Java Stream 的过程中遇到了一段代码:
int sum = IntStream.range(1, 20)
.peek(n -> System.out.print(n + "\t"))
.skip(5)
.limit(5)
.sum();
System.out.println();
System.out.println("sum is :" + sum);
运行结果:
1 2 3 4 5 6 7 8 9 10
sum is :40
改为并行流:
int sum = IntStream.range(1, 20)
.parallel()
.peek(n -> System.out.print(n + "\t"))
.skip(5)
.limit(5)
.sum();
System.out.println();
System.out.println("sum is :" + sum);
原本以为被打印出来的数字应该是无序的 1~10 的数字排列,但运行结果出乎我的意料:每次都是只打印 5~10 这6个数字,却没有打印 1~4。运行结果如下:
7 9 5 10 8 6
sum is :40
就算是 JDK 做了优化,那为何不是跳过前 5 个数字,只打印 5 个数字,而是打印了 6 个数字?
后来又发现更加奇怪的现象,将 skip 由 5 改为 8 ,每次都能打印 1~13 全部数字:
12 11 13 1 10 2 3 4 5 6 7 8 9
sum is :55
skip 改为7,每次则只打印8~12这5个数字,跳过了 1~7 这7个数字:
8 9 11 10 12
sum is :50
这三次 skip 参数的变动,打印出来的结果截然不同,也没有看出什么规律,那就只能从源码中找答案。
原因
流与操作
在上面那段代码中,我们一共会遇到3种类型的流(Head、StatelessOp、StatefulOp)及1种终止操作(ReduceOp)。
- range(...)是一个创建流的动作,创建了一个Head类型(IntPipeline.Head)的流,是其他流的源头。
- peek(...) 是属于无状态的操作(S[图片上传中...(类关系图.png-e38fae-1519806177856-0)]
tatelessOp),本质是创建了一个IntPipeline.StatelessOp类型的流,是用于处理流(BaseStream)的中间操作管道(Pipeline)。 - skip(...) 和 limit(...) 是属于有状态的操作(StatefulOp),本质是创建了一个IntPipeline.StatefulOp类型的流,是用于处理流(BaseStream)的中间操作管道(Pipeline)。
- sum(...) 本质是创建了一个ReduceOp,是属于终止操作(TerminalOp)的一种,遇到终止操作的时候,才会触发对整个流的求值(AbstractPipeline#evaluate)。
以上几种流以及终止操作的类关系图如下所示:

- BaseStream:提供流的基本接口,如迭代器(iterator、spliterator),流的类型及判断(isParallel、sequential、parallel、unordered)等。
- IntStream:定义了流的各种最常见的操作接口,如skip、limit、peek等。
- PipelineHelper:定义了流水线过程中需要用到的辅助方法,如evaluate、exactOutputSizeIfKnown、copyInto等。
- AbstractPipeline:继承了PipelineHelper,包含了基本的管道操作实现。里面包含了sourceStage、previousStage、nextStage,由此可以组成一个双向链表。
可以看出,Head、StatefulOp、StatelessOp都属于BaseStream,并且也都继承了AbstractPipeline。而终止操作既不属于流(BaseStream),也不属于管道(AbstractPipeline)。
了解了这些关系,再来看一下上述代码各个管道组成的流水线:

Sum触发了整个流的求值,在这个流中,除了Head之外,还有三个操作,即peek、skip、limit。peek其本质是一个StatelessOp,仅将遍历到的值按照给定的Consumer执行,再将值传递给下游,peek方法的源码如下:

在 skip 值等于 5 和 7 的时候,并行流中之所以没有打印出部分数字,说明这部分数字根本就没有传递给 peek ,但为何会没有遍历到这部分数字呢?那就只能猜测是 skip 和 limit 对流的源头产生了影响。
SliceOps
再仔细翻看代码,在AbstractPipeline的evaluate方法中发现了sourceSpliterator方法:
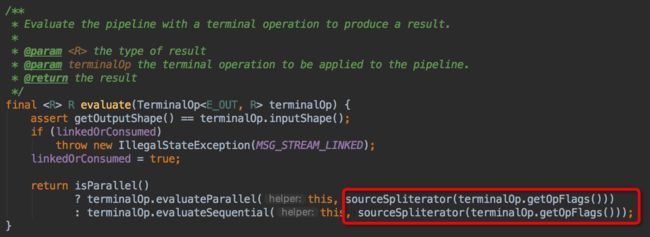
该方法的文档上写着:
Get the source spliterator for this pipeline stage. For a sequential or stateless parallel pipeline, this is the source spliterator. For a stateful parallel pipeline, this is a spliterator describing the results of all computations up to and including the most recent stateful operation.
很明显,在我们的流中包含了 2 个有状态的操作: skip 和 limit 。那么最终返回的Spliterator就不是Source Spliterator(Head)了,而是一个包含了最近的 StatefulOps 所有计算结果的Spliterator。也就是说,有状态的操作在并行流求值中,可能会改变原始流。
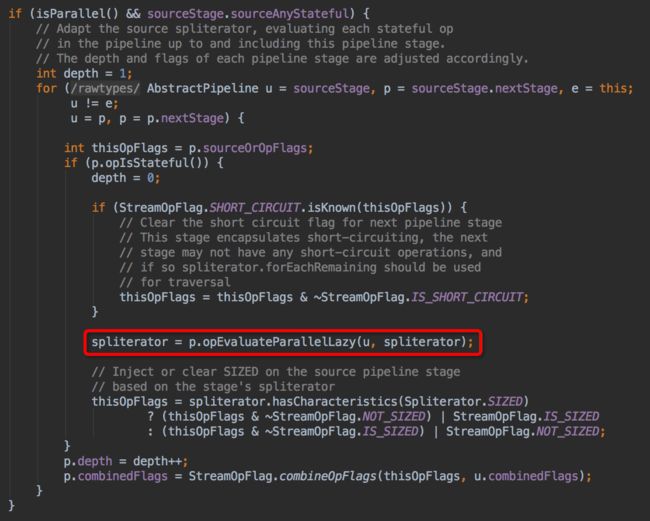
上图是 sourceSpliterator 中的代码片段,可以看出,如果是有状态的操作,则会调用 StatefulOp 的 opEvaluateParallelLazy 方法计算出新的 spliterator 。
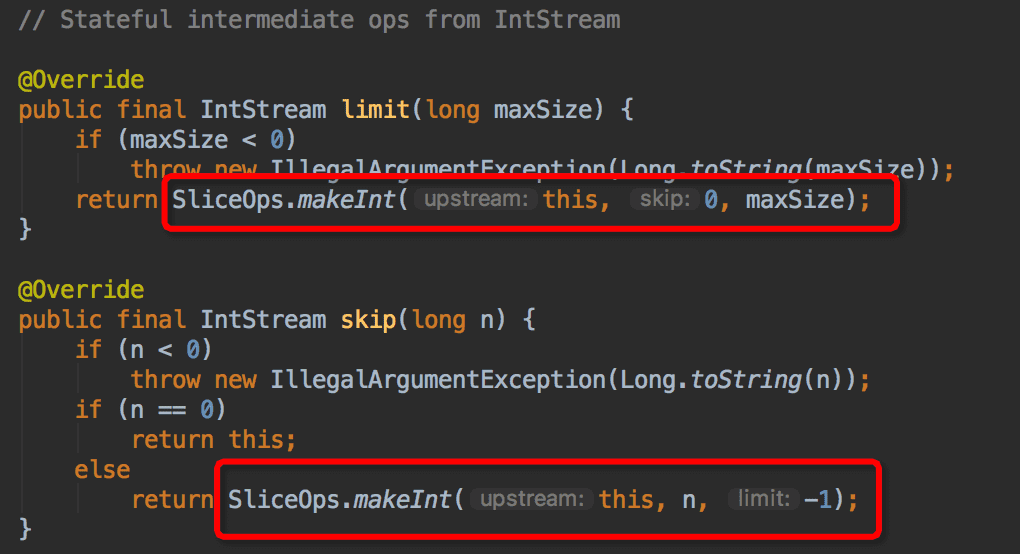
再看 skip 和 limit 方法的代码,可以发现他们都是通过 SliceOps#makeInt(...)方法创建出来的。

当原始流是有边界(SIZED、SUBSIZED)的时候,会使用SliceSpliterator将原始流包裹起来,并设置 SliceSpliterator 的 sliceOrigin 和 sliceFence 属性。这是两个对原始流做切片的位置标识,在原始流的基础上,标明了要切片的起始位置和终止位置,最终在遍历的时候,会根据 sliceOrigin 和 sliceFence 来控制流的起止。大致流程如下所示:
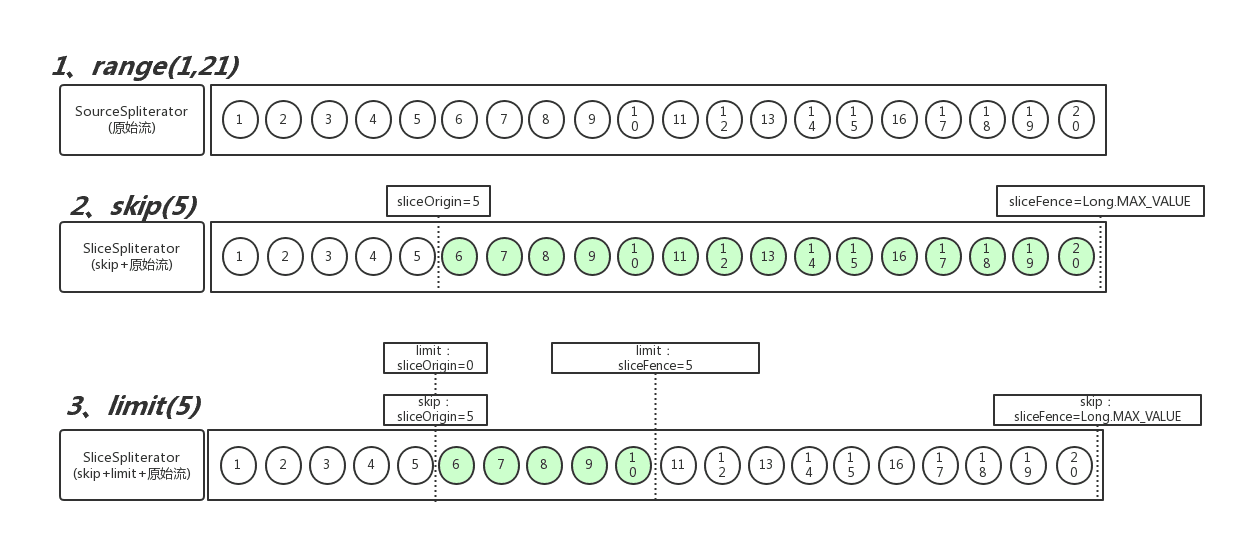
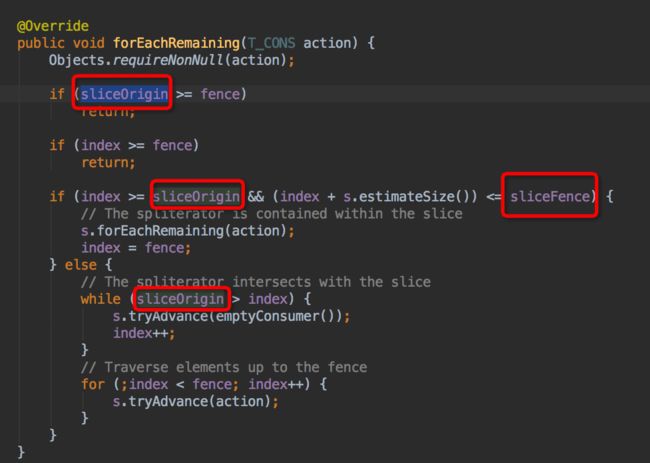
至此大致可以确定部分数字未打印出来,是跟有状态的管道操作(StatefulOp)有关。但仍然不能解释:为何当skip=7时,不会打印前7个数,而当skip=5时,为何只跳过了前4个数;当skip=8时,又为何能打印出全部数字?
ForkJoinTask & Spliterator
在并行流中,终止操作会调用 evaluateParallel 方法来对整个流求值,在这个方法中会创建一个ReduceTask并获取其结果。
@Override
public R evaluateParallel(PipelineHelper helper,
Spliterator spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
ReduceTask继承于AbstractTask,而AbstractTask则是一种ForkJoinTask。类关系图如下所示:
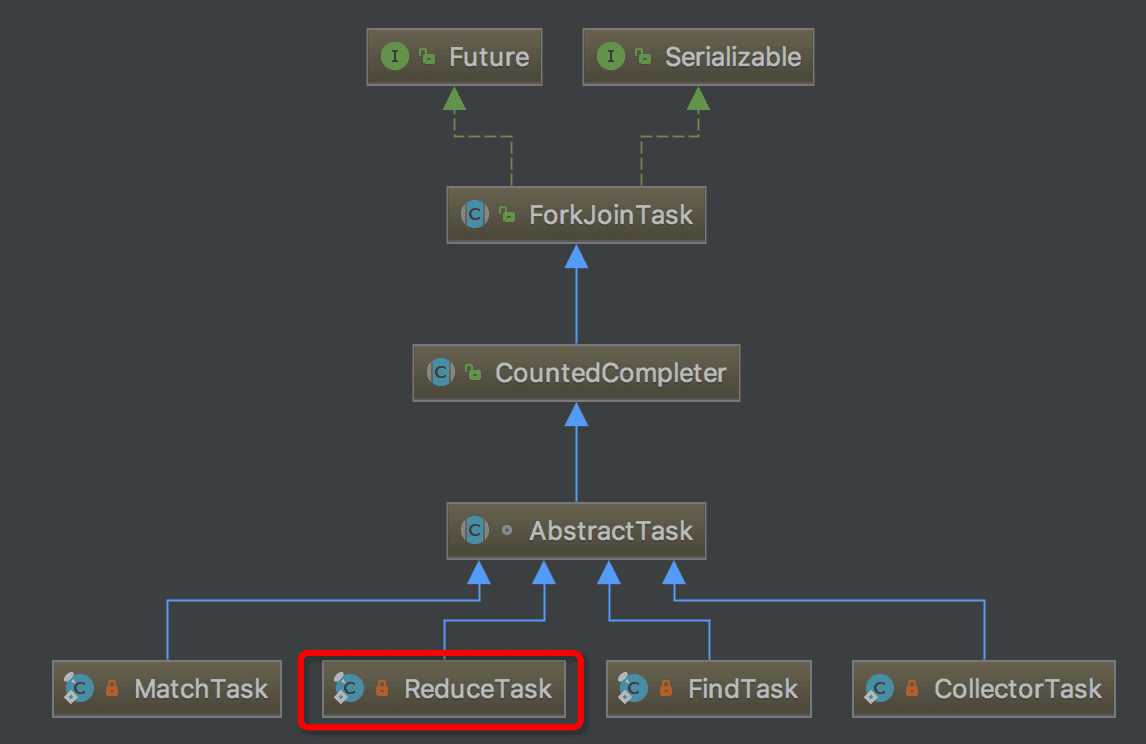
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
...
ForkJoinTask与一般的任务的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
from Fork/Join框架介绍
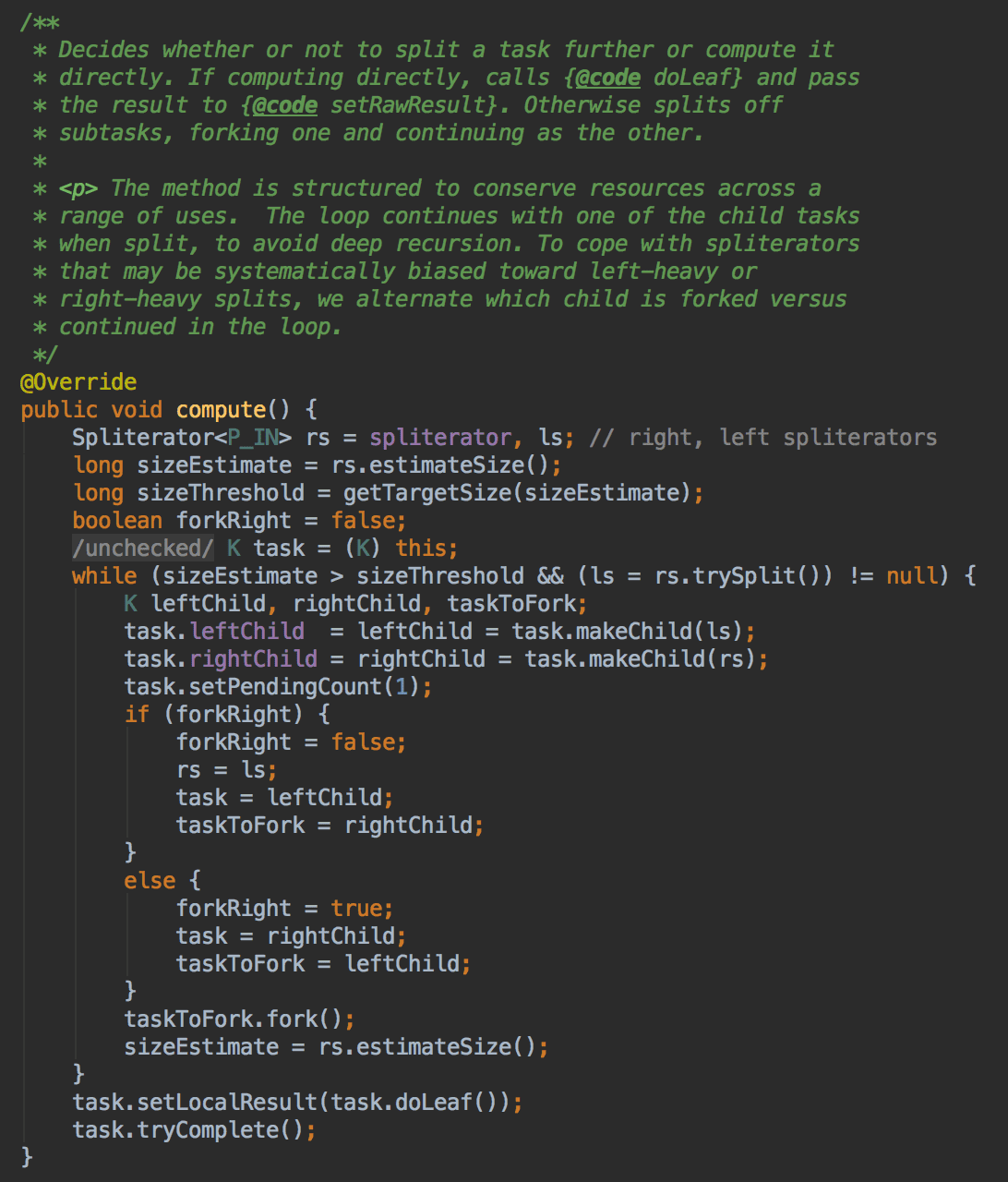
接下来看一下在AbstractTask中的compute方法。
首先会计算预测数据大小(sizeEstimate),同时会根据 sizeEstimate 设置一个用于拆分任务的最细粒度阈值(sizeThreshold),计算方式为:
sizeThreshold = sizeEstimate / commonParallelism * 4
- sizeEstimate:预测流的数据大小,不同流计算方式不一样。
- commonParallelism:默认ForkJoinPool的大小,默认为Runtime.getRuntime().availableProcessors() - 1,最小值为1,最大值为32767(0x7fff),默认为可以通过设置java.util.concurrent.ForkJoinPool.common.parallelism来指定。具体详见java.util.concurrent.FockJoinPool#makeCommonPool()。
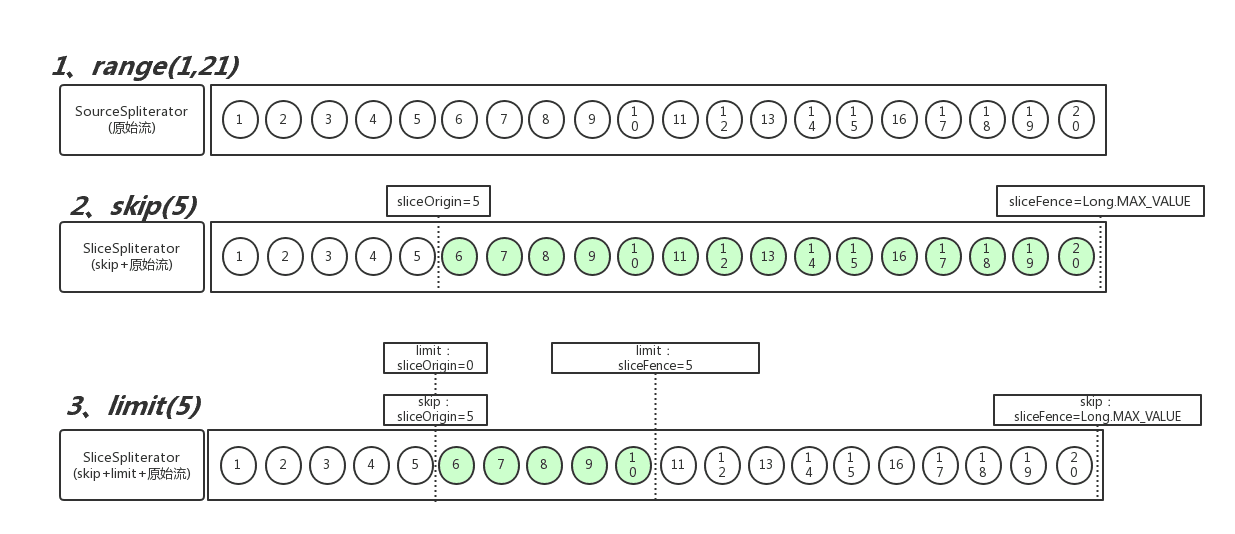
还记得上一节的 SliceOps 吗?原始流受 skip 和 limit 的影响,在传入 ReduceTask 的时候已经被包装成了 SliceSpliterator 。原始流的 sizeEstimate = 19 ,而经过 SliceSpliterator 包装之后的 SliceSpliterator ,其 sizeEstimate = 5 ,如下图第三步绿色部分所示:
我是在一台8核的笔记本上运行该程序,因此计算得到 sizeThreshold = 5 / ((8 - 1) * 4) = 5 / 28 ≈ 1 (最小值为1,不能为0),即用于拆分任务的最细粒度阈值(sizeThreshold)为 1 。
计算完sizeThreshold后,接着进行任务拆分。
将Stream拆分成多个部分的算法是一个递归过程,如图所示。第一步是对第一个 Spliterator调用trySplit,生成第二个Spliterator。第二步对这两个Spliterator调用 trysplit,这样总共就有了四个Spliterator。这个框架不断对Spliterator调用trySplit 直到它返回null,表明它处理的数据结构不能再分割,如第三步所示。最后,这个递归拆分过 程到第四步就终止了,这时所有的Spliterator在调用trySplit时都返回了null。
 image
image
from 《Java8实战》Spliterator拆分过程
在 SliceSpliterator#trySplit() 中,会直接调用原始流的trySplit()方法,上述代码用到的是range,则调用的是RangeIntSpliterator的trySplit()方法。
@Override
public Spliterator.OfInt trySplit() {
long size = estimateSize();
return size <= 1
? null
// Left split always has a half-open range
: new RangeIntSpliterator(from, from = from + splitPoint(size), 0);
}
private static final int BALANCED_SPLIT_THRESHOLD = 1 << 24;
private static final int RIGHT_BALANCED_SPLIT_RATIO = 1 << 3;
private int splitPoint(long size) {
int d = (size < BALANCED_SPLIT_THRESHOLD) ? 2 : RIGHT_BALANCED_SPLIT_RATIO;
// Cast to int is safe since:
// 2 <= size < 2^32
// 2 <= d <= 8
return (int) (size / d);
}
由于原始流的大小远远小于BALANCED_SPLIT_THRESHOLD,因此默认是对半拆分。当拆分到 预测大小小于或等于拆分最细粒度(estimateSize <= sizeThreshold)时 ,则停止拆分,才进行流的求值操作。
在测试代码中,原始流是由RangeIntSpliterator生成,其 estimateSize 的计算方式如下,通俗地说为range圈定的大小 [1,20):
@Override
public long estimateSize() {
return upTo - from + last;
}
但是,经过 SliceSpliterator 包装后,其 estimateSize 的计算方式如下,通俗地说为切片后的大小:
public long estimateSize() {
return (sliceOrigin < fence)
? fence - Math.max(sliceOrigin, index) : 0;
}
当skip(5).limit(5)的时候,其切片过程如下所示:

最终会被分割成5个子任务:
- 子任务1:[5,6], estimateSize = 1,因为有效数字是6,5是被skip掉的,所以estimateSize =1
- 子任务2:[7], estimateSize = 1
- 子任务3:[8], estimateSize = 1
- 子任务4:[9], estimateSize = 1
- 子任务5:[10,19], estimateSize = 1,数字10之后的数字会被切片切掉
注意,在[1,9]拆分的过程中,[1,4]由于刚好是在在切片范围之外(estimateSize=0,被skip掉的部分),在trySplit方法中返回的是null,直接被丢弃掉,在后续对流切片进行求值的时候,[1,4]也就永远不会被peek处理到。而切片1中的数字5刚好和数字6分配在了同一个切片中,在求值的时候,peek始终不会打印前4个数字,这也就是为什么当skip(5)的时候,数字5能够被peek出来。
同理,当skip(7).limit(5)的时候,原本的[5,6]切片和[7]切片都因为estimateSize=0而被丢弃,所以peek始终不会打印前7个数字,而只会打印[8,12]这5个数字,最终子任务分割如下所示:
- 子任务1:[8], estimateSize = 1
- 子任务2:[9], estimateSize = 1
- 子任务3:[10], estimateSize = 1
- 子任务4:[11], estimateSize = 1
- 子任务5:[12], estimateSize = 1
最后再来看,当skip(8).limit(5)的时候,最终子任务分割如下所示:
- 子任务1:[1,9], estimateSize = 1,因为skip前8个数字,有效数字仅剩数字9一个了
- 子任务2:[10], estimateSize = 1
- 子任务3:[11], estimateSize = 1
- 子任务4:[12], estimateSize = 1
- 子任务5:[13,14], estimateSize = 1,数字14会被切片切掉
很容易就可以看出,前8个数字刚好跟数字9分配在一个子任务中,且刚好构成了最小子任务(estimateSize = 1),因此peek始终可以打印出[1,13]这13个数字。
总结
- 在并行流的情况下,有状态操作(StatefulOp)可能会直接对原始流(Head)的遍历产生影响,如 skip 和 limit 对原始流进行切片(SliceOps)。
- 在并行流的情况下,会使用 ForkJoinTask 进行并行计算,而 ForkJoinTask 会对任务(流)进行分割,同时会丢弃掉estimateSize=0的子任务(流),做个不是很恰当的比喻:可以认为是对整个流做一个不太精确的 “trim” 操作(如skip=5和skip=8的情况)。切片范围不同,会对 ForkJoinTask 分割子任务产生不同的影响,从而影响了程序运行结果。
写得有点啰嗦,不过总算是搞清楚问题的原因了,如有理解不对的地方,还请批评指正。