Pytorch学习记录-torchtext和Pytorch的实例3
0. PyTorch Seq2Seq项目介绍
在完成基本的torchtext之后,找到了这个教程,《基于Pytorch和torchtext来理解和实现seq2seq模型》。
这个项目主要包括了6个子项目
使用神经网络训练Seq2Seq使用RNN encoder-decoder训练短语表示用于统计机器翻译- 使用共同学习完成NMT的构建和翻译
- 打包填充序列、掩码和推理
- 卷积Seq2Seq
- Transformer
3. 使用共同学习完成NMT的堆砌和翻译
这一节通过实现基于共同学习的NMT来学习注意力机制。通过在Decoder部分提供“look back”输入语句,允许Encoder创建Decoder隐藏状态加权和的上下文向量来进一步缓解信息压缩问题。通过注意力机制计算加权和的权重,其中Decoder学习如何注意输入句子中最相关的单词。
本节依旧使用Pytorch和Torchtext实现模型,参考论文《 Neural Machine Translation by Jointly Learning to Align and Translate》
3.1 介绍
3.2 处理数据
这部分和之前一样,因为使用的数据集是相同的。下面是总结的流程:
1.1 tokenize使用加载好的分词器进行分词(如果使用spacy这类分词器,先加载分词器)
1.2 将分词结果放入Field中
1.3 加载平行语料库,使用splits将语料库拆分为train、valid、test,同时加上src和trg标签
1.4 使用build_vocab构建词汇表,将SRC、TRG两个Field转为词汇表
1.5 构建迭代器,使用BucketIterator.splits将train、valid、test三个数据集转为迭代器 在预处理阶段有两组数据:
(1)训练好的平行语料库、(2)要处理的语料
- 训练好的平行语料库做了处理,拆分成了traindata/validdata/testdata,然后做成迭代器trainiter/validiter/testiter。
- 要处理的语料进行分词处理,放入Field成为SRC和TRG,最后生成词汇表
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import BucketIterator, Field
import spacy
import random
import math
import time
SEED=1234
random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic=True
spacy_de=spacy.load('de')
spacy_en=spacy.load('en')
def tokenize_de(text):
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
SRC=Field(tokenize=tokenize_de,init_token='',eos_token='',lower=True)
TRG=Field(tokenize=tokenize_en,init_token='',eos_token='',lower=True)
train_data,valid_data,test_data=Multi30k.splits(exts=('.de','.en'),fields=(SRC,TRG))
SRC.build_vocab(train_data,min_freq=2)
TRG.build_vocab(train_data,min_freq=2)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
cuda
BATCH_SIZE=32
train_iterator,valid_iterator,test_iterator=BucketIterator.splits(
(train_data,valid_data,test_data),
batch_size=BATCH_SIZE,
device=device
)
3.3 构建模型
由四部分组成:Encoder,Attention,Decoder,Seq2Seq
3.3.1 Encoder
Encoder使用单层GRU,在这里使用bidirectional RNN。通过bidirectional RNN,每层可以有两个RNN网络。
- 前向RNN从左到右处理句子(图中绿色)
-
后向RNN从右到左处理句子(图中黄色)
在这里要做的就是设置 bidirectional = True ,然后输入嵌入好的句子。
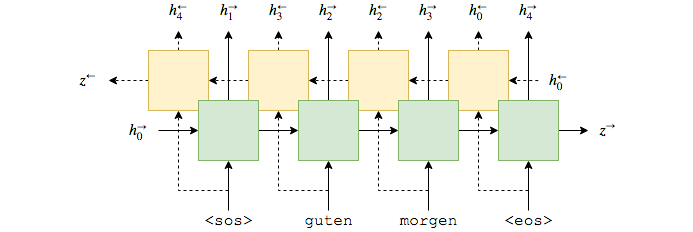 image.png
image.png
公式如下:
和之前一样,我们只将输入(嵌入)传递给RNN,它告诉PyTorch初始化前向和后向初始隐藏状态(分别为和)张量0。
我们还将获得两个上下文向量,一个来自前向RNN,在它看到句子中的最后一个单词后,;一个来自后向RNN后看到第一个单词在句子中,。
Encoder返回outputs和hidden。
- outputs的大小为[src长度, batch_size, hid_dim num_directions],其中hid_dim是来自前向RNN的隐藏状态。这里可以将(hid_dim num_directions)看成是前向、后向隐藏状态的堆叠。, ,我们也可以将所有堆叠的编码器隐藏状态表示为。
- hidden的大小为[n_layers num_directions, batch_size, hid_dim],其中[-2,:,:]在最后的时间步之后(即在看到最后一个单词之后)给出顶层前向RNN隐藏状态在句子。和[-1,:,:]在最后的时间步之后(即在看到句子中的第一个单词之后)给出顶层后向RNN隐藏状态。
由于Decoder不是双向的,它只需要一个上下文向量作为其初始隐藏状态,我们目前有两个,前向和后向(和)。我们通过将两个上下文向量连接在一起,通过线性层并应用激活函数来解决这个问题。公式如下:
由于我们希望我们的模型回顾整个源句,我们返回输出,源句中每个标记的堆叠前向和后向隐藏状态。我们还返回hidden,它在解码器中充当我们的初始隐藏状态。
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super(Encoder,self).__init__()
self.input_dim=input_dim
self.emb_dim=emb_dim
self.enc_hid_dim=enc_hid_dim
self.dec_hid_dim=dec_hid_dim
self.dropout=dropout
self.embedding=nn.Embedding(input_dim,emb_dim)
self.rnn=nn.GRU(emb_dim,enc_hid_dim,bidirectional=True)
self.fc=nn.Linear(enc_hid_dim*2,dec_hid_dim)
self.dropout=nn.Dropout(dropout)
def forward(self,src):
#src = [src sent len, batch size]
embedded=self.dropout(self.embedding(src))
outputs, hidden=self.rnn(embedded)
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1)))
return outputs, hidden
3.3.2 Attention注意力
构建attention层,包括有之前Decoder的隐藏状态,Encoder中所有的前向和后向隐藏状态。这个层会输出一个注意力向量。长度为源句长度,每一个元素都在0和1之间,总和为1。
接下来的是机翻,实在看不进去……
直观地说,这个层采用我们迄今已解码的,以及我们编码的所有内容来生成一个向量,它表示我们要特别注意源句中的哪些单词,它们正确预测要解码的下一个单词,。
首先,我们计算先前Decoder隐藏状态和Encoder隐藏状态之间的能量。由于我们的Encoder隐藏状态是张量序列,而我们之前的Decoder隐藏状态是单个张量,我们做的第一件事就是重复前一个Decoder隐藏状态次。然后我们通过将它们连接在一起并通过线性层(attn)和激活函数来计算它们之间的能量。
这可以被认为是计算每个编码器隐藏状态与先前解码器隐藏状态“匹配”的程度。
我们目前为批处理中的每个示例都有一个[dec hid dim,src sent len] tensor。我们希望这对于批处理中的每个示例都是[src sent len],因为注意力应该超过源句子的长度。这是通过将能量乘以[1,dec hid dim]张量,来实现的。
我们可以将此视为计算每个编码器隐藏状态的所有dec_hid_dem元素的“匹配”的加权和,其中学习权重(当我们学习的参数时)。
最后,我们确保注意向量符合所有元素在0和1之间的约束,并且通过将它传递到层,向量求和为1。
这让我们关注源句!
从图形上看,这看起来如下所示。这是用于计算第一个注意向量,其中。绿色/黄色块表示来自前向和后向RNN的隐藏状态,并且注意力计算全部在粉红色块内完成。

class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super(Attention,self).__init__()
self.enc_hid_dim=enc_hid_dim
self.dec_hid_dim=dec_hid_dim
self.attn=nn.Linear((enc_hid_dim*2)+dec_hid_dim,dec_hid_dim)
self.v=nn.Parameter(torch.rand(dec_hid_dim))
def forward(self, hidden, encoder_outputs):
batch_size=encoder_outputs.shape[1]
src_len=encoder_outputs.shape[0]
hidden=hidden.unsqueeze(1).repeat(1,src_len,1)
encoder_outputs=encoder_outputs.permute(1,0,2)
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim = 2)))
energy = energy.permute(0, 2, 1)
v = self.v.repeat(batch_size, 1).unsqueeze(1)
attention = torch.bmm(v, energy).squeeze(1)
return F.softmax(attention, dim=1)
3.3.3 Decoder
Decoder包括了注意力层,含有上一个隐藏状态,所有Encoder的隐藏状态,返回注意力向量。
接下来使用注意力向量创建加权源向量功能,含有Encoder隐藏状态的加权和,并使用注意力向量作为权重。公式如下
输入字(已嵌入),加权源向量和先前的Decoder隐藏状态,全部传递到Decoder。

class Decoder(nn.Module):
def __init__(self,output_dim,emb_dim,enc_hid_dim,dec_hid_dim,dropout, attention):
super(Decoder,self).__init__()
self.emb_dim = emb_dim
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.output_dim = output_dim
self.dropout = dropout
self.attention = attention
self.embedding=nn.Embedding(output_dim,emb_dim)
self.rnn=nn.GRU((enc_hid_dim*2)+emb_dim,dec_hid_dim)
self.out=nn.Linear((enc_hid_dim*2)+dec_hid_dim+emb_dim,output_dim)
self.dropout=nn.Dropout(dropout)
def forward(self,input,hidden,encoder_outputs):
input=input.unsqueeze(0)
embedded=self.dropout(self.embedding(input))
a=self.attention(hidden,encoder_outputs)
a=a.unsqueeze(1)
encoder_outputs=encoder_outputs.permute(1,0,2)
weighted = torch.bmm(a, encoder_outputs)
weighted = weighted.permute(1, 0, 2)
rnn_input = torch.cat((embedded, weighted), dim = 2)
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
assert (output == hidden).all()
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
output = self.out(torch.cat((output, weighted, embedded), dim = 1))
#output = [bsz, output dim]
return output, hidden.squeeze(0)
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
#src = [src sent len, batch size]
#trg = [trg sent len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use teacher forcing 75% of the time
batch_size = src.shape[1]
max_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(max_len, batch_size, trg_vocab_size).to(self.device)
#encoder_outputs is all hidden states of the input sequence, back and forwards
#hidden is the final forward and backward hidden states, passed through a linear layer
encoder_outputs, hidden = self.encoder(src)
#first input to the decoder is the tokens
output = trg[0,:]
for t in range(1, max_len):
output, hidden = self.decoder(output, hidden, encoder_outputs)
outputs[t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.max(1)[1]
output = (trg[t] if teacher_force else top1)
return outputs
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
ENC_HID_DIM = 512
DEC_HID_DIM = 512
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
attn = Attention(ENC_HID_DIM, DEC_HID_DIM)
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)
model = Seq2Seq(enc, dec, device).to(device)
def init_weights(m):
for name, param in m.named_parameters():
if 'weight' in name:
nn.init.normal_(param.data, mean=0, std=0.01)
else:
nn.init.constant_(param.data, 0)
model.apply(init_weights)
Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(7855, 256)
(rnn): GRU(256, 512, bidirectional=True)
(fc): Linear(in_features=1024, out_features=512, bias=True)
(dropout): Dropout(p=0.5)
)
(decoder): Decoder(
(attention): Attention(
(attn): Linear(in_features=1536, out_features=512, bias=True)
)
(embedding): Embedding(5893, 256)
(rnn): GRU(1280, 512)
(out): Linear(in_features=1792, out_features=5893, bias=True)
(dropout): Dropout(p=0.5)
)
)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
The model has 20,518,917 trainable parameters
optimizer = optim.Adam(model.parameters())
PAD_IDX = TRG.vocab.stoi['']
criterion = nn.CrossEntropyLoss(ignore_index = PAD_IDX)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg sent len, batch size]
#output = [trg sent len, batch size, output dim]
output = output[1:].view(-1, output.shape[-1])
trg = trg[1:].view(-1)
#trg = [(trg sent len - 1) * batch size]
#output = [(trg sent len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg sent len, batch size]
#output = [trg sent len, batch size, output dim]
output = output[1:].view(-1, output.shape[-1])
trg = trg[1:].view(-1)
#trg = [(trg sent len - 1) * batch size]
#output = [(trg sent len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 2
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut3-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
Epoch: 01 | Time: 21m 20s
Train Loss: 2.751 | Train PPL: 15.655
Val. Loss: 3.157 | Val. PPL: 23.493
Epoch: 02 | Time: 21m 29s
Train Loss: 2.281 | Train PPL: 9.783
Val. Loss: 3.136 | Val. PPL: 23.013
今天遇到了传说中的现存不够,降低了batch_size才勉强跑起来,一个epoch竟然要20多分钟啊……教程里只用了40多秒,不知道用的什么显卡……学完之后要换云平台才行。
model.load_state_dict(torch.load('tut3-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
| Test Loss: 3.183 | Test PPL: 24.115 |