作者:正龙(沪江Web前端开发工程师)
本文为原创文章,转载请注明作者及出处
上文“走进Node.js启动过程”中我们算是成功入门了。既然Node.js的强项是处理网络请求,那我们就来分析一个HTTP请求在Node.js中是怎么被处理的,以及JavaScript在这个过程中引入的开销到底有多大。
Node.js采用的网络请求处理模型是IO多路复用。它与传统的主从多线程并发模型是有区别的:只使用有限的线程数(1个),所以占用系统资源很少;操作系统级的异步IO支持,可以减少用户态/内核态切换,并且本身性能更高(因为直接与网卡驱动交互);JavaScript天生具有保护程序执行现场的能力(闭包),传统模型要么依赖应用程序自己保存现场,或者依赖线程切换时自动完成。当然,并不能说IO多路复用就是最好的并发模型,关键还是看应用场景。
我们来看“hello world”版Node.js网络服务器:
require('http').createServer((req, res) => {
res.end('hello world');
}).listen(3333);
代码思路分析
createServer([requestListener])
createServer创建了http.Server对象,它继承自net.Server。事实上,HTTP协议确实是基于TCP协议实现的。createServer的可选参数requestListener用于监听request事件;另外,它也监听connection事件,只不过回调函数是http.Server自己实现的。然后调用listen让http.Server对象在端口3333上监听连接请求并最终创建TCP对象,由tcp_wrap.h实现。最后会调用TCP对象的listen方法,这才真正在指定端口开始提供服务。我们来看看涉及到的所有JavaScript对象:
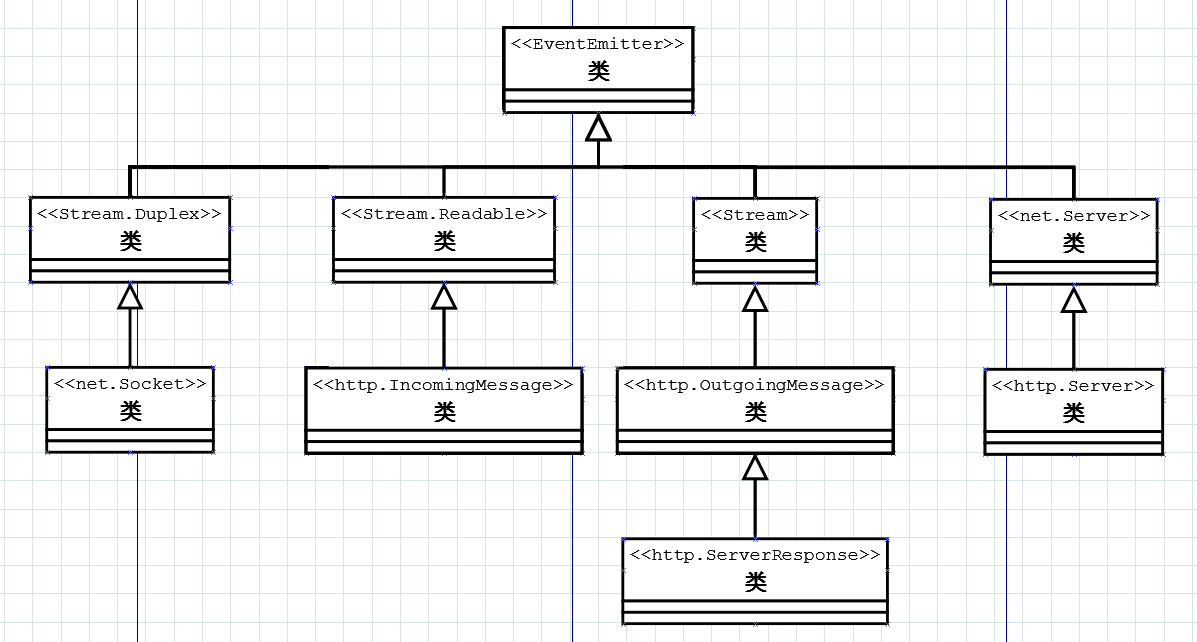
涉及到的C++类大多只是对libuv做了一层包装并公布给JavaScript,所以不在这里特别列出。我们有必要提一下http-parser,它是用来解析http请求/响应消息的,本身十分高效:没有任何系统调用,没有内存分配操作,纯C实现。
connection事件
当服务器接受了一个连接请求后,会触发connection事件。我们可以在这个结点获取到套接字文件描述符,之后就可以在这个文件描述符上做流式读或写,也就是所谓的全双工模式。上文提到net.Server的listen方法会创建TCP对象,并且提供TCP对象的onconnection事件回调方法;这里可以利用字段net.Server.maxConnections做过载保护,后面会讲到。并且会把clientHandle(本次连接的套接字文件描述符)封装成net.Socket对象,作为connection事件的参数。我们来看看调用过程:
tcp_wrap.cc
void TCPWrap::Listen(const FunctionCallbackInfo& args) {
int err = uv_listen(reinterpret_cast(&wrap->handle_),
backlog,
OnConnection);
args.GetReturnValue().Set(err);
}
OnConnection 在connection_wrap.cc中定义
// ...省略不重要的代码
uv_stream_t* client_handle =
reinterpret_cast(&wrap->handle_);
// uv_accept can fail if the new connection has already been closed, in
// which case an EAGAIN (resource temporarily unavailable) will be
// returned.
if (uv_accept(handle, client_handle))
return;
// Successful accept. Call the onconnection callback in JavaScript land.
argv[1] = client_obj;
// ...省略不重要的代码
wrap_data->MakeCallback(env->onconnection_string(), arraysize(argv), argv);
上文提到的clientHandle实际上是uv_accept的第二个参数,指服务当前连接的套接字文件描述符。net.Server的字段 _handle 会在JavaScript侧存储该字段。最后我们上一张流程图:
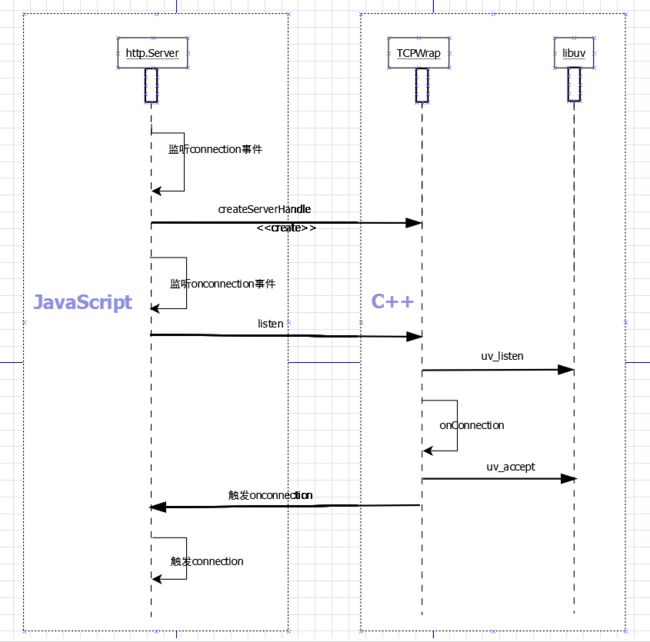
request事件
connection事件的回调函数connectionListener(lib/_http_server.js)中,首先获取http-parser对象,设置parser.onIncoming回调(马上会用到)。当连接套接字有数据到达时,调用http-parser.execute方法。http-parser在解析过程中会触发如下回调函数:
on_message_begin:在开始解析HTTP消息之前,可以设置http-parser的初始状态(注意http-parse有可能是复用的而不是重每次新创建)
on_url:解析请求的url,对响应消息不起作用
on_status, 解析状态码,只对http响应消息起作用
on_head_field, 头字段名称
on_head_value:头字段对应值
on_headers_complete:当所有头解析完成时
on_body:解析http消息中包含的payload
on_message_complete:解析工作结束
Node.js中Parser类是对http-parser的包装,它会注册上面所有的回调函数。同时,暴露给JavaScript5个事件:
kOnHeaders,kOnHeadersComplete,kOnBody,kOnMessageComplete,kOnExecute。在lib/_http_common.js中监听了这些事件。其中,当需要强制把头字段回传到JavaScript时会触发kOnHeaders;例如,头字段个数超过32,或者解析结束时仍然有头字段没有回传给JavaScript。当调用完http_parser_execute后触发kOnExecute。kOnHeadersComplete事件触发时,会调用parser的onIncoming回调函数。仅仅HTTP头解析完成之后,就会触发request事件。执行流程如下:
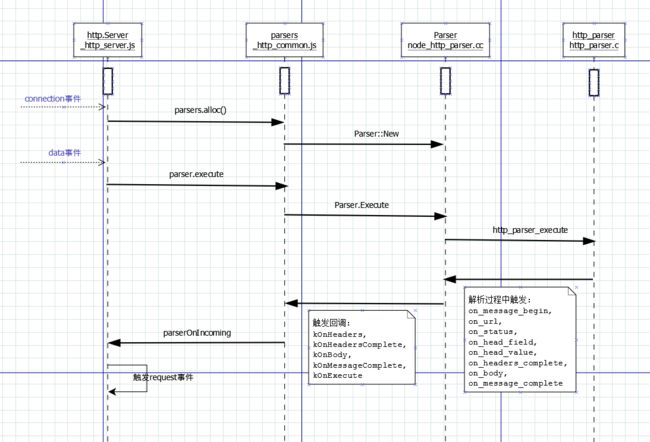
总结
说了那么多,其实仍然离不开最基础的套接字编程步骤,对于服务器端依次是:create、bind,listen、accept和close。客户端会经历create、bind、connect和close。想了解更多套接字编程的同学可以参考《UNIX网络编程》。
HTTP场景分析
上面提到的Node.js版hello world只涵盖了HTTP处理最基本的情况,但是也足以说明Node.js处理得非常简洁。现在,我们来分析一些典型的HTTP场景。
1. keep-alive
对于前端应用,HTTP请求瞬间数量比较多,但每个请求传输的数据一般不大;这时,用同一个TCP连接处理同一个用户发出的HTTP请求可以显著提高性能。但是keep-alive也不是万能的,如果用户每次只发起一个请求,它反而会因为延长连接的生存时间,浪费服务器资源。
针对同一个连接,Node.js会维持一个incoming队列和一个outgoing队列。应用程序通过监听request事件,可以访问ServerResponse和IncomingMessage对象,当请求处理完成之后(调用response.end()),ServerResponse会响应finish事件。如果它是本次连接上最后一个response对象,则准备关闭连接;否则,继续触发request事件。每个连接最长超时时间默认为2分钟,可以通过http.Server.setTimeout调整。
现在把我们的Node.js版hello world修改一下
var delay = [2000, 30, 500];
var i = 0;
require('http').createServer((req, res) => {
// 为了让请求模拟更真实,会调整每个请求的响应时间
setTimeout(() => {
res.end('hello world');
}, delay[i]);
i = (i+1)%(delay.length);
}).listen(3333, () => {
// listen的回调函数
console.log('listen at 3333');
});
客户端代码如下:
var http = require('http');
// 设置HTTP agent开启keep-alive模式
// 套接字的打开时间维持1分钟
var agent = new http.Agent({
keepAlive: true,
keepAliveMsecs: 60000
});
// 每次请求结束之后,都会再发起一次请求
// doReq每调用一次只会触发2次请求
function doReq(again, iter) {
let request = http.request({
hostname: '192.168.1.10',
port: 3333,
agent:agent
}, (res) => {
console.log(`${new Date().valueOf()} ${iter} ${again} Headers: ${JSON.stringify(res.headers)}`);
console.log(request.socket.localPort);
// 设置解析响应的编码格式
res.setEncoding('utf8');
// 接收响应
res.on('data', (chunk) => {
console.log(`${new Date().valueOf()} ${iter} ${again} Body: ${chunk}`);
});
if (again) doReq(false, iter);
});
// 发起请求
request.end();
}
for (let i = 0; i < 3; i++) {
doReq(true, i);
}
套接字复用的时序如下:
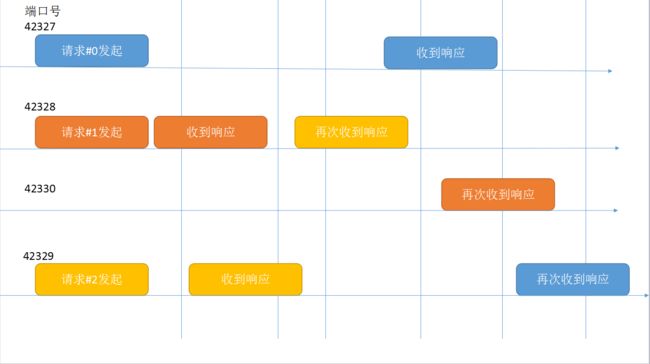
2. Expect头
如果客户端在发送POST请求之前,由于传输的数据量比较大,期望向服务器确认请求是否能被处理;这种情况下,可以先发送一个包含头Expect:100-continue的http请求。如果服务器能处理此请求,则返回响应状态码100(Continue);否则,返回417(Expectation Failed)。默认情况下,Node.js会自动响应状态码100;同时,http.Server会触发事件checkContinue和checkExpectation来方便我们做特殊处理。具体规则是:当服务器收到头字段Expect时:如果其值为100-continue,会触发checkContinue事件,默认行为是返回100;如果值为其它,会触发checkExpectation事件,默认行为是返回417。
例如,我们通过curl发送HTTP请求:
curl -vs --header "Expect:100-continue" http://localhost:3333
交互过程如下
> GET / HTTP/1.1
> Host: localhost:3333
> User-Agent: curl/7.49.1
> Accept: */*
> Expect:100-continue
>
< HTTP/1.1 100 Continue
< HTTP/1.1 200 OK
< Date: Mon, 03 Apr 2017 14:15:47 GMT
< Connection: keep-alive
< Content-Length: 11
<
我们接收到2个响应,分别是状态码100和200。前一个是Node.js的默认行为,后一个是应用程序代码行为。
3. HTTP代理
在实际开发时,用到http代理的机会还是挺多的,比如,测试说线上出bug了,触屏版页面显示有问题;我们一般第一时间会去看api返回是否正常,这个时候在手机上设置好代理就能轻松捕获HTTP请求了。老牌的代理工具有fiddler,charles。其实,nodejs下也有,例如node-http-proxy,anyproxy。基本思路是监听request事件,当客户端与代理建立HTTP连接之后,代理会向真正请求的服务器发起连接,然后把两个套接字的流绑在一起。我们可以实现一个简单的代理服务器:
var http = require('http');
var url = require('url');
http.createServer((req, res) => {
// request回调函数
console.log(`proxy request: ${req.url}`);
var urlObj = url.parse(req.url);
var options = {
hostname: urlObj.hostname,
port: urlObj.port || 80,
path: urlObj.path,
method: req.method,
headers: req.headers
};
// 向目标服务器发起请求
var proxyRequest = http.request(options, (proxyResponse) => {
// 把目标服务器的响应返回给客户端
res.writeHead(proxyResponse.statusCode, proxyResponse.headers);
proxyResponse.pipe(res);
}).on('error', () => {
res.end();
});
// 把客户端请求数据转给中间人请求
req.pipe(proxyRequest);
}).listen(8089, '0.0.0.0');
验证下是否真的起作用,curl通过代理服务器访问我们的“hello world”版Node.js服务器:
curl -x http://192.168.132.136:8089 http://localhost:3333/
优化策略
Node.js在实现HTTP服务器时,除了利用高性能的http-parser,自身也做了些性能优化。
1. http_parser对象缓存池
http-parser对象处理完一个请求之后不会被立即释放,而是被放入缓存池(/lib/internal/freelist),最多缓存1000个http-parser对象。
2. 预设HTTP头总数
HTTP协议规范并没有限定可以传输的HTTP头总数上限,http-parser为了避免动态分配内存,设定上限默认值是32。其他web服务器实现也有类似设置;例如,apache能处理的HTTP请求头默认上限(LimitRequestFields)是100。如果请求消息中头字段真超过了32个,Node.js也能处理,它会把已经解析的头字段通过事件kOnHeaders保存到JavaScript这边然后继续解析。 如果头字段不超过32个,http-parser会直接处理完并触发on_headers_complete一次性传递所有头字段;所以我们在利用Node.js作为web服务器时,应尽量把头字段控制在32个之内。
3. 过载保护
理论上,Node.js允许的同时连接数只与进程可以打开的文件描述符上限有关。但是随着连接数越来越多,占用的系统资源也越来越多,很有可能连正常的服务都无法保证,甚至可能拖垮整个系统。这时,我们可以设置http.Server的maxConnections,如果当前并发量大于服务器的处理能力,则服务器会自动关闭连接。另外,也可以设置socket的超时时间为可接受的最长响应时间。
性能实测
为了简单分析下Node.js引入的开销,现在基于libuv和http_parser编写一个纯C的HTTP服务器。基本思路是,在默认事件循环队列上监听指定TCP端口;如果该端口上有请求到达,会在队列上插入一个一个的任务;当这些任务被消费时,会执行connection_cb。见核心代码片段:
int main() {
// 初始化uv事件循环
loop = uv_default_loop();
uv_tcp_t server;
struct sockaddr_in addr;
// 指定服务器监听地址与端口
uv_ip4_addr("192.168.132.136", 3333, &addr);
// 初始化TCP服务器,并与默认事件循环绑定
uv_tcp_init(loop, &server);
// 服务器端口绑定
uv_tcp_bind(&server, (const struct sockaddr*)&addr, 0);
// 指定连接处理回调函数connection_cb
// 256为TCP等待队列长度
int r = uv_listen((uv_stream_t*)&server, 256, connection_cb);
// 开始处理默认时间循环上的消息
// 如果TCP报错,事件循环也会自动退出
return uv_run(loop, UV_RUN_DEFAULT);
}
connection_cb调用uv_accept会负责与发起请求的客户端实际建立套接字,并注册流操作回调函数read_cb:
void connection_cb(uv_stream_t* server, int status) {
uv_tcp_t* client = (uv_tcp_t*)malloc(sizeof(uv_tcp_t));
uv_tcp_init(loop, client);
// 与客户端建立套接字
uv_accept(server, (uv_stream_t*)client);
uv_read_start((uv_stream_t*)client, alloc_buffer, read_cb);
}
上文中read_cb用于读取客户端请求数据,并发送响应数据:
void read_cb(uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf) {
if (nread > 0) {
memcpy(reqBuf + bufEnd, buf->base, nread);
bufEnd += nread;
free(buf->base);
// 验证TCP请求数据是否是合法的HTTP报文
http_parser_execute(parser, &settings, reqBuf, bufEnd);
uv_write_t* req = (uv_write_t*)malloc(sizeof(uv_write_t));
uv_buf_t* response = malloc(sizeof(uv_buf_t));
// 响应HTTP报文
response->base = "HTTP/1.1 200 OK\r\nConnection:close\r\nContent-Length:11\r\n\r\nhello world\r\n\r\n";
response->len = strlen(response->base);
uv_write(req, stream, response, 1, write_cb);
} else if (nread == UV_EOF) {
uv_close((uv_handle_t*)stream, close_cb);
}
}
全部源码请参见simple HTTP server。我们使用apache benchmark来做压力测试:并发数为5000,总请求数为100000。
ab -c 5000 -n 100000 http://192.168.132.136:3333/
测试结果如下: 0.8秒(C) vs 5秒(Node.js)
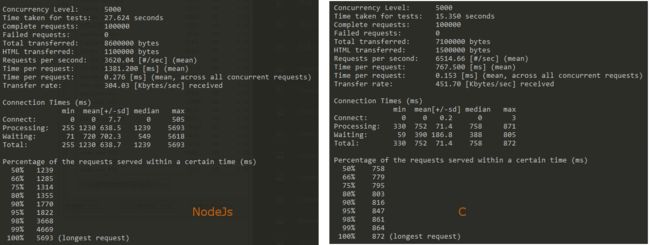
我们再看看内存占用,0.6MB(C) vs 51MB(Node.js)
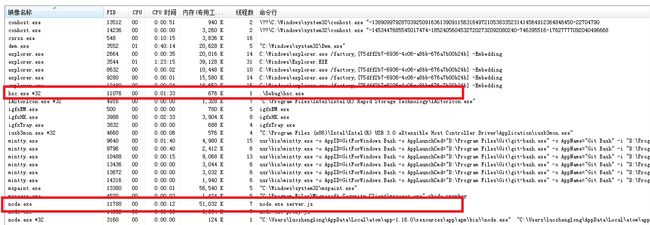
Node.js虽然引入了一些开销,但是从代码实现行数上确实要简洁很多。
更多关于Node.js的技术内容,请关注沪江技术学院微信公众号。
