在上一章我们主要从CPU如何执行指令的角度,学习了8086CPU的逻辑结构、合成物理地址的方法、相关寄存器以及一些常用指令。本意我们将从内存访问的角度继续学习几个重要的寄存器。
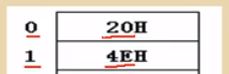
字(16位两字节),在内存中是如何存储的?
比如十进制数字20000(4E20H)在内存中的存储方式如下图示,假设是从地址 0 处开始存放的。即 4E20H 的低位 20H 是存放在低位 0 号存储单元的,高位 4EH 是存放在高位 1 号存储单元的。
什么是“字单元”?
重要结论:在内存中,任何两个连续的内存单元,N 号单元 和 N+1 号单元,可以把它们看成两个内存单元,也可以把它们看成一个地址为 N 的“字单元”(其中,N号单元就是这个“字单元”的低位字节单元,N+1号单元就是这个“字单元”的高位字节单元)。
什么是 DS 数据段寄存器?什么是[address]数据偏移地址?
CPU要读取一个存储单元中的数据时,必须得先给出这个存储单元的物理地址。在8086CPU中,存储单元的物理地址是由段地址和偏移地址合成而得到的。
在8086CPU中,DS寄存器,就是这个用于存放将要被访问的数据的段地址(可类比上一章中的 CS,CS寄存器是用于存放将要被访问的指令的段地址)。
DS数据段寄存器中的数据,就是当前 CPU即将要访问的数据所在存储单元的段地址。[address]数据偏移地址,用于配合 mov 命令从指定的偏移地址读取存储单元中的数据。
如何把存储单元中的数据送入到 CPU寄存器中呢?
要想把存储单元中的数据送往到CPU的寄存器中,需要使用 DS 数据段寄存器和 [address]数据偏移地址,再给 mov 命令来实现。看如下两个例子:
【例1】现在我们要读取 10000H 这个存储单元中的数据内容,该如何编程呢?(实现代码如下)
// 把 1000H 送到 bx 寄存器中
mov bx, 1000H
// 把 bx 寄存器中的值,赋给 ds 数据段寄存器
mov ds, bx
// 把 偏移地址为0 的存储单元中的值,赋给 al 低位寄存器
mov al, [0]
栗子解读,使用上面这三指令,即可把 10000H(1000:0)这个存储单元中的数据读取,并写入到 al 寄存器中。
解读“mov 寄存器N, [内存单元的偏移地址X]”这一指令:该指令的作用是把当前 DS 数据段中偏移地址为X的存储单元中的数据,赋值给指令的寄存器N。执行该命令时,8086CPU会自动地读取 DS 数据段寄存器中的值,并将其作为目标存储单元的段地址。
【例2】如何使用 mov 指令从 10005H 这一物理地址的存储单元中读取数据呢?(实现代码如下)
mov bx, 1000H
// 把 1000H 赋值给 ds 数据段寄存器
mov ds, bx
// 把 1000数据段中的偏移地址为5的存储单元中的值赋给 al 低位寄存器
mov al, [5]
栗子解读,这里要注意,在8086CPU中,不支持 把数据值 直接写入至段寄存器。如果想把某个值传递至段寄存器中,必须使用通用寄存器来过渡(数据 => 通用寄存器 => 段寄存器)。即 “mov ds, bx”是正确的,但“mov ds, 1000H”这是非法的,必须注意这个问题。
如何把CPU寄存器中的数据写入到存储单元中呢?
把 CPU 寄存器中的数据写入到存储单元,其逻辑和“把存储单元中的数据写入CPU寄存器”是一样的。看如下例子:
【例3】如何把 al 寄存器中的数据写入到物理地址为 20008H 的存储单元中呢?(代码实现如下)
mov bx, 2000H
// 让 ds 数据段地址等于 2000H
mov ds, bx
// 把 al 寄存器中的数据,写入到 段地址为2000H、偏移地址为8H的存储单元中
mov [8], al
字(16位两字节),在CPU寄存器和内存之间是如何双向传递的呢?
8086CPU是16位结构的,它有16根内部数据总线。所以对8086CPU来讲,可以一次性传送16位的数据,也就是一次性传送一个字。看如下代码:
mov bx, 1000H
mov ds, bx
// 把 数据段地址为1000H、偏移地址为0处的字单元(两字节)的字,写入到 ax 寄存器中
mov ax, [0]
// 把 cx 寄存器中的 16位数据,以“字”的形式写入到数据段地址为1000H、偏移地址为2处的字单元中
mov [2], cx
【例4】研究“字”在CPU寄存器和内存之间的传递方式,题目要求如下图:

解题思路,先使用 e 命令把源数据写入到 10000H ~ 10003H 内存中去;再使用 a 命令把汇编程序指令写入内存中去;最后使用 t 命令进行单步执行跟踪,从内存中读取汇编指令并执行,调试并查看 CPU 寄存器中数值的变化。实现代码如下:
// 第1步,把源数据写入到指定的物理地址的内存中去
e 1000:0 23 11 22 66
d 1000:0 // 查看源数据是否已写入内存
// 第2步,把汇编程序指令写到内存中去
a 2000:0
mov ax, 1000H
mov ds, ax
mov ax, [0]
mov bx, [2]
mov cx, [1]
add bx, [1]
add cx, [2]
// 第3步,更新 CS:IP 寄存器,以执行我们刚刚写入内存的汇编程序
r cs
2000
r ip
0
// 第4步,单步跟踪调试,并查看 CPU 寄存器中数据的变化情况
t // 单步执行 CS:IP 所指向的存储单元中的指令
本题考察的目的是提醒我们注意,在CPU寄存器与内存之间进行数据传递时,什么时候是以“字单元(16位)”的方式传递?什么时候是以“字节(8位)”的方式传递?结论很明显,这决定于 mov 命令所操作的寄存器,mov命令操作的是16位的寄存器,则数据传递是以“字单元”来传递的;如果mov命令操作的是8位的高位或低位寄存器(如 al、bh 等),则数据传递是以“字节”来传递的。
【例5】研究“字”在CPU寄存器和内存之间的传递方式,题目要求如下图:

解题思路,由题目中的汇编指令看,我们需要实现 CPU 寄存器和内存之间的双向数据传递。同上例4一样,我们首先把源数据写入内存,再把汇编程序指令写入内存,然后就可以单步执行、跟踪调试了。代码实现如下:
// 第1步,把源数据写入指定物理地址的内存处
e 1000:0 23 11 22 11
d 1000:0 // 查看源数据的写入结果
// 第2步,把汇编程序指令写入内存中
a 1000:200
mov ax, 1000
mov ds, ax
mov ax, 2c34
mov [0], ax
mov bx, [0]
sub bx, [2]
mov [2], bx
// 第3步,修改 CS:IP 指令指针的物理地址
r cs
1000
r ip
200
// 第4步,单步执行,跟踪调试
t
……
// 第5步,查看 1000:0 内存中源数据是否发生了变化
d 1000:0
说明,“mov [0], ax”的意思是把 ax 寄存器的数据以“字单元”的方式写入到 ds[0] 这个存储单元中去;“mov bx, [0]”的意思是把 ds[0] 这个存储单元中的数据以“字单元”的方式写入到 bx 寄存器中去;“sub bx, [2]”的意思是用 bx 寄存器中的数值减去 ds[2] 这个存储单元中的值,然后再写入到 bx 寄存器中去。
深入学习一下 mov 指令
有关于 mov 指令常用语法如下:
mov 寄存器,数据
mov 寄存器,寄存器
mov 寄存器,内存单元
mov 内存单元,寄存器
mov 段寄存器,寄存器
mov 寄存器,段寄存器
mov 内存单元,段寄存器
mov 段寄存器,内存单元
测试和验证“mov 寄存器,段寄存器”的正确性,测试代码如下:
// 向当前 CS:IP 指针指向的内存处写入汇编指令
a
mov ax, ds
// 执行当前 CS:IP 指针指向的内存单元中的指令
t
其它指令,可依次类推去测试和验证。关于对汇编指令的验证,其套路和思想都是一致的。
深入学习一下 add、sub 指令
add、sub 指令和 mov一样,都有两个操作对象,它们的基本语法如下图示:

什么是数据段?
在上一章我们已经知道,对于8086CPU机器,我们可以根据实际需要把一组地址连续的存储单元定义成一个“段”,这个“段”可以是“代码段”,也可以是“数据段”等。当一个“段”被 CS代码段寄存器指向时,则这个“段”就是“代码段”;当这个“段”被 DS 数据段寄存器指向时,则这个“段”就是“数据段”。
类比“代码段”的定义,我们可以给“数据段”也下一个定义:我们把一组长度为 N (N 不大于 64KB)、地址连续、且起始地址是16的倍数的一组存储单元拿来专门存储数据,那么这一组连续的内存空间就构成了一个“数组段”。(因为偏移地址的最大范围是 0000H ~ FFFFH,所以任何的“段”都不能大于64KB)
所谓的“段”就是用来存储资源的。“代码段”存储的是程序指令,“数据段”存储的是程序数据源。比如,我们用 123B0H ~ 123B9H 这一段内存来存放数据,那么这个“数据段”的段地址就是 123BH,其长度为 10字节。
CPU是如何访问数据段中的数据的呢?
将一段内存当作“数据段”,是我们在编程时的一种安排,我们可以在具体操作的时候,使用 ds 数据段寄存器来存放数据段的段地址,再根据需要,用相关指令来完成对数据段中具体存储单元的访问。示例如下:

事实上,CPU访问内存中的数据段,决定于 ds 数据段寄存器及其[address]偏移地址,即 ds[address]。所以,当我们要访问内存中某一个数据段时,我们需要先把 ds 数据段寄存器先设置成 目标数据段的段地址,再通过 [address] 偏移地址来访问某个具体的数据存储单元。
【例6】写几条指令,累加数据段中的前3个“字”型数据。
解题注意点,一个“字”在内存段中占用两个字节(1字节=8位)。实现代码如下:
mov ax, 123BH
mov ds, ax
mov ax, 0
add ax, [0]
add ax, [2]
add ax, [4]
阶段小结
1)“字”在内存中存储时,要用两个地址连接的存储单元来存放,“字”的低位字节存放在低地址单元中,“字”的高位字节存放在高地址单元中。
2)用mov指令访问内存单元中的数据,可以在 mov 指令中只给出 [address] 偏移地址,在读取内存单元中的数据时,CPU会默认取出 DS 寄存器中的数据作为数据段地址。DS[address] 即决定了数据存储单元的唯一性。
3)在内存和CPU寄存器之间传送“字”型数据时,高地址单元和高8位寄存器对应,低地址单元和低8位寄存器对应。比如 DS[0] 对应 AL低位寄存器,DS[1] 对应 AH 高位寄存器。
4)mov、add、sub三个指令,都需要两个操作对象。jmp 指令只有一个操作对象。对指令的测试使用,可以在 debug.exe 中进行实验。
什么是栈?
栈,是一种具有特殊访问方式的存储空间。它的特殊性就在于,最后进入这个空间的数据,将最先出去。
栈,有两个基本的操作:入栈和出栈。入栈,即把一个新的元素放到栈顶。出栈,即从栈顶取出一个元素。栈顶的元素总是最后入栈,但会最先出栈。
栈的操作规则,可简称为 LIFO(即 Last In First Out,后进先出)。
几乎所有的CPU都提供了“栈”机制
现今的CPU中,都有“栈”的设计。在8086CPU中,提供了相关的指令以“栈”的方式来访问和操作外部存储器(内存空间)。这意味着,我们在基于8086CPU编程的时候,可以将一段内存空间当作“栈”来使用。
8086CPU提供了入栈和出栈指令:PUSH(入栈操作)、POP(出栈操作)。
push ax // 把 ax 寄存器中的数据送入到栈空间中
pop ax // 从栈空间的顶部取出数据并送入到 ax 寄存器中
8086CPU中,入栈和出栈操作,都是以“字(两个字节16位)”为单位进行的。
【例7】测试如下汇编代码,执行完成后查看 ax、bx、cx寄存器中数据变化情况。实验如下:
mov ax, 0123H
push ax // 入栈:把 ax 寄存器中的数据放入栈顶
mov bx, 2266H
push bx // 入栈:把 bx 寄存器中的数据放入栈顶
mov cx, 1122H
push cx // 入栈:把 cx 寄存器中的数据放到栈顶
pop ax // 出栈:把栈顶的数据,赋值给 ax 寄存器
pop bx // 出栈:把栈顶的数据,赋值给 bx 寄存器
pop cx // 出栈:把栈顶的数据,赋值给 cx 寄存器
以过上面的一番栈操作以后,最终 ax = 1122H,bx = 2266H,cx = 0123H。
注意:在栈空间中,“字”型数据用两个连续的地址单元进行存储,高地址单元存放“字”的高8位数据,低地址单元存放“字”的低8位数据。通过上述实验,我们看到了栈操作的结果。但同时产生了两个疑问:如何知道一段内存空间被当作是栈?如何动态地知道栈顶元素的物理地址?
问题1:如何知道一段内存空间被当作是“栈”了呢?
在8086CPU中,SS 栈段寄存器所指向的内存地址段,就是“栈”空间。
问题2:如何动态地知道栈顶元素所在的物理地址?
在栈中,当前栈顶元素会随着入栈、出栈操作而动态变化。在8086CPU中,我们使用 SS 栈段寄存器来存放栈顶存储单元的段地址,使用 SP 栈指针寄存器来存放栈顶元素所在存储单元的偏移地址。即 SS:SP 所指向的存储单元,就是这个栈的当前的栈顶元素。
重要结论:在任意时刻,SS:SP 所指向的存储单元就是这个栈的当前栈顶元素。
执行 push、pop 栈操作时,到底发生了啥?
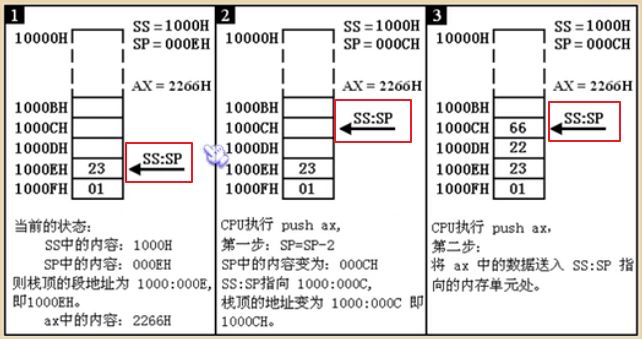
举例说明,当CPU执行 push ax 入栈操作时到底发生了什么?答:执行 push 操作时,SP 寄存器中的值会自动地减2,即栈顶元素的偏移地址减少2。然后,CPU将 ax 寄存器中的数据写入到 SS:SP 所指向的新的栈顶存储单元中去。因为栈操作是以“字”为单位的,所以 SP 每次变化量是2个索引。push 运行过程图解如下:
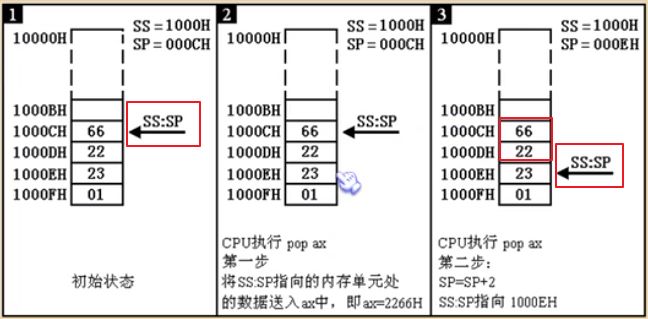
pop出栈操作和push入栈操作的过程是相反的,即每次执行 pop 操作时,CPU会先从 SS:SP 指向的栈顶地址处读取数据并赋值给寄存器,然后再将 SP 加2,即让栈指针的偏移地址加2。这里说明一下,事实上,pop操作,并没有从栈空间中把栈顶数据删除,而仅仅是把 栈顶元素的偏移指针增加了 2 而已。当下一次 push 时,上一次的栈顶数据会被覆盖掉。pop 运行过程图解如下:
【例8】如果我们把 10000H ~ 1000FH 这段空间当作栈,且初始状态下栈是空的,此时 SS = 1000H,那么 SP 等于多少呢?
题解:SP = 0010H。初始状态时栈中是没有数据的。所以 SP 偏移地址 = 栈空间最大偏移地址 + 1。图解如下:
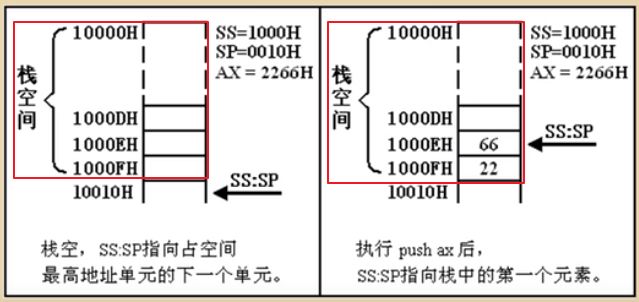
重要结论:如果一个栈空间的地址范围是 10000H ~ 1000FH,那么这个栈空间的大小就是 16字节,可以存放 8 个字。空栈时,SS = 1000H,SP = 0010H,且这个栈最底部的“字”单元的物理地址是 1000:000E(即 1000EH)。在任意时刻,SS:SP 都指向栈顶元素,入栈操作和出栈操作都不会改变 SS 栈段寄存器中的值,只会改变 SP 栈指针寄存器中的值。push操作时,SP先减去2,再把“字”写入栈;pop操作时,先从栈顶读取“字”并赋值给寄存器,再把 SP 加上2。
关于“栈顶越界”的问题探讨
SS栈段寄存器 和 SP 栈指针寄存器,动态地记录了栈顶“字”单元的物理地址,使用 SS:SP 可以实现入栈操作和出栈操作。但是,该如何能够保证在入栈、出栈时,栈顶不会超出栈空间的边界呢?
当栈空间已经满了的时候再使用 push 指令执行入栈操作,或者当栈空间已经为空栈了的时候再使用 pop 指令执行出栈操作,这两种情况下都会发生“栈顶越界”的问题。
“栈顶越界”是非常危险的。因为我们既然将一段内存空间安排为栈,那么在栈空间之外的空间里很可能存放着具有其它用途的数据或代码等,这些数据、代码可能是我们自己程序中的,也有可能是别的程序中的(毕竟在同一台计算机系统中,不是只有我们自己的程序在运行)。但是,由于我们在入栈出栈操作时的不小心,而将这些数据、代码意外地改写,就将会引发一连串的错误。
然而对8086CPU来讲,它并不能保证我们对栈的操作不会越界。也就是说,8086CPU只知道栈顶在何处(由 SS:SP 决定),而不知道用户安排的栈空间有多大。这就像 CPU 只知道当前要执行的指令在何处(由 CS:IP 决定)而不知道用户的指令代码有多少一样。(事实上,CPU就是这样,它只是知道当前要执行的指令在何处,只是知道当前栈顶在何处。)
如此看来,我们到底该如何规避“栈顶越界”的风险呢?答:当我们在编程的时候,要自己考虑栈顶越界的问题,要根据可能用到的最大栈空间来安排栈的大小,以防止入栈的数据过多而导致栈顶越界。在执行出栈操作时,也要注意,以防空栈后再次执行出栈操作而导致栈顶越界。通常,对于高级编程语言来讲,我们无须手动地设置或者关心栈空间的大小,因为高级语言的运行环境可以帮助我们完成这样的工作。
栈与内存的关系
栈空间是内存空间的一部分,栈空间只是一段需要以特殊方式(“先进后出”)进行访问的内存空间。
进一步学习 push、pop 指令的语法和特点
push、pop 指令,可以在寄存器和存储单元之间双向传送数据。这两个指令,不仅可以操作通用寄存器,还可以操作段寄存器和内存存储单元。栈操作是以“字”为单位的,即每次操作的数据都是两个字节共16位。
“push 寄存器” : 把寄存器中的数据 push 入栈
“pop 寄存器” : 把当前栈顶处数据写入到寄存器中
“push 段寄存器” : 把段寄存器中的数据 push 入栈
“pop 段寄存器” : 把当前栈顶处数据写入到段寄存器中
“push [address]” : 把一个 DS[address] 地址处的“字”push 入栈(栈操作是以“字”为单位的)
“pop [address]” : 把当前栈顶处的“字”写入到 DS[address] 地址的存储单元中
【例9】例题题目如下图

// 第1步,为 SS 栈段寄存器赋值,指明栈段的位置
mov ax, 1000H
mov ss, ax
// 第2步,初始化空栈,没有栈顶元素,设定 SP 栈指针的偏移地址
mov sp, 0010H
// 第3步,入栈操作
push ax
push bx
push ds
说明,为了能把数据存放到栈中,我们得先设定 SS 栈段寄存器,以确定栈段所在位置。再通过设置 SP 栈指针寄存器的初始偏移地址,以保证空栈。最后使用 push 命令,以完成入栈操作。(这里要注意,我们不能直接把一个数值赋值给 段寄存器,必须借助于通用寄存器来完成 段寄存器 的数据写入。)
用栈空间来暂存CPU寄存器的数据时,出栈的顺序必须要和入栈的顺序相反,因为最后入栈的数据处在栈顶位置,它会最先出栈。
push、pop 指令实质上一种内存传送指令,可以在CPU寄存器和内存之间进行双向的数据传送。与 mov 指令不同的是,push和pop指令访问栈存储单元中的数据,其物理地址不需要在指令代码中显示给出,而是默认由 SS:SP 栈指针寄存器指定的。另外需注意,每次执行 push 或 pop 命令时,CPU都会自动更新 SP 寄存器中的值,以保证栈指针时时刻刻都指向栈空间的栈顶元素。
SP 栈指针寄存器所表示的偏移地址,最大的变化范围是 0~FFFFH,所以一个栈最的容量空间为64KB。改变SP后写内存是入栈;读内存后改变SP是出栈,这就是8086CPU所提供的栈操作机制。
阶段小结
1)8086CPU提供了栈操作机制,这种机制可简单描述如下:在 SS:SP 这两个寄存器中分别存放 栈顶的段地址和偏移地址,并提供了入栈和出栈指令,它们根据 SS:SP 指示的栈顶地址,按“先入后出”的方式对栈存储空间进行访问操作(读写数据)。
2)其中,push指令的运行步骤是:先让 SP = SP - 2,再向 SS:SP 指向的栈顶字单元中写入数据。
3)其中,pop指令的运行步骤是:先从 SS:SP 指向的栈顶字单元中读取数据,再让 SP = SP + 2。
4)在任意时刻,SS:SP 都指向栈空间中的栈顶元素。
5)8086CPU只会记录栈顶的物理地址,并不会管理栈空间的大小。为了避免“栈顶越界”带来的风险,我们在编程时需要自己注意栈空间的容量大小。
6)当我们用栈来暂存以后还需要恢复的寄存器中数据时,寄存器出栈的顺序必须要和入栈时的顺序相反。
7)栈,是一种非常重要的机制,一定要深入理解并灵活掌握。
什么是栈段?
我们已经知道,对于8086CPU,在编程时,我们可以根据需要,把一组连续的存储单元定义为一个“段”。和“代码段”“数据段”一样,我们也可以定义“栈段”。
把长度为 N(N不大于64KB)的一组地址连续、起始地址为16倍数的一组存储单元,当作“栈”来使用。这就是“栈段”的定义。
把一段内存当作“栈段”,仅仅是我们在编程时的一种安排而已,CPU并不会因为这种安排,就在执行 push、pop等栈操作时就自动地把我们定义的栈段当作栈空间来访问。事实上,无论我们怎么安排,CPU只是认识 SS:SP 所指向的栈顶单元。CPU只能看到栈顶的位置,它并不知道栈的起始位置和结束位置在哪里。
如何访问一个栈段呢?
使用 mov 相关命令,把 SS:SP 指向这个栈段的栈顶位置,再使用 push 和 pop 命令即可开始访问这个栈段。一个空栈的 SP 等于多少呢?答:空栈的 SP = 栈空间最大存储单元的偏移地址 + 1。换个角度,可以像下图示进行理解:

本章小结
我们可以用一个内存段来存放数据,这就是“数据段”,我们可以使用 DS[address] 来访问数据段中存储单元。
我们可以用一个内存段来存放代码,这就是“代码段”,我们可以使用 CS:IP 来读取代码中程序指令。
我们可以把一个内存段当做“栈”,这就是“栈段”,我们可以使用 SS:SP 来访问栈段中的栈顶元素。
可见,不管理我们如何安排,CPU总是会把内存中的某段内存当作是代码段,这是因为 CS:IP 指向了那里;CPU总是会把内存中的某段内存当作是栈段,这是因为 SS:SP 指向了那里;CPU总是会把内存中的某段内存当作是数据段,这是因为 DS[address] 指向了那里。
我们一定要清楚,什么是我们的安排,以及该如何让 CPU 依照我们的安排来行事。我们要非常清楚 CPU 的工作原理,才能更有效地控制 CPU 依照我们的安排来运行。
一段内存空间,可以既是代码的存储空间,又是数据的存储空间,还可以是栈空间,也可以什么都不是。关键在于 CPU 中的寄存器是如何设置的,即 cs、ip、ss、sp、ds 的指向。理论上讲,一段内存空间可以同时是代码段、数据段和栈段,但这样做会导致程序的冗杂,所以我们一般并不推荐这样做。
本章完!!!