
Why
- 说到机器学习,前段时间的AlphaGo把它推向了舆论的高峰,这项技术也是一直被看好的未来趋势所在。各项领域也是在摩拳擦掌,想通过与AI的结合提升自己的核心竞争力。
- 互联网金融领域也毫不例外,对于金融的本质——风控更是如此。当然目前也有很多标榜自己为FinTech的公司也在借机炒概念,也有很多机器学习的负面消息,比如理想和现实还存在很大的差距等等。不过技术无所谓利弊,问题在于人的使用,如何将AI与风控相结合并发挥出其积极作用也一直是在探索的问题。
- 目前自己正在负责风控技术这块,一直在学习、实践和探索如何通过技术手段来提高风控效率,毕竟作为技术人来说,只是支撑好业务并没有什么成就感而言,能驱动并且引领业务提升整个业务效率才是make a diffrence,才能对得起FinTech这个词。当然在没有特别大的数据支撑的前提下,机器学习可能并不会很好的发挥其作用。在这之前有很多要做的事情,不过既然对此领域已经产生了兴趣,自己还会在闲暇时间趁热打铁一直坚持学习下去。
How
- 初识机器学习,相信很多人都是推荐Andrew在Coursera上的《机器学习》课程。我也毫不例外的加入了此阵营。吴老师(Andrew中文吴恩达,这里尊称吴老师)是人工智能领域公认的大师,大师就是能把一个非常复杂的概念深入浅出的描述的非常清晰,所以这里我也非常推荐这门课程作为入门首选。
- 当然选这门课要有两个基本前提:一是英语要过关,这里的一切都是英文,虽然有中文字幕,但是也不建议用中文字幕,因为这里会涉及到很多专有名词,长期看中文字幕对于课件或者作业中的词会比较吃力。二是线性代数、微积分和概率统计,机器学习中涉及到的基本都是各种数据模型和公式,如果没有好的数学基础也会比较吃力。
- 个人认为掌握一项技能,只是听懂或看懂了理论知识只能说达到了十分(满分一百分的话),因为这些理论还是闲散的存储在你的大脑里,并没有形成一种知识体系。还好吴老师的这门《机器学习》每章都会有个测试,并且还有动手编程完成的作业。我觉得当你把这些测试通过,把这些编程作业完成之后,这些闲散的知识点就会拼接在一起,这个程度之后就可以拿到五十分。那么如何把这些知识转换为自己的技能,就需要总结或者把它讲述给别人,这时候这些知识才属于你自己,才可以拿到及格分六十分。之后你就可以带着这些技能来解决实际问题。在这之后六十分到一百分的过程中,每增加一分都是比较困难的。就像田教授(我研究生时的一位挚Ji友You,外号在他本科时由于某种特征得名)目前从事机器学习领域说的那样,一个机器学习模型在准确率从60%提升到70%的时候很容易,但是再往上每提高一个百分点,都是件特别困难的事情。说了这么多,写本文的核心目的就是在总结已经掌握的知识点,把这些知识点变为自己的技能。
What
吴老师的这门《机器学习》分为11周,本想学完一半或者全部学完之后再来总结,不过第三周结束的时候吴老师说了这么一段话:
When I walk around Silicon Valley, I live here in Silicon Valley, there are a lot of engineers that are frankly, making a ton of money for their companies using machine learning algorithms. And I know we've only been, you know, studying this stuff for a little while. But if you understand linear regression, the advanced optimization algorithms and regularization, by now, frankly, you probably know quite a lot more machine learning than many, certainly now, but you probably know quite a lot more machine learning right now than frankly, many of the Silicon Valley engineers out there having very successful careers. You know, making tons of money for the companies. Or building products using machine learning algorithms. So, congratulations. You've actually come a long ways. And you can actually, you actually know enough to apply this stuff and get to work for many problems. So congratulations for that.
总结下来就是前三周的学习已经算个基本入门,可以用现有的模型和算法去解决很多实际问题了。
好了,废话了这么多,开始进入正题。
Lecture1 概述
引言
机器学习:来源于人工智能领域,计算机的一项新能力。
目前的应用比较广泛:
- 数据挖掘领域:从目前爆炸性增长的信息中提取有价值的信息用于用户推荐、医疗记录以及生物技术中。
- 不能手动编程的应用程序:自动直升机、手写识别、自然语言处理及计算机视觉。
- 定制化的程序:Amazon、Netflix等用户定制化的产品推荐。
- 理解人脑学习。(美国的科幻电影让我们领略到了人工智能未来的无限遐想)
Marching Learning Definition 什么是机器学习
Tom Mitchell 提供一个现代化的定义(也有些啰嗦):
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."
一个程序被认为是能从经验E中学习,解决任务T,达到性能度量值P,当且仅当有了经验E后,经过P判断,程序在处理T时性能有所提升。
我们拿下棋举例:
- E为下了多盘棋的经验。
- T为下棋的任务。
- P为赢得下场棋的概率。
机器学习的算法大概分为两类:
- 监督学习
- 非监督学习
Supervised Learning
监督学习
在监督学习中,已经提供给我们一批数据集,并且知道正确数据长什么样子,只需要找出输入和输出存在什么样的关系。监督学习也可以分为两类:
回归问题是我们可以在一个连续性输出中预测结果,意味着通过一个联系函数可以关联输入和输出值。比如通过一张照片的各种特征值来预测这个人的年龄。
分类问题是我们要预测出来的值分散在各个结果的集合中。比如通过看一个病人的肿瘤来预测这个肿瘤是良性还是恶性。
Unsupervised Learning
非监督学习
在非监督学习中,我们解决的问题通常不知道结果长什么样子,我们要从一些我们并不知道变量效果的数据中抽取出结构。通常做法是通过这些变量的关系来聚类。
比如有一百多万种基因,找到一种方法可以通过各种类似有关联的变量把他们自动分类,这些变量包括生命周期、位置、角色等。
Lecture2 Linear Regression with One Variable
Model Representation
我们的目标就是给到一组训练集,通过一个函数h:X->Y,使得h(x)是一个“好的”预言家给出相应的Y值。我们把h称作hypothesis假设函数。

直观一点我们用波特兰的房屋价格举例,图中的红叉为具体的训练集,X为房屋面积,Y为价格,得出h(x) = θ0 + θ1*x,之后我们通过一个具体的面积就能推断出它的大概价格了。

Cost Function
从上面的例子可以看出,怎么算出θ0和θ1的值是关键。这里就引入了Cost Function消耗函数的概念。

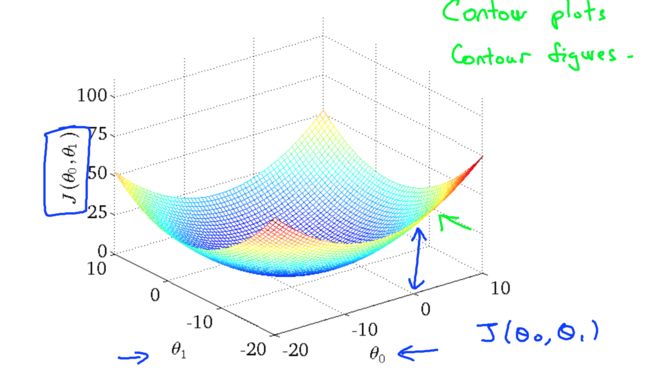
这里就涉及到具体的数学公式了,大概的意思就是我们的目标就是使得通过h推导出来的值和真正的y值越接近越好,这里引入了方差,通过计算我们所有的训练集,得出来使得J(θ0,θ1)最小的θ0和θ1。

线性回归力最重要的几个公式如上图所示,具体的推导就不在这里赘述了。为了更形象的展示其中的关系,这里也通过大量的训练集画出了θ0和θ1及J(θ0,θ1)的具体关系:
Gradient descent
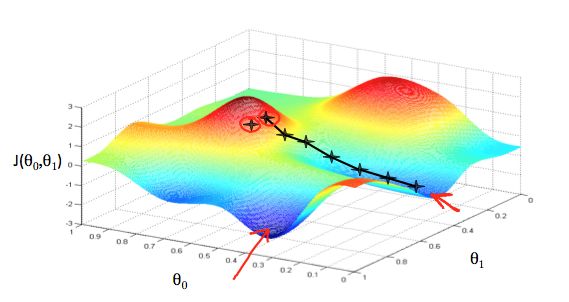
现在我们已经有了假设函数,我们也有方法来评估它到底有多合适。现在我们需要估算假设函数中的具体参数值了,这里我们就要引入Gradient descent梯度下降算法了。
因为θ0和θ1我们可以随意取值,所以你不可能穷举所有的值来得出最小的消耗函数,所以我们就要从一个初始值入手,那么如何从一个初始值找到那个最优解,我们就要用到gradient descent算法。
这个算法用一个公式来表达就是:
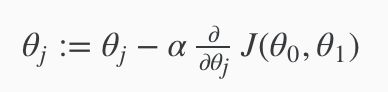
后面的部分其实就是求J的偏导数,导数的目的就是要找到向下的方向的下一个值,通过不断的迭代,到达最小的值。其中的α为学习速率,如果值太小,会迭代很多次才能找到最小值;如果值太大,有可能跳过最小值,最后找不到最小值。
最后把前面的J公式套入的话,得出最终的Gradient Descent算法:
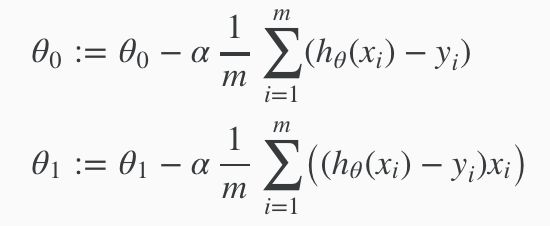
Lecture3 Linear Algebra Review
本章主要复习下线性代数的基础,这里不做赘述。
Lecture4 Linear Regression with Multiple Variables
Gradient descent for multiple variables
这章开始进入多元变量的线性回归,前面的一元线性回归更多在于让我们更好的理解,到了这章才比较接近事实。因为每一种模型都要经过更多维度的分析才有好的效果。

多元意味着有多个θ,这里就要同时迭代多个维度。
Feature Scaling
前面我们说到了α学习速率的问题,在实际应用中,不仅学习速率会影响迭代速度,变量的范围也会影响。这里就引入了特征缩放的概念:

其中的μi为特征X中的平均值,Si为特种X中的最大值减去最小值。
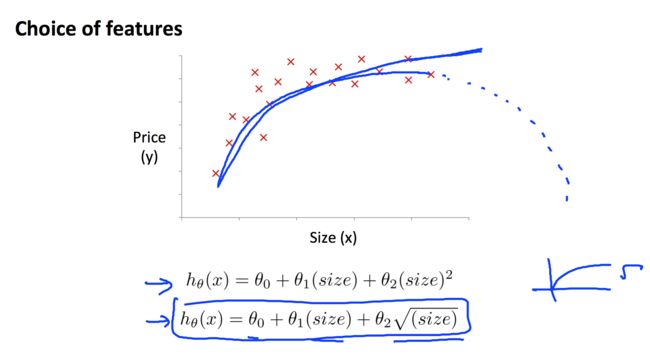
Features and Polynomial Regression
在实际应用中通过观察数据集的规律,并不一定得出线性的假设函数,这时我们就有可能通过引入特征及多项式回归来尽可能拟合数据集。例如下图:
Lecture5 Octave Tutorial
这章开始我们要通过编程手段来解决实际问题了,这里推荐使用Octave,它可以说是一个轻量级的MATLAB,支持各种数据运算。本章主要讲述如何使用,个人认为这章可以快速略过,这章我就走个过场,在实际编程中,不熟悉的语法直接Google。
第一次的编程作业比较简单,主要是熟悉Octave工具,以及用它来实现CostFunction和Gradient Descent。通过完整的事例来展现如果通过Octave来解决实际问题。
Lecture6 Logistic Regression
Classification
逻辑回归主要是解决分类的问题,这类的问题在第一章已经介绍过,这里不再赘述。
Hypothesis Representation
我们可以先忽略y是离散值的事实,用老的线性回归算法来预测y。但是这个方法表现的并不好,为了修正我们改变下假设函数的形式,这里用我们用到Sigmoid Function S型函数也就是Logistic Function 逻辑函数
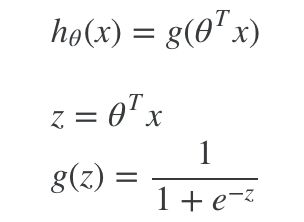
S型函数如下所示:

这里假设函数得出的值不再反应的是具体值,而是结果为1或者0的概率。如下公式:
hθ(x) = P(y=1|x;θ) = 1−P(y=0|x;θ)
P(y=0|x;θ) + P(y=1|x;θ) = 1
Decision Boundary
Decision Boundary 决策边界就是来分割y=0和y=1的分割线,由假设函数得来。下面两个图分别为线性和非线性的决策边界。


Cost Function
如果继续沿用线性回归的消耗函数,逻辑回归的问题会展现出很多小的波浪,导致许多部分最优解,而拿不到最优解。这里消耗函数换了一种表现方式:
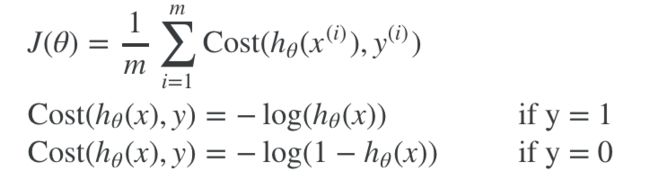
为什么取这样的消耗函数主要是为了表达这样的概念:
Cost(hθ(x),y)=0 if hθ(x)=y
Cost(hθ(x),y)→∞ if y=0andhθ(x)→1
Cost(hθ(x),y)→∞ if y=1andhθ(x)→0
Simplified Cost Function and Gradient Descent
上面的消耗函数最终可以压缩成一句公式:
Cost(hθ(x),y) = −ylog(hθ(x)) − (1−y)log(1−hθ(x))
完整的公式如下:
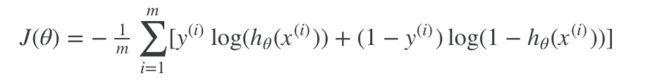
Gradient Descent公式与线性回归是一样的。
Advanced optimization
这里又介绍了几个其他算法:
- Conjugate gradient
- BFGS
- L-BFGS
这几个算法的优点就是不用手动的设置学习速率,而且更快。缺点就是太复杂,大师建议不要用。。
同时Octave工具又封装好了一些函数提供更方便的计算,比如你只要写如下一个简单的函数:
function [jVal, gradient] = costFunction(theta)
jVal = [...code to compute J(theta)...];
gradient = [...code to compute derivative of J(theta)...];
end
然后我们就能用Octave的fminunc()优化算法和optimset()函数来创建一个object包含我们想要给fminunc()的options
options = optimset('GradObj', 'on', 'MaxIter', 100);
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);
Lecture7 Regularization
The Problem of Overfitting
实际应用中常常会出现过度拟合的问题。

如第三幅图所示,我们用过多特征来完全拟合当前现有的数据集,得出来的假设函数并不能准确的预测出之后的趋势。这就是过度拟合的问题。那么如何解决呢:
减少特征的数量:
- 手工选取保留哪些特征。
- 用模型选择算法。
正则化
- 保留所有的特征,但是减少θj的量级。
- 当我们有许多不是很有用的特征时,正则化会表现的很好。
Cost Function
我们可以减少一些参数的权重通过增加他们的消耗,总结出来的消耗函数公式为:

λ正则化参数,它决定参数需要扩充多少消耗。
Regularized Linear Regression
正则化线性回归后的Gradient Descent:
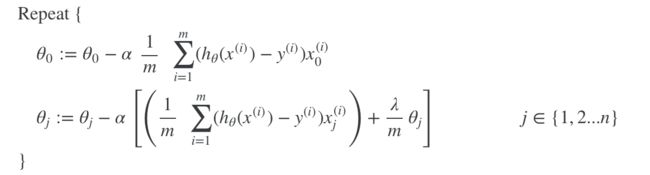
Regularized Logistic Regression
正则化后的逻辑回归消耗函数:
正则化后的逻辑回归Gradient Descent:

关于逻辑回归的编程作业大概也是计算各种Cost Function和Gradient Descent函数,由于逻辑回归稍微复杂一点,所以函数可能要多花点调试的时间。特别是要好好看下Octave提供的fminunc函数,之后解决实际问题直接用此函数即可。
Conclusion
到目前为止已经掌握了线性回归和逻辑回归两种模型以及梯度递减的算法,算是迈出了一个台阶。
路漫漫其修远兮,吾将上下而求索!