1.前言
上一章讲了提供给数据库的格式,以及取出来的机制
这一章讲解如何存储数据,如何获取到需要的数据
首先看看两大存储引擎家族:log-structed存储引擎和page-oriented存储引擎如b树
2.数据库的数据结构
2.1简单demo引入键值对数据库
文章写了一个很简单的数据库
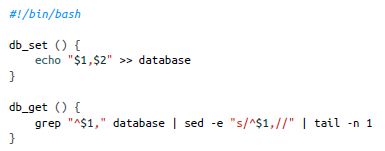
实现了一个键值对的存储
存储上:key,value用逗号分开(不考虑转义等),key,value都可以是任意的东西比如json串
写同一个key的时候,老的记录并不会覆盖,只是会添加一个最新的记录
查询时:会找到一个key的最后一个值
很多数据库内部也会用到一个append-only的log
上述实现中,查找一个key的时间是O(n)的,需要优化
2.2索引
会讲解几种索引结构,进行比较。
索引就是
从原始数据派生而来,记录额外的元数据,作为路标,帮助定位想要的数据
如果需要不同的方式查询,可能需要利用数据的不同部分(字段)来实现索引
数据库允许添加和删除索引,并不会影响存储的内容,只会影响查询和更改的效率
维护额外的结构会导致开销,尤其是写操作。任何类型的索引都会减慢写速度,因为每次写入数据时也需要更新索引。
因此如何选择索引是一个trade off:索引能够加快查询速度但是使得写操作变慢
2.2.1 hash索引(log-structed)
hash就不介绍了
最简单的hash索引实现方式就是,有一个内存的hashmap,记录每个key在data file中的位置。
如下图
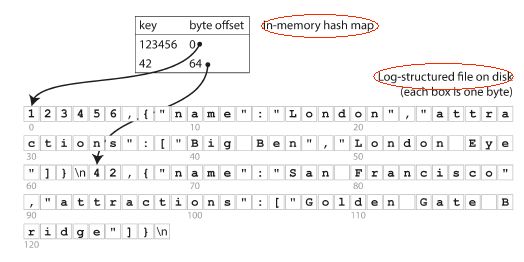
写时:同时更新内存hashmap,更新key对应的位置,以及更新data file,把对应的value给改掉
读时:根据hashmap找到data file对应的位置,进行读
这里引入一个问题:一直是append一个file(data file),如何避免最终磁盘空间不够
(书里面略微不准确,应该是减缓耗尽空间的速度)
一个方法是把log分成多个固定大小的segment
每次当一个segment写满了之后,后续记录写如下一个新的segment file.(之前读zk,rocket mq源码也有类似思路)
然后利用压缩的方法,去掉log中重复的记录

压缩会使得segment更小(假设有duplicate),那么还可以在压缩的同时,对segment file进行merge,成为一个合适大小的新的segment file,注意frozen segment file的读写控制即可

现在,每个segment file都有一个内存的hash表,记录每个key在当前file中的位置
查时:根据segment file的先后顺序,依次看是否有key的记录,第一个file没有就看第二个(由于有merge过程,所有segment file数量不会很多)
真是的场景考虑的问题更多:
1.文件格式
csv不太合适,二进制比较合适
2.删除记录
删除记录也是append一个删除记录到file中(称为墓碑),合并时墓碑让处理进程丢弃这条key的记录
3.崩溃恢复
file的hashmap是在内存中的。重启的时候hashmap会丢掉。
最简单的方法是重启的时候重新读各个segment file为其生成hash map,但是重启太慢了。
其他方法是给各个segment file的内存hashmap做快照(就是持久化这个map,类比zk的snap),这样重启直接读取快照生成内存的hashmap,会快很多
4.部分写记录
数据库随时可能挂,比如写数据写到一半的时候,需要引入checksum,能用来校验数据
5.并发控制
写要严格有序,常见方法是一个进程写,多个线程同时读
append-only的log看起来似乎有点浪费:为什么update的时候不直接覆盖原有的记录而是append一条呢
有如下几个原因
append和segment merge都是顺序写,会比随机写更快,尤其在某些硬件基础上
并发和崩溃恢复用append only更简单,否则的话,update覆盖记录的话,崩溃了会造成一半旧数据一半新数据
merge策略避免了老的segment碎片化
hash索引的缺陷
1.需要内存hashmap,如果记录在磁盘上,IO损失大.如果key数量大,需要的内存大
2.范围查询不方便
2.2.2 SSTables和LSM-Trees(log-structed)
在上面的基础上加一个改动,要求存储的segment file是key有序的(后面再讲如何同时保证顺序写的前提)
这样就叫Sorted String Table(或者SSTables).这样相比hash索引有几个好处
-
file merge更快了
由于每个文件都是有序的,用类似归并排序的思想,每次从各个file里面中当前最小的key,挑出最小的(如果有多个,那么以最新的segment file为准),这样就能完成merge以及去重了(想想上面讲hash的时候,没有讲怎么merge,怎么去重),如下图所示
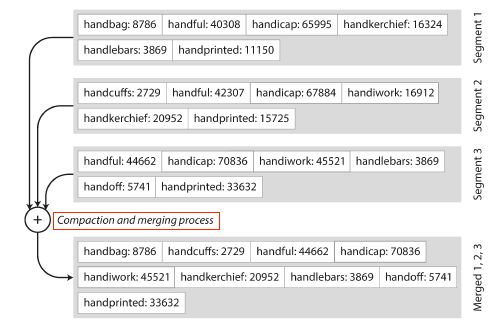 归并merge
归并merge -
查找一个key时,不需要把所有key的位置记录在内存中,节省内存空间
前面讲hash的时候,所有key的位置都要记住。
但是SSTables是有序的,所以一种实现方式是记录住一部分key的位置(比如位置之间相隔几kb)
查找的时候,由于已经有序,很容易知道key在哪一段中,再顺序查找下即可,如下图
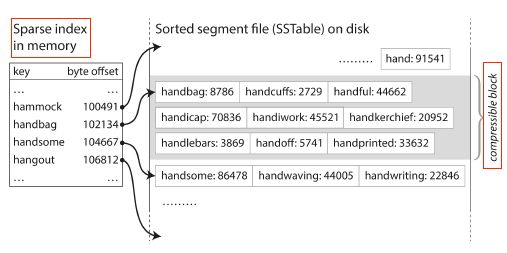 找handiwork就知道在handbag和handsome之间
找handiwork就知道在handbag和handsome之间 可以进行分组压缩,每个索引可以指向压缩块的起始点,来节省存储空间与减少I/O带宽的使用(不理解)
如何保证顺序写呢
回到上面忽略的问题,保证order的同时,要满足顺序写的前提
在磁盘上实现是可行的(B树),但是在内存中维护更简单(红黑树,AVL树)
因此,综合来说,存储引擎如下即可
- 有一个内存的树结构如红黑树等等,常被称为memtable(内存表)
- memtable大小达到阈值之后(如几M)就持久化到SSTable file中。作为最新的segment file(注意每个SSTable file就是一个segment file,参照上面 归并merge那张图)
- 查询时,先找memtable,再按时间顺序找segment file,
- 后台处理segment file的合并和压缩,处理overwrite以及delete数据
这里注意一个问题,查询的时候先查询memtable,它到了特定的size才会持久化为segment file
那么考虑宕机的问题,memtable会遗失。一次需要另外一个log,来记录每个append的记录。
主要是崩溃时恢复memtable用
LSM是什么
Log-structed Merge-Tree
简而言之,LSM树被设计来提供比传统的B+树和ISAM更好的写入性能。它通过消除随机的就地更新操作来实现这一点。上面讲思路的时候就有segment file的merge
用途:
用在level db和rocksDB里面,作为键值对存储引擎(不是关系数据模型)
许多数据库都是采用这样的思路来高效的处理数据,如Cassandra,HBase,LevelDB,Bitcask等。
Lucene的全文搜索的使用Elasticsearch和Solr索引引擎,也采用了类似的方法来存储它的词典
还有用bloom filter优化查询的一些方法,这里展开内容较多,参照refer和书中的refer去看一下
这里不展开了
2.2.3 B树(page-oriented)
最广泛应用的当然是B树了。在关系,非关系数据库中都应用广泛。
B树索引将数据分成固定大小的块或页,通常为4KB大小(有时更大),每次读或写都基于页的大小。这种设计更接近于底层硬件,因为磁盘也是按固定大小的页来排列的
每一页能用一个地址来标识,索引允许一页refer到另一页
不展开介绍如何搜索一个key了,看图就能明白
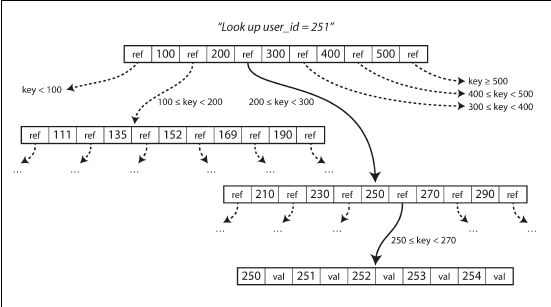
B树的算法保证树是平衡的(这样在页split时比较有用),这里不深入介绍算法
一页能只想多少个child页称为分支系数,一般是几百。
一个四层,每页4kb,分支系数为500的,能够存储256TB(500^4 * 4kb=232TB)
WAL(redo log):有些操作很危险,比如涉及多个page,为了避免crash,引入了redo log
锁存器(latches):为了应对并发,加入了锁存器,是一种轻量级锁
相关优化部分:不展开
2.2.4 LSM与B树比较
LSM写更快(顺序写入通常比随机写入快得多)
B树读更快(LSM有SSTable额外的数据结构需要读)
LSM优劣势
优势:
1.写吞吐
B树写两次:WAL以及树中的page
log-structed也要写多次(由于压缩以及SSTables的合并),会造成 "写放大",但是往往较小,使得写吞吐更高
顺序写比随机写快
2.磁盘空间
压缩的更好,产生的文件较小,而B树会留下一些space unused,因为碎片化的问题
劣势:
1.后台压缩的进程会干扰正在进行的读写,有时一个读写请求可能要等一个压缩进程结束才能执行
2.数据库越大,压缩需要的空间越大
3.要保证merge的速度比写请求的速度要快,否则unmerged segments越来越多
4.由于SSTable会存在同一个键值的多个副本,对于实现事务等对于一致性要求更高的场景,树型索引会表现的更加出色
2.2.5 其他索引结构
前面讲的都类似于primary key,这里讲一下二级索引,也是很常见的。
区别在于,一个key能够对应很多行而primary key只能对应一条记录
值存在索引中(可以参考 《高性能mysql》)
索引中的键值对,key使我们查询的东西,value则有两种形式:
实际的行 或者 指向实际的行
这里就引入了聚簇索引(索引和实际的行存储在一起) 以及 覆盖索引(索引和表中的某几列数据存储在一起)
多列索引(可以参考 《高性能mysql》)
R树:处理空间相关的数据,不展开
全文搜索和模糊索引
Lucene,利用类似SSTable的结构存储’字典‘,用编辑距离进行模糊查询等,不展开
内存数据库
如memcache,用来做cache,应用于即使断电了内存数据丢失了也没关系的场景
比磁盘操作快的原因是无需编解码相关的工作
3.事务处理还是分析
如果记录是基于用户的增删改,那么这种模式称为OLTP(online transaction process)
如果是基于原始记录进行一些聚合操作,如count,sum等等,这种模式称为OLAP(online analytic process)
区分如下

后面再介绍了相关的技术,背景等等,这里不展开了
4.总结
本章把存储引擎分类两大类:OLAP和OLTP(未展开)
OLTP中分为log-structed和page-oriented两大类
前者写快,后者读快
个人感觉这章仔细了解下几个分类,以及数据库的索引技术就好
思考
1.为啥zk,rocketmq数据传输要checksum之类的
就是处理 部分写记录 的问题,防止数据写一半挂掉了
2.真实数据库设计要考虑的各个问题
在2.2.1中提到的各个问题
3.索引结构的两大类
log-structed和page-priented
4.LSM与B树比较
问题
SSTables比hash的好处中的分组压缩
那里没有理解,没看出来哪里压缩了,感觉就是merge的时候去重去删除等等。
B树算法实现
不记得了,后面再看
future
看下LSM和SSTables相关的设计,big table的论文(书中refer 9)以及LSM-tree的最初思路(书中refer 10)
refer
LSM和SSTables相关调研
http://www.cnblogs.com/fxjwind/archive/2012/08/14/2638371.html
http://www.ituring.com.cn/article/19383
http://weakyon.com/2015/04/08/Log-Structured-Merge-Trees.html
https://leonlibraries.github.io/2017/04/13/%E5%88%9D%E6%B6%89HBase/
https://en.wikipedia.org/wiki/Log-structured_merge-tree
读书笔记
https://www.jianshu.com/p/fedcefc15fde