集合框架、generic泛型、List、Set、Map、Collections类
集合框架
数组和集合的区别:
1.数组既可以存储基本数据类型,又可以存储引用数据类型,基本数据类型存储的是值,引用数据类型存储的是地址值;
集合只能存储引用数据类型(对象)集合中也可以存储基本数据类型,但是在存储的时候会自动装箱变成对象;
2.数组长度是固定的,不能自动增长;
集合的长度的是可变的,可以根据元素的增加而增长;
数组和集合什么时候用?
1.如果元素个数是固定的推荐用数组;
2.如果元素个数不是固定的推荐用集合;
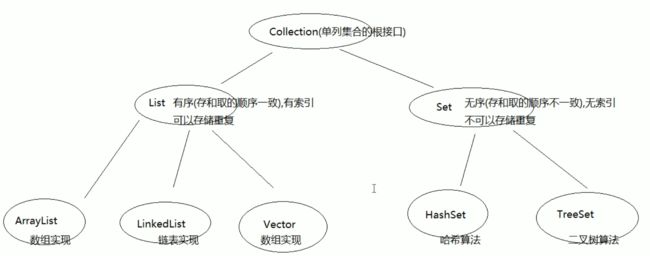
Set和List的区别
- Set 接口实例存储的是无序的,不重复的数据。List 接口实例存储的是有序的,可以重复的元素。
- Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet>。
- List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector> 。
- Collection类
Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。
boolean add(E e) // 添加指定元素
boolean remove(Object o) // 删除指定元素
void clear() //清空集合
boolean contains(Object o) // 是否包含指定元素
boolean isEmpty() // 是否为空
int size() //获取元素个数
toArray() // 把集合转成数组
boolean addAll(Collection c) // c1.addAll(c2) 把c2中元素添加到c1中
boolean removeAll(Collection c) // c1.removeAll(c2) 删除c1中c1、c2的交集
boolean containsAll(Collection c) // c1.containsAll(c2) c1是否包含c2全部元素
boolean retainAll(Collection c) // c1.retainAll(c2) 取交集,并将交集赋值给c1,如果c1改变了,返回true,否则返回false。(如果c1是c2的子集,返回false)
- 集合遍历
List list = new ArrayList();
list.add("Hello");
list.add("World");
list.add("HAHAHAHA");
//第一种遍历方法使用foreach遍历List
for(String str:list){ //也可以改写for(int i=0;i ite = list.iterator();
while(ite.hasNext())//判断下一个元素之后有值
{
System.out.println(ite.next());
}
- ArrayList
ArrayList arrayList = new ArrayList();
for (int i = 0; i < 10; i++) {
//添加元素
arrayList.add(i);
}
// 移除下标为1的元素 并将删除的元素返回
arrayList.remove(1);
// 移除指定元素 并将删除的元素返回
arrayList.remove("A");
// 返回指定元素的最小下标
arrayList.indexOf(3);
// 下标 0 - 3的元素
arrayList.subList(0, 3);
// 数组中元素个数
arrayList.size();
// 替换指定下标元素
arrayList.set(0, "V");
// 并发修改异常产生的原因及解决方案
List list = new ArrayList();
list.add("a");
list.add("b");
list.add("world");
list.add("d");
list.add("e");
/*Iterator it = list.iterator();
while (it.hasNext()) {
String str = (String) it.next();
if (str.equals("world")) {
list.add("javaee"); //这里会抛出ConcurrentModificationException并发修改异常
}
}*/
ListIterator lit = list.listIterator(); //如果想在遍历的过程中添加元素,可以用ListIterator中的add方法
while (lit.hasNext()) {
String str = (String) lit.next();
if (str.equals("world")) {
lit.add("javaee");
//list.add("javaee");
}
}
- ListIterator
boolean hasNext() 是否有下一个
boolean hasPrevious() 是否有前一个
Object next() 返回下一个元素
Object previous(); 返回上一个元素
- Vector
// 添加
Vector vector = new Vector();
vector.add("A");
vector.add(2);
vector.add(0, "C");
System.out.println(vector); // [C, A, 2]
Vector vector1 = new Vector(vector);
System.out.println(vector1); // [C, A, 2]
Vector vector2 = new Vector();
vector2.add("R");
vector2.addAll(vector); // 将vector中的所有元素添加到vector2中
vector2.add(vector); // 将vector添加到vector2中
System.out.println(vector2); // [R, C, A, 2, [C, A, 2]]
// 删除
vector2.remove(0); // 删除指定位置的元素
System.out.println(vector2); // [C, A, 2, [C, A, 2]]
vector2.remove("A"); // 删除指定元素的第一个匹配项,如果不包含该元素,则元素保持不变。
System.out.println(vector2); // [C, 2, [C, A, 2]]
vector2.removeAll(vector); // 移除包含在 vector 中的所有元素。
System.out.println(vector2); // [[C, A, 2]]
// 修改
System.out.println(vector); // [C, A, 2]
vector.set(0, "first");
System.out.println(vector); // [first, A, 2]
// 查询
vector.size(); // 返回vector中有几个元素
vector.isEmpty(); // vector是否为空
vector.get(1); // 查找指定索引位置的元素
vector.toArray(); // 将vector对象转换为数组
- LinkedList
实现单向队列和双向队列的接口,自身提高了栈操作的方法,链表操作的方法。LinkedList不擅长查询,尽量不要用index。
LinkedList linkedList = new LinkedList();
for (int i = 0; i < 10; i ++) {
linkedList.add(i);
}
// 链表的第一个元素
linkedList.getFirst();
// 链表最后一个元素
linkedList.getLast();
// 移除
linkedList.remove(0);
linkedList.removeFirst();
linkedList.removeLast();
// 如果不指定索引的话,元素将被添加到链表的最后.
linkedList.add(1, 0);
linkedList.addFirst("A");
linkedList.addLast("B");
// 获取元素下标
linkedList.indexOf(0);
// 替换指定下标元素
linkedList.set(0, "C");
- List的三个子类的特点
- ArrayList:
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。 - Vector:
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
Vector相对ArrayList查询慢(线程安全的)
Vector相对LinkedList增删慢(数组结构) - LinkedList:
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
查询多用ArrayList
增删多用LinkedList
如果都多ArrayList
generic泛型
泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
- 三种迭代的能否删除
普通for循环,可以删除,但是索引要--
迭代器,可以删除,但是必须使用迭代器自身的remove方法,否则会出现并发修改异常
增强for循环不能删除
ArrayList arrayList = new ArrayList<>();
arrayList.add("a");
arrayList.add("b");
arrayList.add("b");
arrayList.add("b");
arrayList.add("c");
// 普通for循环删除元素
for (int i = 0; i < arrayList.size(); i++) {
if ("b".equals(arrayList.get(i))){
arrayList.remove(i);
i --;
}
}
// 迭代器删除
// 方式一
Iterator iterator = arrayList.iterator();
while (iterator.hasNext()){
if ("b".equals(iterator.next())){
iterator.remove();
}
}
System.out.println(arrayList);
// 方式二
for (Iterator iterator1 = arrayList.iterator(); iterator1.hasNext();){
if ("b".equals(iterator1.next())){
iterator1.remove();
}
}
System.out.println(arrayList);
// 增强for循环(for - each)不能删除,只能遍历
- 可变参数
这里的变量其实是一个数组.
如果一个方法有可变参数,并且有多个参数,那么,可变参数肯定是最后一个.
格式:
修饰符 返回值类型 方法名(数据类型… 变量名){}
int[] a = {11, 22, 33, 44};
test1(a);
test(a);
test(1,2,3,4);
private static void test1(int[] arr){
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
private static void test(int ... arr){
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
- Arrays工具类的asList()
// 数组转换为List,不能增删元素,可以使用集合的其他方法
String[] arr = {"a", "b", "c"};
List list = Arrays.asList(arr);
Integer[] arrs = {1,2,3};
List list2 = Arrays.asList(arrs);
// 基本数据类型数组 转 List时,将整个数组作为一个对象存入List
int[] arra = {1,2,3,4};
List list1 = Arrays.asList(arra);
- List 转数组
ArrayList arrayList = new ArrayList<>();
arrayList.add("a");
arrayList.add("b");
arrayList.add("c");
// 当List转数组时,数组长度如果 <= List.size() ,转换后的数组长度等于List的大小
// 数组长度如果 > List.size() ,分配的数组长度就与指定的长度一样,会多几个null元素
String[] arr = arrayList.toArray(new String[0]);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
Set
- HashSet
一个按着Hash算法来存储集合中的元素,其元素值可以是NULL。无序的,不能重复存储。
HashSet set = new HashSet();
// add(value)方法,可以向set中添加一个元素
set.add("AA");
set.add("BB");
set.add("CC");
set.add(null);
// addAll方法,可以将一个集合整体加入到set中
HashSet sets = new HashSet();
sets.addAll(set);
// remove方法,可以删除指定的一个元素。
set.remove("BB");
// removeAll方法,可以从set中批量删除一部分数据。
sets.removeAll(set);
// clear方法,可以快速清空整个set。
sets.clear();
// size方法,获取set中元素的个数
set.size();
// isEmpty方法,判断set对象是否为空
set.isEmpty();
HashSet存储自定义对象,保证元素唯一性方法:
重写hashCode()和equals()方法:
编辑区 右键 Generate(Command + N),选择equals()and hashCode()
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Animal)) return false;
Animal animal = (Animal) o;
return age == animal.age && Objects.equals(name, animal.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
LinkedHashSet
底层是链表实现的,是set集合中唯一一个能保证怎么存就怎么取的集合对象.
因为是HashSet的子类,所以也是保证元素唯一的,与HashSet的原理一样.
允许null元素,并支持所有可选的Set操作。
像HashSet一样,LinkedHashSet不是线程安全的,所以多个线程的访问必须通过外部机制(如synchronizedSet(Set))进行同步。TreeSet
TreeSet集合是用来对象元素进行排序的,同样他也可以保证元素的唯一。
- 当compareTo方法返回0的时候集合中只有一个元素
- 当compareTo方法返回正数的时候集合会怎么存就怎么取
- 当compareTo方法返回负数的时候集合会倒序存储
使用方式
1.自然顺序(Comparable)
TreeSet类的add()方法中会把存入的对象提升为Comparable类型
调用对象的compareTo()方法和集合中的对象比较
根据compareTo()方法返回的结果进行存储
public class Person implements Comparable{
private String name;
private int age;
@Override
public int compareTo(Person o) {
int length = this.name.length() - o.name.length(); //比较长度为主要条件
int num = length == 0 ? this.name.compareTo(o.name) : length; //比较内容为次要条件
return num == 0 ? this.age - o.age : num;
}
}
2.比较器顺序(Comparator)
创建TreeSet的时候可以制定 一个Comparator
如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
add()方法内部会自动调用Comparator接口中compare()方法排序
调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数
两种方式的区别
TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序(没有就报错ClassCastException)
TreeSet如果传入Comparator, 就优先按照Comparator
- Map
将键映射到值的对象
一个映射不能包含重复的键
每个键最多只能映射到一个值
Map map = new HashMap<>();
map.put("key1", "value1"); // 如果存入的key存在,将被覆盖的值返回
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
System.out.println(map); // {key1=value1, key2=value2, key3=value3, key4=value4}
// Removes all elements from this Map
// map.clear();
// System.out.println(map); // {}
// Map中是否包含指定的key
map.containsKey("key1")
// Map中是否包含指定的value
map.containsValue("value1");
// Map中所有映射集合
map.entrySet(); // [key1=value1, key2=value2, key3=value3, key4=value4]
// 根据key获取元素
map.get("key2");
// 是否为空
map.isEmpty();
// key的集合
map.keySet();
// values集合
map.values();
// 移除key对应元素 返回值为删除的值
map.remove("key1");
// 集合元素个数
map.size();
- 遍历HashMap
// 方式一
for (String key : map.keySet()) {
System.out.println(map.get(key));
}
// 方式二 比方式一节约资源
for (Map.Entry en : map.entrySet()) {
String key = en.getKey();
Integer value = en.getValue();
System.out.println("key = " + key + ", value = " + value);
}
Collections类
ArrayList arrayList = new ArrayList<>();
arrayList.add("a");
arrayList.add("d");
arrayList.add("c");
arrayList.add("b");
// 排序
Collections.sort(arrayList);
System.out.println(arrayList);
// 二分法查找 返回下标 不存在返回负的插入点-1(负数)
int i = Collections.binarySearch(arrayList, "c");
System.out.println(i);
// 获取最大值
Collections.max(arrayList);
// 获取最小值
Collections.min(arrayList);
// 集合反转
Collections.reverse(arrayList);
// 随机置换顺序
Collections.shuffle(arrayList);
- 泛型固定下边界
?super E - 泛型固定上边界
?extend E