准备花三个月读完
个人背景介绍
本科与研究生都就读于南京大学计算机科学与技术系。研究生期间一直跟着老板(以及他的学生)在南大富士通做项目,做过一个税务系统(单机版,用Powerbuilder实现),也做过一个内部的订饭系统(Delphi+UDP广播),时间最长也是学到最多的一个项目是SPIF(Software Process Improvement Framework, http://www.fujitsu.com/cn/fnst/products/spif/)。当时加入项目组的时候,正好是荣国平师兄和尹俊他们做技术改造,从原来单纯的JSP改造为Struts,后面又改造为用Hibernate改造了,时间差不多是2003年左右。SPIF项目除了技术之外,对软件工程的一些东西也有所了解,CMM,CMMI,XP等,小论文写了一篇关于Risk Management(当时正在做),毕业论文则写了一篇如何自动化生产测试用例的(用DSL来描述,然后自动生成测试代码)。
2005年毕业之后,到了ZTE上海研发中心的网管开发部,主要做网络设备的管理软件。技术栈是J2EE,build工具是Ant。在软件工程这块印象最深刻的是三点:1)单元测试,代码和分支覆盖率要100%;2)Daily Build;3)DB Migration脚本(任何版本要对数据库做变更,必须要用用脚本)。系统组的杜玄他们用Ant写了一套完善的build脚本,每天晚上都会跑,如果跑失败就会通知大家。印象中那个时候还没有用持续集成的工具,都是自己手写的脚本。
为了避免喧宾夺主,在EMC的经历另外再表述。2015年从EMC离开,加入了麻袋理财,任首席架构师。
今天的背景主题:如何打造高效的互联网研发体系
加入麻袋理财之后,根据自己的观察,感觉很多互联网企业遇到的问题,不是架构的问题,也不是技术的问题,而是研发整个体系的问题。为此,根据经验和实战,总结了一个大纲版,先放出一些,供大家批评指正(看了《架构即未来》之后,发现自己的太浅薄了,后面需要大力完善)。








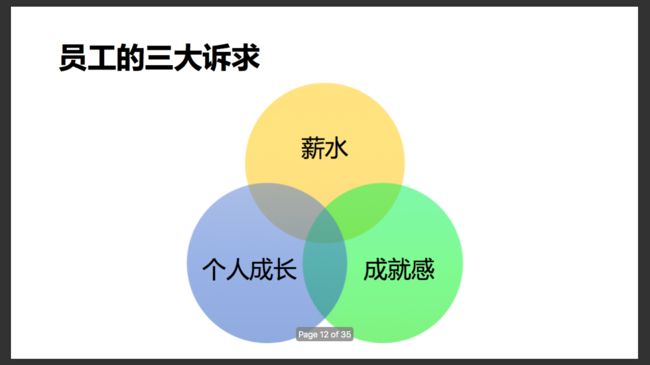


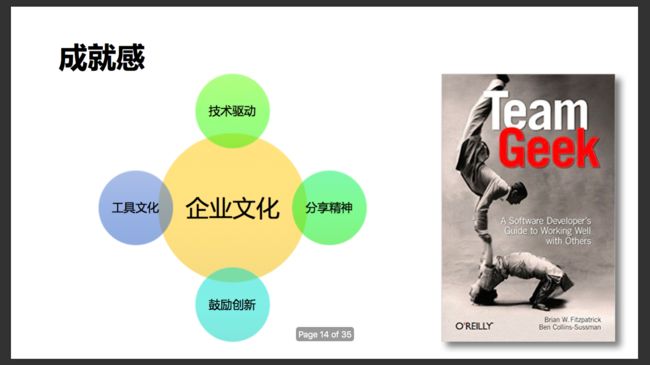


以上还只是个人比较粗浅的认识,除去“人”及管理这一部分外,今天的读书笔记主要集中在研发流程及过程管理上。做个小广告:http://www.zaih.com/mentor/84822170/, 欢迎大家来约谈如何打造互联网高效研发体系这一话题。
架构即未来第八章 管理故障和问题读后感
为了让系统7*24可用,我们都会和故障以及问题打交道。
故障:Incident,任何降低服务质量的事件都可以称之为故障。[麻袋理财的实践]故障级别一般可以根据影响的范围,时间,后果三个方面进行衡量。
问题:Problem,问题是故障的原因,例如代码的bug,生产环境网络问题等等。
事故管理聚焦在及时有效地恢复生产服务的过程;问题管理聚焦在确定问题的根源和解决问题的过程。这两者通常来讲是前后顺序的关系,但是有时候又会有冲突。定位问题,需要保留现场,不做任何恢复操作;而事故恢复则往往会破坏现场(例如重启),导致无法定位问题。因此我们需要制定一套最简洁的事故现场“证据”保留的方法,快速收集完之后就进入故障恢复。
在实施事故管理时,推荐使用如下DIRER流程:
D(Detect):通过监控或与客户联系检测事故。
R(Report):报告事故,记入负责跟踪全部事故、失效或其他事件的系统。
I(Investigate):调查事故以确定该做什么。
E(Escalate):如果事故在规定的时间内没能解决,尽快升级。
R(Resolve):通过恢复最终用户需要的功能和记录所有的信息,为解决事故做跟进。
为了第一时间发现问题及定位问题,我们需要一套完善的监控系统:
1、业务监控:比如系统各个功能的使用情况,数据的一致性情况等
2、应用监控:各个功能返回情况(如果是HTTP请求就看状态码,响应时间等),内部运行情况(例如异常情况等),外部依赖调用情况等
3、系统监控:CPU,内存,网络等运行情况
对于应用开发者,他们需要考虑应用的可监控性,例如:
1、应用运行状态
2、应用内部Metrics
3、应用必须提供一个简单的方式能够让监控系统获取相应信息,例如REST API。
对于这一点,大家可以参考Spring boot actuator (https://spring.io/guides/gs/actuator-service/)。