下面是一个爬豆瓣电影的简单爬虫,主要目的:能够在豆瓣电影上爬遍所有城市的正在上映电影;该小爬虫是基于urllib2和HTMLParser完成,有很多不足之处,欢迎大家讨论指正:
-----------------------------------------------------------------------------------------------------------------------------
1.思路:
从豆瓣电影-正在热映(https://movie.douban.com/nowplaying/shanghai/)的网页源码中可以看到所有的正在热映电影以下面的方式罗列出:
id="25894431"
class="list-item"
data-title="星球大战外传:侠盗一号"
data-score="7.4"
data-star="40"
data-release="2016"
data-duration="134分钟"
data-region="美国"
data-director="加里斯·爱德华斯"
data-actors="菲丽希缇·琼斯/迭戈·鲁纳/甄子丹"
data-category="nowplaying"
data-enough="True"
data-showed="True"
data-votecount="51049"
data-subject="25894431"
因此,可以通过找到页面中带有li...的标签来下载所有的正在热映电影信息;同时,从某个城市正在上映电影页面的URL中也可以看到,对于不同的城市只需要更改URL中带的城市名即可构建出对应城市的URL,因此我们只需要建立一个包含所有城市名的列表,然后对其进行遍历即可。
那么如何创建这个包含全国所有城市名的列表呢?从页面中我们可以看到在任意城市下都有一个切换城市选项,对应到源码中就包含了所有城市名的列表:
a class="city-item" href="javascript:;" id="118190" uid="anqing"安庆
a class="city-item" href="javascript:;" id="118244" uid="anyang"安阳
a class="city-item" href="javascript:;" id="118125" uid="anshan"鞍山
a class="city-item" href="javascript:;" id="118421" uid="aletai"阿勒泰
...
因此我们只需要找到带有a...的的标签,并且对应到key为uid的一项,就可以把所有城市名找到,并放到一个列表里面来完成城市的遍历。
按照这个思路,我们的程序只需要准备两个HTMLParser,一个负责抓电影信息,一个负责抓城市信息即可(其实也可以只有一个HTMLParser集成这两个功能),在Main函数里进行城市的遍历和打印每个城市对应的正在上映电影即可。
2.代码分析:
Part 1.负责遍历电影的HTMLParser:

首先创建一个Moive_List用来装提取出来的某个城市的正在上映电影信息;然后重写handle_starttag函数来找到tag = li...的内容;然后我们通过got_data函数把找到的属性data-score和data-title里面的信息提取到一个叫moives的列表中,这就完成对一部电影的处理;通过遍历所有带有li...的标签就可以遍历该城市下所有的电影,最后把每条处理的电影信息都存在Moive_List这个列表中。注意要用 self.MoiveList 才可以在整个class中去修改这个列表。
注意并不是所有的tag = li...都对应有电影信息,比如这个li class=""就没有对应任何电影信息。因此我们还需要添加一个if来判断每个li... tag下得到的moives列表是否是我们需要的;如果moives下面没有电影信息,这个moives列表就应该为空,所以可以通过moives列表的长度来去掉空的moives
最后定义一个返回Moive_List的函数,就完成了对一个城市的电影列表的爬取
Part 2.负责遍历城市名的HTMLParser:
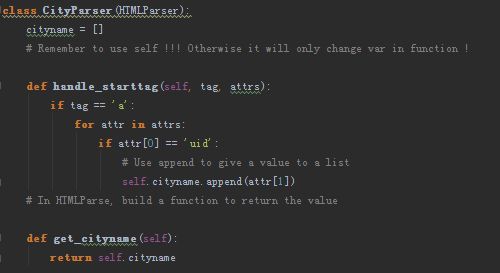
与前面的Parser一样,只是我们寻找a...的标签,然后找到属性uid里面的信息并提取到cityname这个列表中;最后同样定义一个返回cityname的函数即可
Part 3. Main函数:
Main函数首先初始化一个MoiveParser和CityParser,然后通过urllib2.request请求任意一个城市的正在上映电影页面,将该页面用parser.feed ()方式给到CityParser中,处理得到城市名字的列表,然后可以构建一个不同城市的URL列表(只需要更换URL最后的城市名即可)
之后用for循环依次访问每个城市对应的URL,并将页面内容用feed方式给MoiveParser,从MoiveParser返回每个城市的正在热映电影名和得分,写入到一个TXT中。同时还可以通过加计数值返回当前的遍历进度
值的注意的是,由于Python对中文不太友好,因此访问中文页面时经常需要处理中文导致的乱码(其实是UTF-8编码)问题,总结如下:
a.对于string或者list,可以通过str.decode('utf-8','ignore').encode('gbk','ignore')的方式进行处理,注意list需要用list.readline()或for str in list:的方式来将list中的每个字符串依次decode('utf-8','ignore').encode('gbk','ignore')
b.对于字典的处理,可以直接用json的方式json.dumps( dict, encoding = 'UTF-8', ensure_ascii = false )来进行中文字符处理
-----------------------------------------------------------------------------------------------------------------
特别鸣谢 douban.com 提供的爬虫练习环境 :)
源代码:如果有兴趣可以留言索取 :)