- Cause I don't have a Weibo account, so the homework will be recorded here.
Target
Get all categorical datas in the bottom on page.
Detailed instructions are shown below.

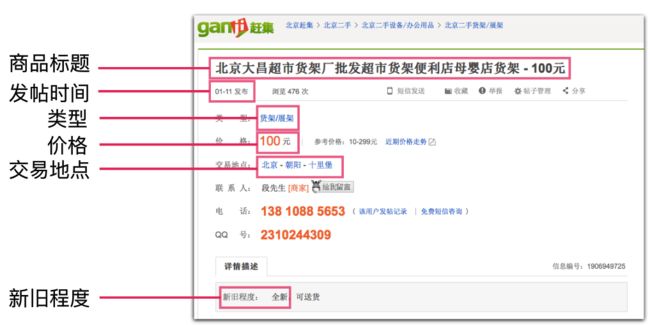
** Tips **
1 You do not need to crawl irregular page.
2 Strongly recommended to use a multi-process way.
Here we go
Step 1: Get all the categories' Links
from bs4 import BeautifulSoup
import requests
start_url = 'http://bj.ganji.com/wu/'
url_host = 'http://bj.ganji.com'
def get_index_url(url):
wb_data = requests.get(url)
wb_data.encoding = wb_data.apparent_encoding
soup = BeautifulSoup(wb_data.text, 'lxml')
links = soup.select('.fenlei > dt > a')
for link in links:
print(link)
page_url = url_host + link.get('href')
print(page_url)
The code is easy to implement, but need to pay attention to coding problems. So I check the Request_docs, and add wb_data.encoding things in it.
Then run this code as ** get_index_url(start_url) **. You will get all those categories' links below:

Remember to save all the links in a list named * channel_list *.
channel_list = '''
http://bj.ganji.com/jiaju/
http://bj.ganji.com/rirongbaihuo/
http://bj.ganji.com/shouji/
http://bj.ganji.com/shoujihaoma/
http://bj.ganji.com/bangong/
http://bj.ganji.com/nongyongpin/
http://bj.ganji.com/jiadian/
http://bj.ganji.com/ershoubijibendiannao/
http://bj.ganji.com/ruanjiantushu/
http://bj.ganji.com/yingyouyunfu/
http://bj.ganji.com/diannao/
http://bj.ganji.com/xianzhilipin/
http://bj.ganji.com/fushixiaobaxuemao/
http://bj.ganji.com/meironghuazhuang/
http://bj.ganji.com/shuma/
http://bj.ganji.com/laonianyongpin/
http://bj.ganji.com/xuniwupin/
http://bj.ganji.com/qitawupin/
http://bj.ganji.com/ershoufree/
http://bj.ganji.com/wupinjiaohuan/
'''
Step2: Get Links in each category
Now we are going to crawl each category's list for each page like this below:

for each item in the list, we can pick out the item link by BeautifulSoup.
def fromChannelGetLink(channel, page):
client = pymongo.MongoClient('localhost', 27017)
db = client['ganjiDB']
urlListSheet = db['urlList']
# http://gz.ganji.com/jiaju/o3/
url = channel + 'o' + str(page) + '/' # 构造指定频道的指定页面url
print(url)
try:
response = requests.get(url,headers=headers, timeout=5.0)
soup = BeautifulSoup(response.text, 'lxml')
links = soup.select('a.ft-tit')
# print(links)
if soup.find('ul', 'pageLink'):
for link in links:
link = link.get('href')
if link.find('zhuanzhuan') > 0 or link.find('click') > 0: # 筛掉一些无用链接
continue
# print(link)
urlListSheet.insert_one({'url': link})
else:
print(url + " maybe the end Page of this channel")
pass
return 1
return 0
except :
return 2
There is a problem about how to make sure wether this page is the last of this channel.
At first I try to judge it by the number of items in this page, if it's less than 5. So it maybe last page. But this way always lead to a quick end, which I don't figure out yet.
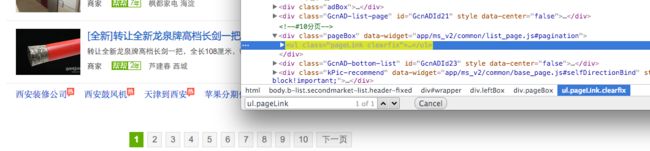
So I use another judgment statement like the code above. I search for the "* NextPage *" link in the bottom of the page, it's more obvious and accurate.
All this process should be assigned to multiple processes, it's not difficult in Python.
from tools import *
from multiprocessing import Pool
import pymongo
def getLinksFromChannel(channel):
sum = 0
pageNumber = 1
while True:
ret = fromChannelGetLink(channel, pageNumber)
if ret == 1:
break
time.sleep(0.5)
pageNumber += 1
print(channel, " 结束对此频道的爬取,结束页面为", pageNumber)
if __name__ == '__main__':
pool = Pool()
pool.map(getLinksFromChannel, channelList.split())
pool.close()
pool.join()
But there is something wrong, it's still can't reach the final page easily. I guess it's because the network in my house is week, which make the response lost. So I enhance the exit judgment condition, use the function return value.
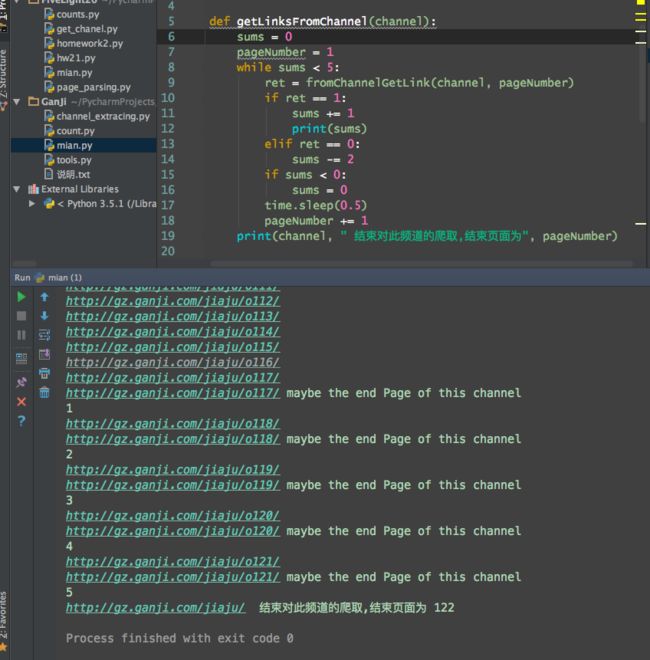
In this way, progress should make it sure for five times before it end the search in this channel. At last, I got 48419 links in all the channels.(Maybe bj.ganji.com will have more data than 50k, whatever. Q.Q)
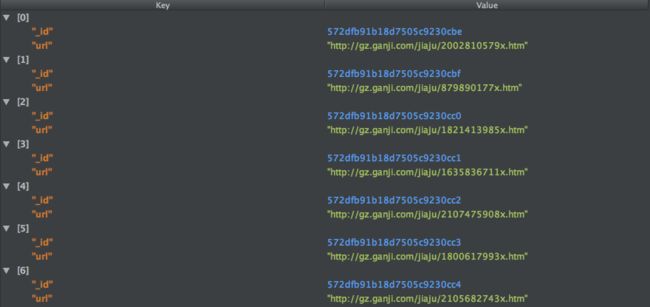
Step3: Get all Items' Infos
def getItemInfo(url):
url = url.strip()
client = pymongo.MongoClient('localhost', 27017)
db = client['ganjiDB']
itemListSheet = db['itemList']
print(url)
try:
wb_data = requests.get(url,headers=headers)
wb_data.encoding = wb_data.apparent_encoding
if wb_data.status_code == 404:
pass
print('Item is sold')
else:
soup = BeautifulSoup(wb_data.text, 'lxml')
title = soup.head.title.string
data = soup.select('i.pr-5')[0].string.strip()[:-3]
mtype = soup.select('ul.det-infor > li > span > a')[0].string
price = soup.select('i.f22.fc-orange')[0].string
location = soup.select('div.det-laybox > ul.det-infor > li')[2].get_text().replace(' ', '').replace('\n', '')
otherInfo = soup.select('ul.second-det-infor')
if otherInfo:
otherInfo = otherInfo[0].get_text().replace(' ', '').replace('\n', '')
print(title, data, mtype, price, location, otherInfo, url)
itemListSheet.insert_one({
'title': title,
'data': data,
'type': mtype,
'price': price,
'location': location,
'otherInfo': otherInfo
})
except IndexError as elist:
print(url, " list Index " , elist)
# time.sleep(1)
pass
except Exception as e:
print(url, "has Exception" , e)
There are 2 error exception in this code. I still can't understand why, maybe it's caused by the poor internet connection in this building?
Here is the main code:
if __name__ == '__main__':
client = pymongo.MongoClient('localhost',27017)
db = client['ganjiDB']
urlListSheet = db['urlList']
itemListSheet = db['itemList']
itemList = [each['url'] for each in urlListSheet.find()]
print(len(itemList))
pool = Pool()
pool.map(getItemInfo,itemList)
pool.close()
pool.join()
First I get all the links(48K) and put them in a list. Then I dispatch the list to the functional Method '* getItemInfo *'.
To Increase the Speed?
try this out:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36',
'Connection': 'keep-alive'
}
http://cn-proxy.com/
proxy_list = [ 'http://117.177.250.151:8081', 'http://111.85.219.250:3129', 'http://122.70.183.138:8118',]
proxy_ip = random.choice(proxy_list) # 随机获取代理
ipproxies = {'http': proxy_ip}
## Finally
As we are taught in the video. People is curious about how the program running.
So I made a counter here, which should be running in terminal while the Spiders are working.
import time
import pymongo
client = pymongo.MongoClient('localhost', 27017)
db = client['ganjiDB']
urlListSheet = db['urlList']
itemListSheet = db['itemList']
while True:
print('urlList Size is:', urlListSheet.find().count())
print('itemList Size is:', itemListSheet.find().count())
print('---------------------------')
time.sleep(5)
#Appendix
[MongoDB_Tutorial ( cn_Zh )](http://www.runoob.com/mongodb/mongodb-tutorial.html)
[MongoDB_CheatSheet.pdf (en)](https://blog.codecentric.de/files/2012/12/MongoDB-CheatSheet-v1_0.pdf)