在做这个任务的时候是17年的9月份,当时是在一家金融公司实习做基于大量金融数据(年报,研报)的中文实体识别任务,用的模型就是LSTM-CRF模型,这是一个比较简单经典的模型,实际上在NLP中命名实体识别(Name Entity Recognition,NER)是一个比较容易入门的研究课题,可以说做烂了,在这篇博客中,我打算做三个模型的介绍,LSTM-CRF,Lattice LSTM-CRF,Bert-NER最后一个BERT暂时只给出实践代码,在后续的内容中会详细介绍相关原理。(由于之前已经整理了相关工作,最近又有新的Paper所以就一起整理了,比较乱)
先来看一下什么是命名实体识别?
识别文本中具有特定意义的实体(人名、地名、机构名、专有名词),从知识图谱的角度来说就是从非结构化文本中获取图谱中的实体及实体属性。
方法:
- 基于规则与词典
- 基于统计机器学习
- 面向开放域
难点:
- 中文实体识别
中文识别包含英文识别;英文直译实体;
- 特定领域的数据
爱尔眼科集团股份有限公司
B-agency,I-agency,……
- 数据清洗
注意:这三个难点是我实习总结的经验,数据清洗真的很重要!很重要!很重要!
接下来我们先介绍一下经典的LSTM-CRF模型,再follow下2018年的一些成果。
1、LSTM-CRF模型

我们用一个例子来讲解,加入识别序列的label是:I-Organization 、I-Person 、O、B-Organization 、I-Person,这里推荐一个博客,原理讲的很详细。
图中输入是word embedding,使用双向lstm进行encode,对于lstm的hidden层,接入一个大小为[hidden_dim,num_label]的一个全连接层就可以得到每一个step对应的每个label的概率,也就是上图黄色框的部分,到此,如果我们直接去最大的概率值就可以完成任务了,那么为什么还要接入一个CRF层?我们先看下面这个图:
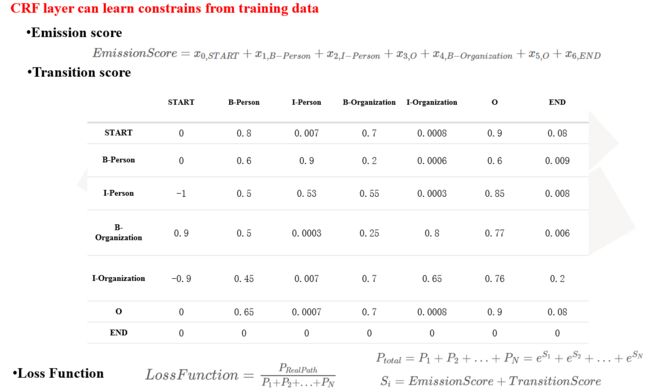
这一块关于CRF的讲解五花八门,也很抽象,上面推荐的博客也讲得很详细了,这里我给出我的直观感受:如果将lstm接全连接层的结果作为发射概率,CRF的作用就是通过统计label直接的转移概率对结果lstm的结果加以限制(这样条件随机场的叫法就很好理解了)比如I这个标签后面不能接O,B后面不能接B,如果没有CRF,光靠lstm就做不到这点,最后的score的计算就将发射概率和转移概率相加就ok了,我这里给出的是直观感受,不做理论上的讲解。
接下来我们来看一下LSTM-CRF的代码实战部分。
数据集:给出的是中文的数据集,之后的例子也都是在中文数据上完成的。
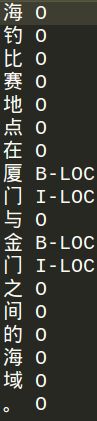
中文的NER是针对每个字进行标注的。
模型Bilstm-CRF

模型比较简单,就是这五层,先简单回顾下tensorflow的Bilstm的用法:

CRF层写在loss中,这里比较难理解,我们可以对比之后pytorch的写法:

crf_log_likelihood就是CRF层,这里的input就是lstm输出的发射概率,这里对输出的头和尾加上了一个类似
看一下实验结果:
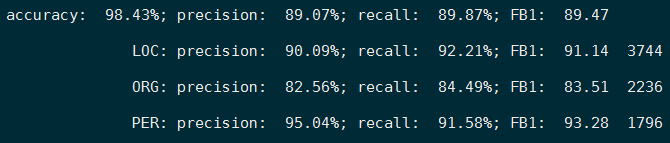
在我这个中文数据集上到第13个epoch时的F值是89.47,后面是三个label的结果(注意:光看accuracy没用,因为“O”太多)
补充:
这里就我的实习经验,对NER在知识图谱中的应用做一个补充。NER做啥事情想必大家都很清楚了,可是这玩意究竟在工业上是怎么用的呢?接下来我管中窥豹一下,分享一下我的经验:

这是一张知识图谱的图,我之前实习的任务就是从大量的数据中抽取图中的每个实体节点,如下:

当时采取的就是LSTM-CRF的算法,从效果上来看还不错,但是结果信息还是有点冗余,我猜想这和训练数据的质量还是有关的,为什么这么说呢?因为当时公司给我的原始数据噪声真的很大,数据清洗是至关重要的一步,我做了一个实验,同样的模型参数,做数据清洗后的结果不要好太多,那么究竟清洗些什么内容呢,这里做一个总结:
1.数据中句子的切割:要做成训练数据那样的标注并不容易,有些句子长度得有1000+个字了,我们尽量把句子的长度控制在100左右,同时要保证词语的完整性。
2.符号清理:这里尽量保证句子中乱七八糟的符号不要太多。
3.然后舍去全是‘O’的标注句子。其实有标注的句子占的比重不大,这里要注意清洗干净。
4.如果对数字识别不做要求,干脆转换成0进行识别
上面谈到的是数据清洗,接下来看一下整个的工作流程:

图不是很清楚,主要是太大,我简单说一下,我们有的只有未标注的数据和一些数据库中的词典,那么我们要做的就是从数据库中抽取原始数据和每个类别的词典进行标注还原。那么标注还原怎么做呢?
这里可以直接将词典导进分词器的,将类别作为词性标注的标签进行标注,这样既做了分词也做了标注。
实体识别完成后就是数据入库审核工作了,然后就是做词典更新,添加识别出的新词,继续做模型训练。