第一章 统计学习方法概论
1.1 统计学习
实现统计学习方法的步骤如下:
1)得到一个有限的训练数据集合
2)确定包含所有可能的模型的假设空间,即学习模型的集合;
3)确定模型选择的准则,即学习的策略
4)实现求解最优模型的算法,即学习的算法
5)通过学习方法选择最优模型
6)利用学习的最优模型对新数据进行预测或分析
1.2 监督学习
统计学习包括监督学习、非监督学习、半监督学习及强化学习
监督学习(supervised learning)的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做一个好的预测
1.2.1 基本概念
1)输入空间、特征空间与输出空间
监督学习从训练数据(training data)集合中学习模型,对测试数据(test data)进行预测。训练数据由输入(或特征向量)与输出对组成。、
特征空间:每个具体的输入是一个实例(instance),通常由特征向量(feature vector)表示,这时,所有特征向量存在的空间为特征空间(feature space)。特征空间的每一维对应于一个特征。有时假设输入空间与特征空间为相同的空间,对它们不予区分;有时假设是不同的空间,将实例从输入空间映射到特征空间。模型实际上都是定义在特征空间上的。
测试数据也由相应的输入与输出对组成,输入与输出对又称为样本(sample)或样本点。
在监督学习过程中,输入变量X和输出变量Y有不同的类型,可以是连续的,也可以是离散的,根据输入输出变量的不同类型,对预测任务给予不同的名称:
1.输入变量与输出变量均为连续变量的问题称为回归问题;
2.输出变量为有限个离散变量的预测问题称为分类问题;
3.输入如变量与输出变量均为变量序列的预测问题称为标注问题。
2)联合概率分布
监督学习假设输入与输出的随机变量X和Y遵循联合概率分布P(X,Y).它表示分布函数,或分布密度函数。统计学习假设数据存在一定的统计规律,X和Y具有联合概率分布的假设就是监督学习关于数据的基本假设。
3)假设空间
监督学习的目的在于学习一个由输入到输出的映射,这一映射由模型来表示。即,学习的目的就在于找到最好的这样的模型。模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间(hypothesis space).假设空间的确定一维这学习范围的确定。
监督学习的模型可以是概率模型或非概率模型,由条件概率分布P(Y|X)或决策函数(decision function)Y=f(X)表示,随具体学习方法而定,对具体的输入进行相应的输出预测时,写作P(y|x)或y=f(x).
1.2.2 问题的形式化
监督学习利用训练数据集学习一个模型,再用模型对测试样本集进行预测(prediction)。
监督学习中,依据上述基本假设
1.3 统计学习三要素
统计学习方法都是由模型、策略和算法构成的,即统计学习方法由三要素构成:
方法=模型+策略+算法
1.3.1 模型
在监督学习过程中,模型就是所要学习的条件概率分布或决策函数。模型的假设空间包含所有可能的条件概率分布或决策函数。例如,假设决策函数是输入变量的线性函数,那么模型的假设空间就是所有这些线性函数构成的函数集合。假设空间中的模型一般有无穷多个。
假设空间可以定义为决策函数的集合,也可以定义为条件概率的集合。
书中称由决策函数表示的模型为非概率模型,由条件概率表示的模型为概率模型。
1.3.2 策略
有了模型的假设空间,统计学习接着需要考虑的是按照什么样的准则学习或选择最优的模型。统计学习的目标在于从假设空间中选取最优模型。
首先引入损失函数与风险函数的概念。损失函数度量模型一次预测的好坏,风险函数度量平均意义下的模型预测的好坏。
1.损失函数和风险函数
监督学习问题中,从假设空间中选一个模型作为决策函数,对于给定的输入X,有一个对应的输出Y,这输出的预测值与真实值可能一致也可能不一致,用一个损失函数(loss function)或代价函数(cost function)来度量预测错误的程度。
统计学习常用的损失函数有以下几种
1)0-1损失函数(0-1 loss function)
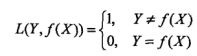
2)平方损失函数(quadratic loss function)
3)绝对损失函数(absolute loss function)
4)对数损失函数(logarithmic loss function)或对数似然损函数(log-likelihood loss function)
损失函数值越小,模型越好。由于模型的输入输出是随机变量,遵循联合分布P(X,Y),所以损失函数的期望是
这是理论上模型f(X)关于联合分布P(X|Y)的平均意义下的损失,称为风险函数(risk function)或期望损失(expected loss)。
学习的目标就是选择期望风险最小的模型。由于联合分布P(X|Y)是未知的,所以风险函数不能直接计算。这样一来,一方面根据期望风险最小学习模型要用到联合分布,另一方面联合分布又是未知的,所以监督学习就成为一个病态问题。
给定一个训练数据集,模型f(X)关于训练数据集的平均损失称为经验风险(empirical risk)或经验损失(empirical loss),记做
期望方向是模型关于联合分布的期望损失,经验风险是模型关于训练样本集的平均损失,根据大数定律,当样本容量N趋于无穷时,经验风险趋于期望风险,所以一个很自然的想法是用经验风险估计期望风险,但是,由于现实中训练样本数目有限,甚至很小,所以用经验风险估计期望分析常常并不理想,要对经验风险进行一定的矫正。这就关系到监督学习的两个基本策略:经验风险最小化和结构风险最小化。
2.经验风险最小化与结构风险最小化
在假设空间、损失函数及训练数据集确定的情况下,经验风险函数式就可以确定。经验风险最小化(empirical risk minimization,ERM)的策略任务,经验风险最小的模型就是最优的模型。根据这一策略,按照经验风险最小化求最优模型就是求解最优化问题。

当样本容量足够大时,经验风险最小化能保证有很好的学习效果,在现实中被广泛采用。比如,极大似然估计(maximum likelihood estimation)就是经验风险最小化的一个例子。当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化就等价于极大似然估计。
但是,当样本容量很小时,容易出现“过拟合(over-fitting)”现象。
结构风险最小化(structural risk minimization ,SRM)是为了防止过拟合而提出来的策略。结构风险最小化等价于正则化(regularization)。结构风险在经验风险上加上表示模型复杂度的正则化项(regularizer)或罚项(penalty term)。在假设空间、损失函数以及训练数据集确定的情况下,结构风险的定义是
其中J(f)为模型的复杂度,是定义在假设空间上的泛函。模型f越复杂,复杂度J(f)就越大;反之,模型f越简单,复杂度J(f)就越小。也就是说,复杂度表示了对复杂模型的惩罚,0是系数,用以权衡经验风险和模型复杂度。结构风险小需要经验风险与模型复杂度同时小。结构风险小的模型往往对训练数据以及未知的测试数据都有比较好的预测。
比如,贝叶斯估计中的最大后验概率估计(maximum posterior probability estimation,MAP)就是结构风险最小化的一个例子。当模型是条件概率分布、损失函数是对数损失函数。模型复杂度由模型的先验概率表示时,结构风险最小化就等价于最大后验概率估计。
结构风险最小化的策略认为结构风险最小的模型是最优的模型。所以求最优模型,就是求解最优化问题:
这样,监督学习问题,就变成了经验风险或结构风险函数的最优化问题。这时,经验或结构风险函数是最优化的目标函数。
1.3.3 算法
算法是指学习模型的具体计算方法。统计学习基于训练数据集,根据学习策略,从假设空间中,选择最优模型,最后需要考虑用什么样的计算方法求解最优模型。
这时,统计学习问题归结为最优化问题,统计学习的算法称为求解最优化问题的算法。如果最优化问题有显式的解析解,这最优化问题就比较简答。但通常解析解不存在,这就需要用数值计算的方法求解。如何保证找到全局最优解,并使求解的过程非常高效,就成为一个重要问题。统计学习可以利用已有的最优化算法,有时也需要开发独自的最优化算法。
统计学习方法之间的不同,主要来自其模型,策略、算法的不同。
1.4模型评估与模型选择
1.4.1 训练误差与测试误差
统计学习的母体是使学到的模型不仅对已知数据而且对未知数据都能有很好的预测能力。不同的学习方法会给出不同的模型。当损失函数给定时,基于损失函数的模型的训练误差(training error)和模型的测试误差(test error)就自然成为学习方法评估的标准。注意,统计学习方法具体采用的损失函数未必是评估时使用的损失函数。当然,让两者一直是比较理想的。
假设学习到的模型是Y~,训练误差是模型Y~关于训练集的平均损失:
其中N是训练样本容量。
测试误差是模型Y~关于测试数据集的平均损失:
例如,当损失函数是0-1损失时,测试误差就变成了常见的测试数据集上的误差率(error rate)
这里I是指示函数(indicator function),即yY~时为1,否则为0.
相应地,常见的测试数据集上的准确率(accuracy)为
显然,
训练误差的大小,对判断给定的问题是不是一个容易学习的问题是有意义的,但本质上不重要,测试误差反映了学习方法对未知的测试数据集的预测能力,是学习中的重要概念。显然给定两者学习方法,测试误差小的方法具有更好的预测能力,是更有效的方法,通常将学习方法对未知数据的预测能力成为泛化能力(generalization ability)。
1.4.2 过拟合与模型选择
当假设空间含有不同的复杂度(例如,不同的参数个数)的模型时,就要面临模型选择(model selection)的问题,我们希望选择或学习一个合格的模型。如果在假设空间中存在“真”模型,那么所选择的模型应该逼近真模型。具体地,所选择的模型要与真模型的参数个数相同,算选择的模型的参数向量与真模型的参数向量相近。
如果一味追求提高对训练数据的预测能力,所选模型的复杂度则往往会比真模型更高,这种现象称为过拟合。过拟合是指学习时选择的模型所包含的参数过多,以致于出现这一模型对已知数据预测的更好,但对未知数据预测的很差的现象。可以说模型选择旨在避免过拟合并提高模型的预测能力。
1.5 正则化与交叉验证
1.5.1 正则化
模型选择的典型方法是正则化(regularization)。正则化是结构风险最小化策略的实现,是在经验风险上加一根正则化项(regularizer)或罚项(penalty term)。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大,比如,正则化项可以是模型参数向量的范数。
正则化一般具有如下形式
其中,第一项是经验风险,第二项是正则化项,0为调整两者之间关系的系数。
正则化项可以取不同的形式。例如,回归问题中,损失函数是平方损失,正则化项可以是参数向量的L2范数:
这里,双竖线w表示参数向量w的L2范数,
正则化项也可以是参数向量的L1范数:
这里,双竖线w1表示参数向量w的L1范数
至于什么是范数?详情请看什么是范数
简单来说,曼哈顿距离计算是L1范数的一个例子,欧式距离计算是L2范数的一个例子
第一项的经验风险较小的模型可能较为复杂(有多个非零参数),这时,第二项的模型复杂度会比较大,正则化的作用是选择经验风险与模型复杂度同事较小的模型。
正则化符合奥卡姆剃刀(Occam's razor)原理(这个原理称为“如无必要,勿增实体” )。奥卡姆剃刀原理应用于模型选择时变为以下想法:在所有可能选择的模型中,能够很好的解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。可以假设复杂的模型有较大的先验概率,简单的模型有较小的先验概率。
1.5.2 交叉验证
另一种常用的模型选择方法是交叉验证(cross validation)。
如果给定的样本数据充足,进行模型选择的一种简单方法是随机地讲数据集切分为三部分,分别为训练集、验证集和测试集。训练集用来训练模型,验证集用于模型的选择,测试集用于最终对学习方法的评估。在学习到的不同复杂度的模型中,选择对验证集有最小误差的模型,由于验证集有足够多的数据,用它对模型进行选择也是有效的。
但是,在许多实际应用中数据是不充足的,为了选择好的模型,可以采用交叉验证方法。交叉验证的基本思想是重复的使用数据;把给定的数据进行切分,将切分的数据集组合为训练集和测试集,在此基础上反复进行训练、测试以及模型选择。
1.简单交叉验证
简单交叉验证方法是:首先随机的讲已给数据分为两部分,一部分作为训练集,另一部分作为测试集;然后用训练集在各种条件下(例如,不同的参数个数)训练模型,从而得到不同的模型;在测试集上评价各个模型的测试误差,选出测试误差最小的模型。
2.S折交叉验证
应用最多的是S折交叉验证(S-fold cross validation),方法如下:首先随机的将已给数据切分为S个互不相交的大小相同的子集;然后利用S-1个子集的数据训练模型,利用余下的子集测试模型;将这一过程对可能的S种选择重复进行,最后选出S次侧边中平均测试误差最小的模型。
3.留一交叉验证
S折交叉验证的特殊情形是S=N,称为留一交叉验证(leave-one-out cross validation),往往在数据缺乏的情况下使用,这里,N是给定数据集的容量。
1.6 泛化能力
学习方法的泛华能力(generalization ability)是指由该方法学习到的模型对未知数据的预测能力,是学习方法本质上重要的性质。现实中采用最多的办法是通过测试误差来评价学习方法的泛化能力。但这种评价是依赖于测试数据集的。因为测试数据集有限,很有可能由此得到的评价结果是不可靠的。统计学习理论试图从理论上对学习方法的泛化能力进行分析。
首先给出泛化误差的定义。如果学校一个模型f尖,那么这个模型对未知数据预测的误差即转化为泛化误差(generalization error)
泛化误差反映了学习方法的泛化能力,如果一种方法学习的模型比另一种方法学习的模型具有更小的泛化误差,那么这种方法就更有效。事实上,泛化误差就是所学习到的模型的期望风险。
1.6.2 泛化误差上界
学习方法的泛化能力分析往往是通过研究泛化误差的概率上界进行的,简称为泛化误差上界(generalization error bound)。具体来说,就是通过比较两种学习方法的泛化误差上界的大小来比较它们的优劣。泛化误差上界通常具有以下性质:他是样本容量的函数,当 样本容量增加时,泛化上界趋于0;他是假设空间容量(capacity)的函数,假设空间容量越大,模型就越难学,泛化误差上界就越大,
下面给出一个简单的泛化误差上界的例子:二分类问题的泛化误差上界。
考虑二分类问题。已知训练数据集T={(x1,y1),(x2,y2)...},它是通联合概率分布P(X,Y)独立同分布产生的,。。。。。。。。
训练误差小的模型,其泛化误差也会小。
以上只是假设空间包含有限个函数的情况下的泛化误差上界,对一般的假设空间要找到泛化误差界就没有这么简单。
1.7 生成模型与判别模型
监督学习的任务就是学习一个模型,应用这一模型,对给定的输入预测相应的输出,这个模型的一般形式为决策函数:
或者调解概率分布:
监督学习方法由可以分为生成方法(generative approach)和判别方法(discriminative approach)。所学到的模型分别称为生成模型(generative model)和判别模型(discriminative model)
生成方法由数据学习联合概率分布P(X|Y),然后求出条件概率P(Y|X)作为预测的模型,即生成模型:
这样的方法之所以称为生成方法,是因为模型表示了给定输入X产生输出Y的生成关系。典型的生成模型有:朴素贝叶斯法和隐马尔可夫模型
判别方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型,判别方法关心的是对给定的输入X,应该预测什么样的输出模型Y。典型的判别模型包括:k近邻法、感知机、决策树、逻辑斯蒂回归模型、最大熵模型、支持向量机、提升方法和条件随机场等
监督学习中,生成方法和判别方法各有优缺点,适合于不同条件下的学习问题。
生成方法的特点:生成 方法可以还原成联合概率分布P(X|Y),而判别方法则不能;生成方法的学习收敛速度更快,即当样本容量增加的时候,学到的模型可以更快地收敛于真实模型;当存在隐变量时,仍可以用生成方法学习,此时判别方法就不能用。
判别方法的特点:判别方法直接学习的是条件概率P(Y|X)或决策函数f(X),直接面对预测,往往学习的准确率更高;由于直接学习P(Y|X) 或f(X),可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
1.8 分类问题
分类是监督学习的一个核心问题,在监督学习中,当输出变量Y取有限个离散值时,预测问题便成为分类问题。这时,输入变量X可以是离散的,也可以是连续的。监督学习从数据中学习一个分类模型或分类决策函数,称为分类器(classifier)。分类器对新的输入进行输出的预测(prediction),称为分类(classification)。可能的输出称为类(class),分类的类别为多个时,称为多分类问题。本书主要讨论二分类问题。
分类问题包括学习和分类两个过程,在学习过程中,根据已知的训练数据集利用有效的学习方法学习一个分类器;在分类过程中,利用学习的分类器对新的输入实例进行分类。分类问题可用如下图描述:

评价分类器性能指标一般是分类准确率(accuracy),其定义是:对于给定的测试数据集,分类器正确分类的样本数与总样本数之比,也就是损失函数是0-1损失时测试数据集上的准确率
对于二分类问题常用的评价指标是精确率(precision)与召回率(recall)。通常以关注的类为郑磊,其他类为负类,分类器在测试数据集上的预测或正确或不正确,4种情况出现的总数分别记做:
TP——将正类预测为正类数;
FN——将正类预测为负类数;
FP——将负类预测为正类数;
TN——将负类预测为负类数;
精确率定义为

召回率定义为
此外,还有F1值,是精确率和召回率的调和均值,即

精确率和召回率都高时,F1值也会高。
许多统计学习方法可以用于分类,包括k近邻法、感知机、朴素贝叶斯法、决策树、决策列表、逻辑斯蒂回归、支持向量机、提升方法、贝叶斯网络、神经网络、Winnow等。
分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用。
1.9 标注问题
标注(tagging)也是一个监督学习问题,可以认为标注问题是分类问题的一个推广,标注问题又是更为复杂的结构预测(structure prediction)问题的简单形式。标注问题的输入是一个观测序列,输出是一个标记序列或状态序列。标注问题的目标在于学习一个模型,使它能够对观测序列给出标记序列作为预测。注意,可能标记个数是有限的,但其组合所成的标记序列的个数是依序列长度呈指数级增长的。
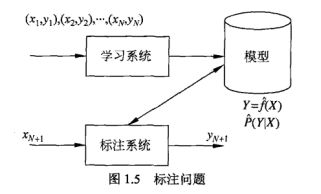
评价标注模型的指标与评价分类模型的指标一样,常用的有标注准确率、精确率和召回率。其定义与分类模型相同。
标注常用的统计学习方法有:隐马尔可夫模型、条件随机场。
标注问题在信息抽取、自然语言处理等领域被广泛应用,是这些领域的基本问题。
1.10 回归问题
回归(regression)是监督学习的另一个重要问题。回归用于预测输入变量(自变量)和输出变量(因变量)之间的关系,特别是当输入变量的值发生变化时,输出变量的值随之发生变化。回归问题正是表示从输入变量到输出变量之间映射的函数。回归问题的学习等价于函数拟合:选择一条函数曲线使其很好拟合已知数据并且很好地预知未知数据。
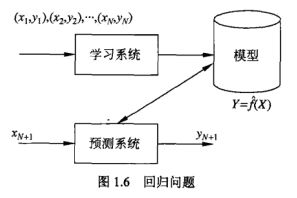
回归问题安装输入变量的个数,分为一元回归和多元回归;按照输入变量和输出变量之间关系的类型即模型的类型,分为线性回归和非线性回归。
回归学习最常用的损失函数是平方损失函数,在此情况下,回归问题可用有著名的最小二乘法(least squares)求解。
许多领域的任务都可以形式化为回归问题,比如,回归可以用于商务领域,作为市场趋势预测、产品质量管理、客户满意度调查、投资风险分析的工具。
有的部分是部分摘录,有的是全部摘录,在此做记录是为了看书的时候一边看一边写会能集中点注意力,有的例子直接看了,没在这里写,只当做自己的学习记录。