前面说的是ner的经典算法以及今年的一些比较好的工作,最近bert模型刷新了NLP的绝大部分任务,可谓是一夜之间火爆了整个NLP界,这里我简单记录下bert在NER上的使用,至于原理部分我后续的博客会做详细的说明。这里先暂时理解成bert同样也是产生embedding的工具就可以,只不过这个embedding比Word2vec的embedding要厉害。
ok 我们先设定下框架。
框架很简单,就是bert+Bilstm-CRF,前面讲了bert就是用来产生词向量的,所以如果抛开这个原理,这个升级版本的NER模型就很简单了。
这里先给出代码链接。BERT是Google提出的基于tensorflow1.11.0的代码,里面用了高级API,所以这篇博客我主要在代码层面讲一下bert的应用。原理部分我也做了详细的介绍,请戳。
bert的官方版本tensorflow和pytorch版本。
bert官方版本的代码写的非常好(虽然很难懂哈),这里借NER这个应用简单学习下:
1.数据准备
这里还是以中文数据为例,数据的格式还是和之前一样:
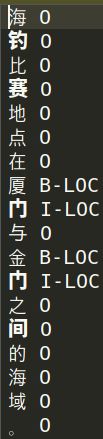
我们最终需要把数据转换成bert论文中的形式:
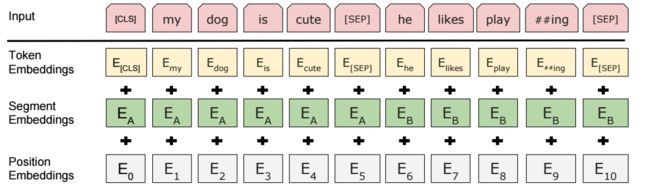
代码中的数据就是转成这样,这部分是纯工程问题,就不详细介绍 :
接下来就讲一下这个高级API的用法:
1.代码中将所有数据封装成record的形式:
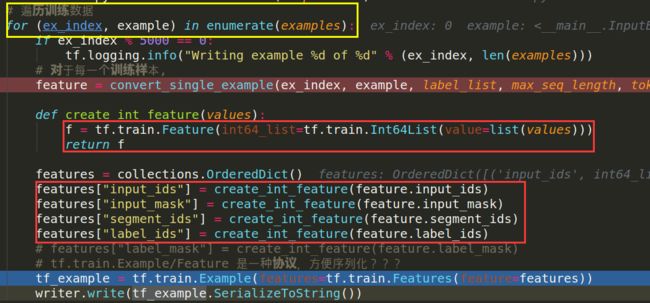
注意这里是对每一组数据进行逐条封装
2.读取record 数据,组成batch
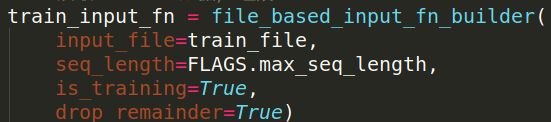
这里主要也是通过回调函数完成
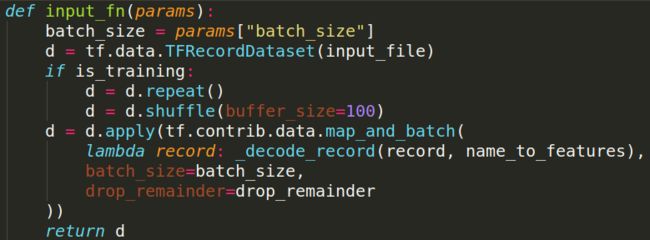
input_file就是保存的record文件,然后用d = tf.data.TFRecordDataset(input_file)读数据,这样就得到了一个batch的数据。
然后定义estimator封装器
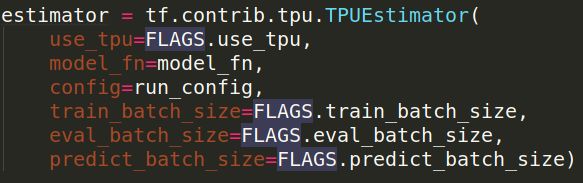
有了这个封装器训练、验证测试都比较方便(难得读懂哟),这里的model_fn就是模型定义的的回调函数。
3.定义模型
大致思路:这个model_fn_builder是为了构造代码中默认调用的model_fn函数服务的,为了使用其他的参数,只不过model_fn函数的默认参数只有features, labels, mode, params,这四个,所以在model_fn包裹了一层model_fn_builder
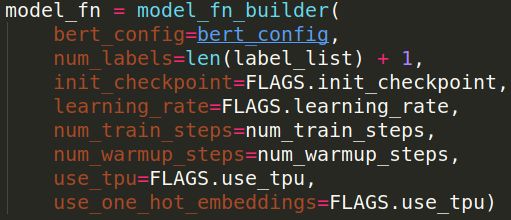
注意这个init_checkpoint就是下载的模型,接下来我们看一下模型的构造即model_fn函数,以及他是如何使用init_checkpoint:
- 在这个回调函数中,第一步就是创建模型,这一步其实和之前的tensorflow的写法思路一样,都是在完成“图”这个部分,

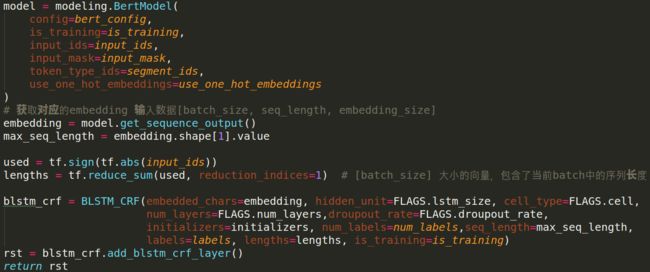
那么creat_model里有啥呢,不看也知道,第一步就是拿到bert的输出了,也就是embedding = model.get_sequence_output(),后面就是在创造blstm_crf这块就不再讲了,到这儿是不是完了呢,显然不是,因为我们只是把图建完了,bert的预训练的参数还没有喂给模型呢,接下来就是create_model后面一部分,加载模型预训练参数:
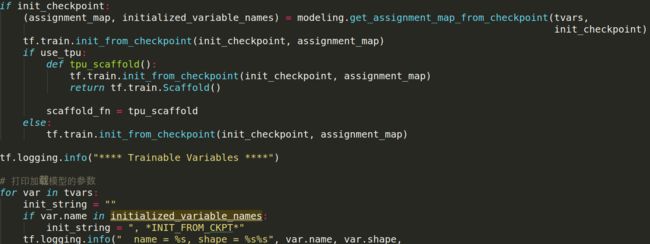
首先读取在create_model中的所有需要训练的参数,因为init_checkpoint中的参数对应的是bert的,所以要把训练参数分开,只能初始化bert的部分,同时bert论文中也提到了fine-tune,是不是这样,我们把参数打印出来看看就知道了:
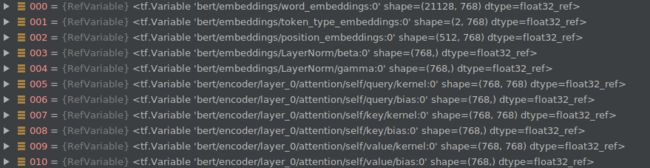
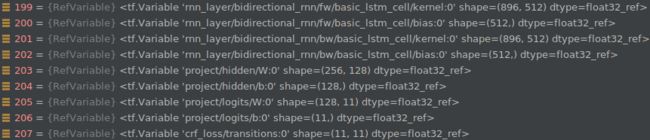
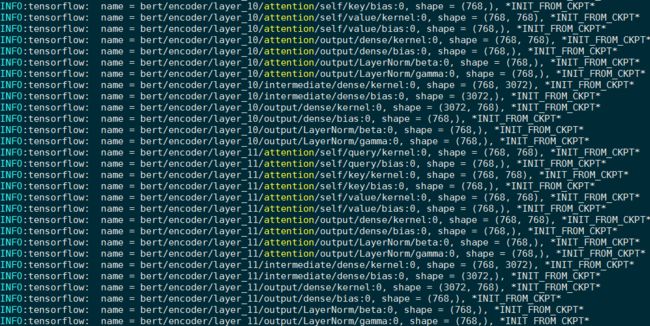
assignment_map是一个字典,里面存的就是需要create_model中需要初始化的变量,也就是bert的部分,然后调用tf.train.init_from_checkpoint(init_checkpoint, assignment_map)来加载模型,看看恢复出来的参数:
最后就是优化器的定义了:
实验结果:红框是总的实验精度,黄框是每个类别的结果
梳理完了代码,现在来总结下这个estimator API是怎么用的(看一堆基础教程,真不如看大牛写的代码来的快哈!)
1.首先把数据存成record
2.创建estimator 对象,对象里要传入创建model的回调函数model_fn
model_fn的用法:
- 参数model_fn(features, labels, mode, params) 这个是固定的,如果需要额外参数就在外面在包一层回调函数
- features就是record解析后的结果
- 调用数据并送入创建的模型

3.创建优化器并使用tf.contrib.tpu.TPUEstimatorSpec封装优化器和loss
4.创建读取record并生成batch的回调函数

5.训练模型
上述仅仅只是一个代码的分析,详细使用请看我的github吧!!!