1.前言
既然有爬虫的存在那就有反爬虫技术的存在,验证码是常见手段,不过最近发现不少网站使用极限验证码。对于普通验证码如何识别的问题,在我倒腾了一晚上如何安装pytesseract-ocr之后,我终于还是放弃倒腾这玩意。在windows上编译python库就是个坑,而且还是个深坑。目前的想法是通过学习tensorflow来破解,目前阶段只学了一个入门教程。
极限验证码采用拖动图片来进行验证,这个验证方式初看起来确实让机器识别确实很难,而且也能防止人工打码。据说还带有行为识别功能,反正具体怎么实现的,我也没看js代码,还有我讨厌括号,js里面到处是括号。网上也有一些文章谈到如何破解的问题,但是有些含糊其辞。既然别人能破,那我行不行,怎么滴也得试试。
2.分析
什么也不要谈先F12再说,很容易就能找到滑块。
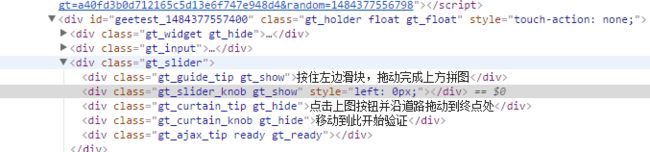
当鼠标放到滑块上时显示的是一张图片:

当在滑块上按下鼠标显示另一张图片:

这两张图片有一些差异,那是不是可以根据这个差异来找到拼图的缺口?只要找到了缺口的边界,那就可以通过selenium模拟鼠标移动。
- 要找到这两张图片:
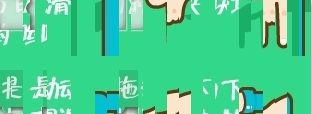
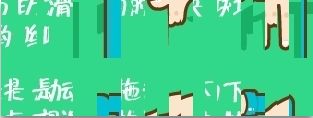
上面两张图片显然有问题,被打乱了。
- 重新编排图片
从源代码中找到如下代码:
 Paste_Image.png
Paste_Image.png
注意background-position,这里面有几十个div背景图都是一张图片,只是位置不同。每个div宽度是10px,高度是58px,总数量是52个,最后拼成的图片是260X116px。查找另外一幅图也是这样的设置。根据```background-position``来重新绘制这两幅图片,然后进行比较找出缺口位置。这里还注意一个细节问题,打乱的原图宽度是312,拼接后的图片宽度只有260,也就是每个小切片丢失了2px。
3.安装环境
python的版本是3.5,Chrome版本是57
- 安装selenium
pip3 install selenium
- 安装geckodriver-v0.13.0-win64
配合firefox下载地址
解压到某个目录之后,将该目录设置到系统路径PATH中。 - 安装Chromedriver 3.27
下载地址
解压到某个目录之后,将该目录设置到系统路径PATH中。
实际上我并未使用Firefox,原因就是moveto这个指令系统报错,具体是Firefox的问题还是geckodriver的问题没有搞明白。还有这个webdriver之间是有些差异的,而且这种差异还不小。选择selenium+chromedriver的组合花了一整晚的时间,也曾考虑过phantomjs。
4.实现
- 获取图片路径
from selenium import webdriver
import re
url = 'https://user.geetest.com/login'
driver = webdriver.Chrome()
driver.get(url)
bg_slice = driver.find_element_by_class_name('gt_cut_bg_slice')
#background-image: url("https://static.geetest.com/pictures/gt/d0fe39770/bg/b03de89e.webp"); background-position: -157px -58px;
pattern = re.compile(r'"(.+)"')
bgurl = pattern.findall(bg_slice.get_attribute('style'))[0]
#https://static.geetest.com/pictures/gt/d0fe39770/bg/b03de89e.webp
- 下载图片
图片的下载使用的是requests模块:
def downloadimage( image_url):
dir_path = 'D:/imgs'
if not os.path.exists(dir_path):
os.makedirs(dir_path)
us = image_url[image_url.rfind('/'):]
image_file_path = dir_path + us
with open(image_file_path, 'wb') as handle:
response = requests.get(image_url, stream=True)
for block in response.iter_content(1024):
if not block:
break
handle.write(block)
return image_file_path
- 获取图片偏移坐标
获取background-position与上面获取图片类似:
es = driver.find_elements_by_class_name('gt_cut_bg_slice')
#这个代码与上面的类似,但是elements这个加了复数,它会获取一组元素并且返回一个列表
ss = [e.get_attribute('style') for e in es]
pattern = re.compile(r'([-0-9]+)px')
xys =[pattern.findall(s) for s in ss]
# [['-157', '-58'], ['-145', '-58'], ['-265', '-58'], ['-277', '-58'], ['-181', '-58'], ['-169', '-58'], ['-241', '-58'],
# ['-253', '-58'], ['-109', '-58'], ['-97', '-58'], ['-289', '-58'], ['-301', '-58'], ['-85', '-58'], ['-73', '-58'],
#['-25', '-58'], ['-37', '-58'], ['-13', '-58'], ['-1', '-58'], ['-121', '-58'], ['-133', '-58'], ['-61', '-58'],
#['-49', '-58'], ['-217', '-58'], ['-229', '-58'],['-205', '-58'], ['-193', '-58'], ['-145', '0'], ['-157', '0'],
#['-277', '0'], ['-265', '0'], ['-169', '0'], ['-181', '0'],['-253', '0'],['-241', '0'],['-97', '0'], ['-109', '0'],
#['-301', '0'], ['-289', '0'], ['-73', '0'], ['-85', '0'], ['-37', '0'], ['-25', '0'], ['-1', '0'], ['-13', '0'],
#['-133', '0'], ['-121', '0'], ['-49', '0'], ['-61', '0'], ['-229', '0'], ['-217', '0'], ['-193', '0'], ['-205', '0']]
#把上面的数据转化为整数就可以了
经过对比两幅图片偏移是一样的,所以这里就省略对另一幅图的获取。
- 图片重排列
from PIL import Image
def realign(imgpath):
x1 = [157,145,265,277,181,169,241,253,109,97,289,301,85,73,25,37,13,1,121,133,61,49,217,229,205,193]
x2 = [145,157,277,265,169,181,253,241,97,109,301,289,73,85,37,25,1,13,133,121,49,61,229,217,193,205]
i = 0
#这些数字实际上没有使用上面的方法获取,我直接从HTML中抄的
im = Image.open(imgpath)
nim = Image.new('RGB',(260,116))
#新建一个图形文件
for x in x1:
box = (x,58,x+10,116)
pastebox = (i,0,i+10,58)
imx = im.crop(box)
#先抠图,再粘贴到新图中
nim.paste(imx,pastebox)
i = i +10
i = 0
#图片的编排分上下两部分
for x in x2:
box = (x,0,x+10,58)
pastebox = (i,58,i+10,116)
imx = im.crop(box)
nim.paste(imx,pastebox)
i = i +10
return nim
- 图形对比查找缺口位置
def iseq(p1,p2,diff = 70):
p1 = sum(p1)
p2 = sum(p2)
if abs(p1-p2)上面的判断一个像素点是不是相等,采用非常简单的策略,RGB之和进行比较。为了调试这里特别设置了一个diff,通过调整这个参数来控制误判。查找到缺口之后,还要减去一个差值,滑块不在图片的最左端,经过测试7是个合适的数值。
- 移动滑块
操作步骤就是点击滑块不松,然后移动,释放左键:
from selenium.webdriver.common.action_chains import ActionChains
slider = driver.find_element_by_class_name('gt_slider_knob')
(x,y) = getpos(driver,diff)
actions = ActionChains(driver)
actions.click_and_hold(slider).perform()#按住滑块
end = x-7
for i in range(end):
actions.move_by_offset(1,0).perform()#移动
time.sleep(0.1)
actions.release().perform()#释放鼠标
上面的代码确实按照步骤来实现的,可惜这代码有问题。这个问题出现在ActionChains,perform()执行之后并不会清空以前的命令,例如上一次移动了1px,如果下次再移动1px,实际上却执行的是2px。
下面的代码只能部分正确,所谓部分正确就是能滑块能正确移动到缺口处,但是却不会判定为正确。
def move(driver):
(x,y) = f.getpos(driver,120)
slider = driver.find_element_by_class_name('gt_slider_knob')
actions = ActionChains(driver)
actions.click_and_hold(slider).perform()
end = x-7
print(x)
p = getint(end)
print(p)
for i in p:
actions = ActionChains(driver)
actions.move_by_offset(i,int(math.sin(i)*10)).perform()
time.sleep(0.05+0.1*abs(math.sin(i)))
actions = ActionChains(driver)
actions.release().perform()
time.sleep(0.1)
actions = ActionChains(driver)
actions.move_by_offset(0,200).perform()
def getint(a):
p = []
while sum(p)- 路径规划
关于路径的问题一晚上都没解决,这个问题就是前面提到的行为判断。那如何安排路径才能让机器移动的路径表现得像人的行为一样,最好的办法就是直接记录自己拖动滑块的轨迹。
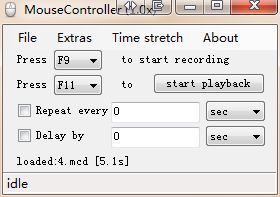
鼠标放在滑块上,按F9,按下鼠标左键拖动滑块,直到滑块拖不动释放左键,按F9停止记录。
上面的数据pos中的x,y代表坐标,tOfffset代表时间。这是个xml文件,需要用lxml来解析这三个数据。这里要提到一个事情就是,需要清理掉xmlns这些属性,还要把a:这个前缀去掉。使用sublime能批量替换掉这些不要的元素。因为有这些内容之后,lxml解析存在一些问题,比如用//x无法匹配到数据。
>>> doc = etree.parse('C:/6.xml')
>>> xs = doc.xpath('//x/text()')
>>> len(xs)
205
>>> ys = doc.xpath('//y/text()')
>>> ts = doc.xpath('//tOffset/text()')
>>> xs = [int(x) for x in xs]
>>> ys = [int(y) for y in ys]
>>> ts = [int(t) for t in ts]
上面获取的坐标值是绝对值,这里需要的是相对值,也就是每一步走了多少。
#计算差值
def calcdelta(xx):
ret = []
for i in range(len(xx)-1):
delta = xx[i+1]-xx[i]
ret.append(delta)
return ret
时间是微秒,这么大得数应该是微秒:
ts = [t/1000000 for t in ts]
其实滑块移动只是水平方向,我已经获取到整个从左到右的路径。也就是不管缺口在哪,我只需要从xs中累积到缺口位置值,就可以获取路径。
#x代表上面的xs,target是目标点
def getpath(x,target):
ret = []
for i in x:
if sum(ret)根据上面的分析和实现,整个移动过程实现如下:
def stepto(driver,xs,ys,ts,diff=100):
(x,y) = getpos(driver,diff)
slider = driver.find_element_by_class_name('gt_slider_knob')
actions = ActionChains(driver)
actions.click_and_hold(slider).perform()
end = x-7
i = 0
time.sleep(ts[i])
print(x)
path = getpath(xs,end)
print(path)
for j in range(len(path)):
i = i+1
actions = ActionChains(driver)
actions.move_by_offset(path[j],ys[j]).perform()
time.sleep(ts[i])
i = i+1
actions = ActionChains(driver)
actions.release().perform()
time.sleep(ts[i])
actions = ActionChains(driver)
actions.move_by_offset(200,200).perform()
5.存在问题
查找缺口点存在问题,需要提高抗干扰能力。还有如果缺口向左突出,这个查找可能有问题。
6.相关资料
selenium手册
PIL手册