本章节主要是了解R中的多种数学、统计和字符处理函数;如何自己编写函数来完成数据处理和分析任务;数据的整合和概述方法以及数据集的重塑和重构方法。
5.1 一个数据处理难题
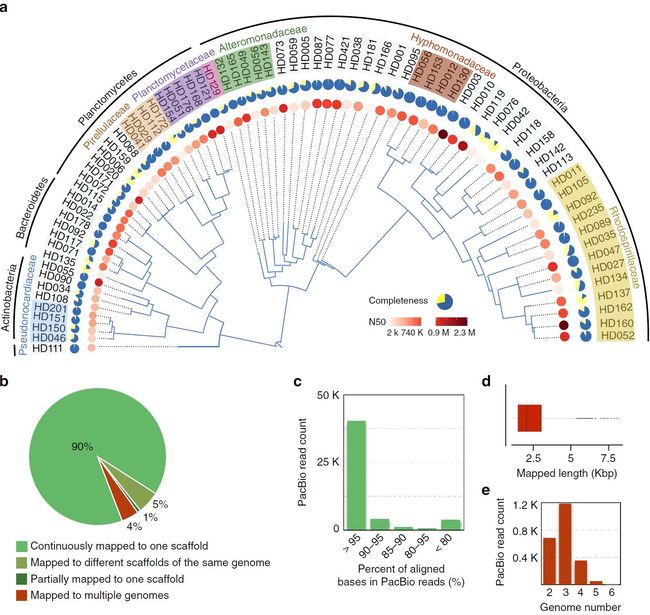
在这个数据处理例子中,各科考试成绩没法直接比较,排序也困难等其他实际问题。但可以利用R中的数值和字符处理函数来完成。
#先将数据导入到R语言
Student <- c("John Davis","Angela Williams","Bullwinkle Moose",
"David Jones","Janice Markhammer",
"Cheryl Cushing","Reuven Ytzrhak",
"Greg Knox","Joel England","Mary Rayburn")
math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
english <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18)
roster <- data.frame(Student, math, science, english,
stringsAsFactors=FALSE)
5.2 数值和字符处理函数
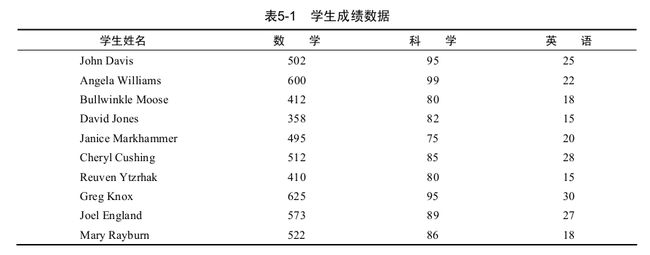
5.2.1 数学函数

5.2.2 统计函数

数据的标准化:默认情况下,函数
scale()对矩阵或数据框的指定列进行均值为0、标准差为1的标准化:newdata <- scale(mydata)。如果要对每一列进行任意均值和标准差的标准化,newdata <- scale(mydata)*SD+M。此外,要对指定列进行标准化,可以使用如下的代码进行:
newdata <- transform(mydata, myvar = scale(myvar)*10+50)。
5.2.3 概率函数
- 设定随机数种子
可以通过函数set.seed()显示指定这个种子,让结果可以重现。函数runif()用来生成0-1区间上服从均匀分布的伪随机数。通过手动设定种子,结果可以重现,否则每次运行都会产生不同的伪随机数。 - 生成多元正态数据
在模拟研究和蒙特卡洛方法中,你经常需要获取来自给定均值向量和协方差阵的多元正太分布的数据。MASS包中mvrnorm(n, mean, sigma)可以很容易产生这样的数据。(n是样本的大小,mean是均值向量,sigma是方差-协方差矩阵),例如:

mean <- c(230.7, 146.7, 3.6)
sigma <- matrix( c(15360.8, 6721.2, -47.1,
6721.2, 4700.9, -16.5,
-47.1, -16.5, 0.3), nrow=3, ncol=3)
set.seed(1234)
mydata <- mvrnorm(500, mean, sigma)
mydata <- as.data.frame(mydata)
names(mydata) <- c("y", "x1", "x2")
dim(mydata)
head(mydata, n=10)
5.2.4 字符处理函数
可以从文本型数据中抽取信息,或者为打印输出和生成报告重设文本的格式。
函数grep(), sub()和strsplit()能够搜索某个文本字符串(fixed=TRUE)或某个正则表达(fixed=FALSE,默认值为FALSE)。


5.2.5 其他使用函数


5.2.6 将函数应用于矩阵和数据框
R函数的特性之一,就是他们可以应用到一系列的数据对象上,包括标量、向量、矩阵、数组和数据框的任何维度上。
a <- 5
sqrt(a)
b <- c(1.243, 5.654, 2.99)
round(b)
c <- matrix(runif(12), nrow=3)
c
log(c)
mean(c)
apply()函数,可将一个任意函数应用到矩阵、数组、数据框的任何维度上。使用格式:apply(x, MARGIN, FUN, ...),x为数据对象,MARGIN是维度的下标,FUN是由你指定的函数,而...则包括了任何想传递给FUN的参数。在矩阵或数据框中,MARGIN=1表示行,MARGIN=2表示列。
mydata <- matrix(rnorm(30), nrow=6)
mydata
apply(mydata, 1, mean)
apply(mydata, 2, mean)
apply(mydata, 2, mean, trim=.4)
5.3 数据处理难题的一套解决方案
# 限定了输出小数点后数字的位数
options(digits=2)
# 构建数据框
Student <- c("John Davis", "Angela Williams", "Bullwinkle Moose",
"David Jones", "Janice Markhammer", "Cheryl Cushing",
"Reuven Ytzrhak", "Greg Knox", "Joel England",
"Mary Rayburn")
Math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
Science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
English <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18)
roster <- data.frame(Student, Math, Science, English,
stringsAsFactors=FALSE)
# 将每科考试成绩用单位标准差来表示,而不是以原始的尺度来表示。
z <- scale(roster[,2:4])
# 并将z来计算各行的均值以获得综合得分
score <- apply(z, 1, mean)
# 使用cbind函数将score添加到数据框中
roster <- cbind(roster, score)
# 使用quantile函数将score分为5个部分
y <- quantile(roster$score, c(.8,.6,.4,.2))
# 通过使用逻辑运算符,可以将百分数排名重编码为一个新的成绩变量grade,分为5个等级A、B、C、D、F
roster$grade[score >= y[1]] <- "A"
roster$grade[score < y[1] & score >= y[2]] <- "B"
roster$grade[score < y[2] & score >= y[3]] <- "C"
roster$grade[score < y[3] & score >= y[4]] <- "D"
roster$grade[score < y[4]] <- "F"
# 使用函数strsplit()以空格为界,将学生的姓名拆分开。
name <- strsplit((roster$Student), " ")
# 使用函数sapply()提取列表中每个成分的第一个和第二个分别放入两个向量中。“[” 是一个可以提取某个对象的一部分函数
Lastname <- sapply(name, "[", 2)
Firstname <- sapply(name, "[", 1)
roster <- cbind(Firstname,Lastname, roster[,-1])
# 重新排列顺序
roster <- roster[order(Lastname,Firstname),]
5.4 控制流
- 语句(statement):是一条单独的R语言或一组符合语句(包含在花括号中的一组R语句,使用分好分隔);
- 条件(cond):是一条最终被解析为真(TRUE)或假(FALSE)的表达式;
- 表达式(expr):是一条数值或字符串的求值语句;
- 序列(seq):是一个数值或字符串序列。
- 重复和循环
- for 结构:重复地执行一个语句,直到某个变量的值不再包含在序列seq中为止。语法:
for (var in seq)statement。 - while 循环重复地执行一个语句,直到条件不为真为止。语法为:
while (cond)statement。while结构可能很危险,一旦cond条件一直不变为真,那么就无线循环。
处理大数据集中的行和列时,R中的循环可能效率比较低。只要可能,最好联用R中的内建数值/字符处理函数和apply()族函数。
- 条件执行:在条件执行结构中,一条或一组语句仅在满足一个指定条件时执行。包括if-else、ifelse和switch。
- if-else结构:控制结构if-else在某个给定条件为真时执行语句。也可以同时在条件为假时执行另外的语句。语法:
if(cond) statement或if (cond) statement1 else statement2。 - ifelse结构:是if-else结构比较紧凑的向量化版本。语法:
ifelse(cond, statement1, statement2)。 - switch结构:是一个根据表达式的值选择语句执行的循环结构。
语法:switch(expr, ...),其中的...表示与expr的各种可能输出值绑定的语句。下面的例子很好的阐释了switch的主要功能。
feelings <- c("sad", "afraid")
for (i in feelings)
print(
switch(i,
happy = "I am glad you are happy",
afraid = "There is nothing to fear",
sad = "Cheer up",
angry = "Calm down now"
)
)
5.5 用户自编函数
一个函数的结构看起来大致如此:
myfunction <- function(arg1, arg2, ...){
statements
return(object)
}
函数中的对象只在函数内部使用。返回对象的数据类型是任意的,从标量到列表都可以。
5.6 整合与重构
- 转置:是重塑数据集的总舵方法中最简单的一个,使用函数
t()即可对一个矩阵或数据框进行转置。对于后者,行名将成为变量。 - 整合数据:在R中使用一个或多个by变量和一个预先预定好的函数来折叠数据是比较容易的。格式:
aggregate(x, by, FUN),x是待折叠的数据对象,by是一个变量名组成的列表,FUN是用来计算描述性统计量的标量函数,将被用来计算新观测中的值。 - reshape2 包:是一套重构和整合数据集的绝对的万能工具。大致就是先将数据融合(melt),以使每一行都是唯一的标识符-变量组合。然后将数据重铸(cast)为你想要的任何形状。
- 融合数据:
md <- melt(mydata, id = c("ID", "Time"))
必须指定要唯一确定每个测量所需的变量(ID和Time),而表示测量变量名的变量由程序自动创建
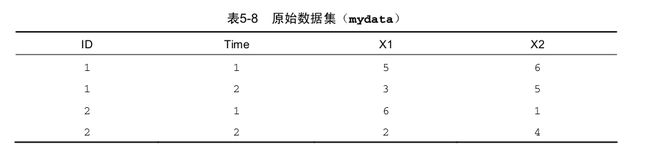
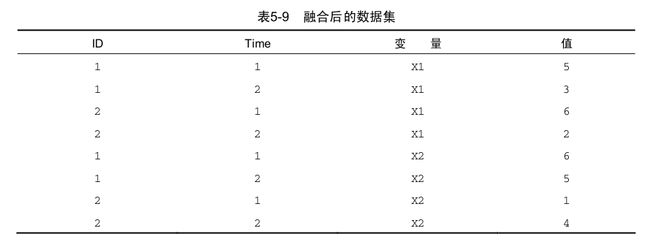
- 重铸 :
dcast()函数读取已融合的数据,并使用你提供的公式和一个(可选的)用于整合数据的函数将其重塑。
格式:newdata <- dcast(md, formula, fun.aggregate),md为已经融合数据,formula描述了想要的结果,而最后的参数是数据整合函数。
PS:国庆也结束了,终于将第一部分入门的知识学习了一遍。明天或许要下个礼拜才能够进入下一部分的学习,进入基础部分。