Kafka Raft知识整理
背景
Kafka2.8 之后,移除了Zookeeper,而使用了自己研发的Kafka Raft。
为什么移除Zookeeper?
原来Zookeeper在Kafka中承担了Controller选举、Broker注册、TopicPartition注册和选举、Consumer/Producer元数据管理和负载均衡等。
即承担了各种元数据的保存和各种选举。
而Zookeeper并“不快”,集群规模大了之后,很容易成为集群的性能瓶颈。
Kafka作为一个消息中间件,还依赖额外的一个协调系统,而不能实现自我管理,说不过去~无法做到开箱即用,还得要求使用者掌握Zookeeper的调优知识。
到了2.8版本,Kafka移除了Zookeeper,使用自己的Kafka Raft(KRaft),这名字,一眼就能看出来是基于Raft算法实现的。
Raft算法
Raft是一种共识算法,即在分布式系统中,所有节点对同一份数据的认知能够达成一致。
算法主要做两件事情:
分解问题,将复杂的分布式共识问题拆分为: 领导选举、日志复制、安全性。
压缩状态空间,相对于Paxos算法而言施加了更合理的限制,减少因为系统状态过多而产生的不确定性。
复制状态机
在共识算法中,所有服务器节点都会包含一个有限状态自动机,名为复制状态机(replicated state machine)。
每个节点都维护着一个复制日志(replicated logs)的队列,复制状态机会按序输入并执行该队列中的请求,执行状态转换并输出结果。
可见,如果能保证各个节点中日志的一致性,那么所有节点状态机的状态转换和输出也就都一致。
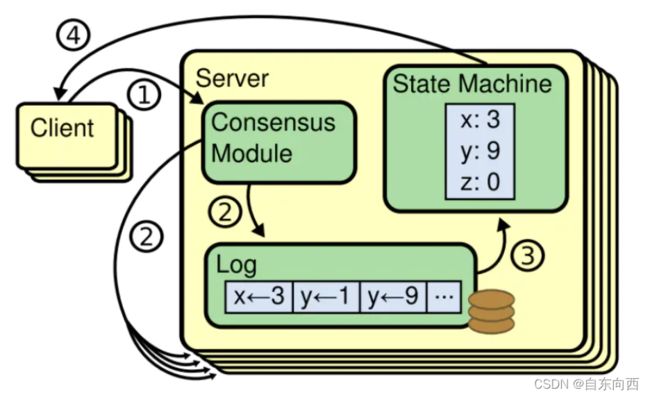
基本流程为:
- 某个节点的共识模块(包含共识算法的实现)从客户端接收请求。
- 该共识模块将请求写入自身的日志队列,并与其他节点的共识模块交流,保证每个节点日志都相同。
- 复制状态机处理日志中的请求。
- 将输出结果返回给客户端。
领导选举
节点状态与转移规则
在Raft集群中,任意节点同一时刻只能处于领导者(leader)、跟随者(follower)、候选者(candidate)三种状态之一。下图示出节点状态的转移规则。
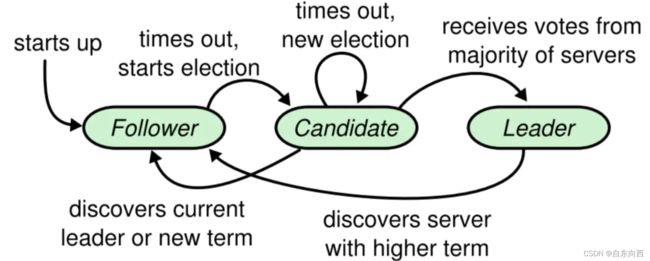
所有节点,一开始角色都是follower,当发现没有leader的时候,就会把自己的角色切换为candidate,发起选举。
得到半数节点投票的,会成为leader。
如果follower或者当前leader发现变更了leader,就会主动退出follow状态。
当leader故障或断开连接,follower就会重新切换为candidate,发起新一轮的选举。
只有leader节点能管理日志的复制,即leader接受客户端的请求,再复制到follower节点。
领导任期
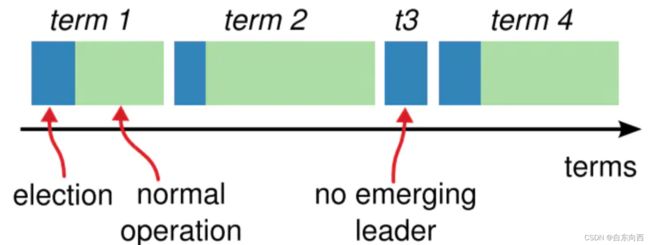
上图中,蓝色表示选举时间段,绿色表示选举出的领导者在位的时间段,这两者合起来即称作一个任期(term),其计数值是自增的。
任期的值就可以在逻辑上充当时间戳,每个节点都会保存一份自己所见的最新任期值,称为currentTerm。
选举流程
如果一个或多个follower节点在选举超时(election timeout)内没有收到leader节点的心跳(一个名为AppendEntries的RPC消息,本意是做日志复制用途,但此时不携带日志数据),就会发起选举流程: